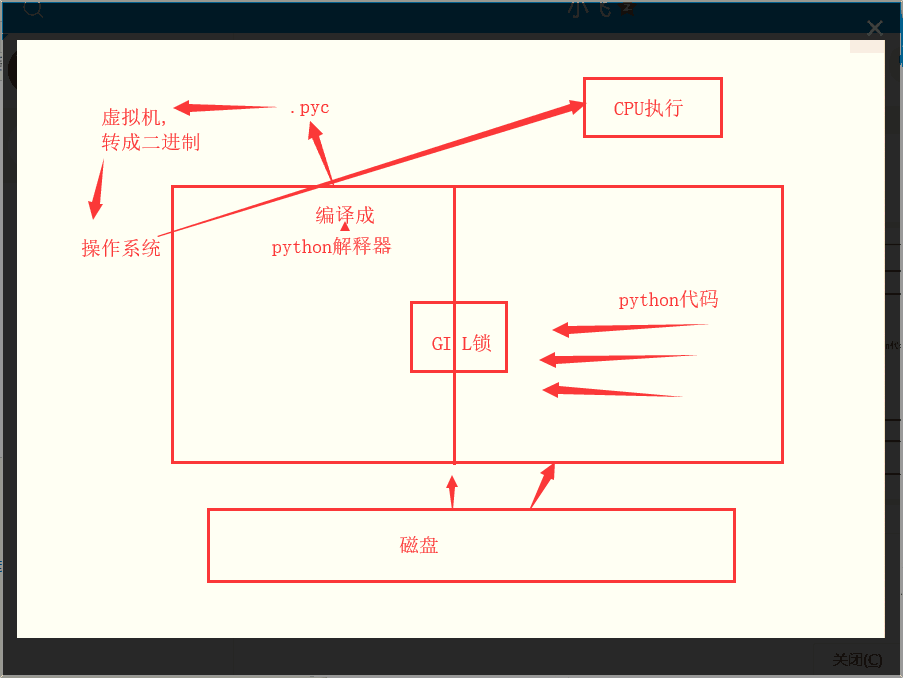
一. GIL锁
GIL锁(Global Interpreter Lock),本质就是一把互斥锁
二. 线程队列
queue队列: 使用import queue ,用法与进程Queue一样,队列都是安全的,不会出现多个线程
抢占同一个资源或数据的情况.


1 import queue 2 3 # # 先进先出 4 q = queue.Queue(3) 5 q.put(1) 6 q.put(13) 7 q.put(2) 8 while 1: 9 try: 10 print(q.get_nowait()) 11 except: 12 break 13 ''' 14 结果: 15 1 16 13 17 2 18 '''
1 import queue 2 # 后进先出 3 q = queue.LifoQueue(3) 4 q.put((2,222)) 5 q.put((1,111)) 6 q.put((3,333)) 7 print(q.get()) 8 print(q.get()) 9 print(q.get()) 10 ''' 11 结果: 12 (3, 333) 13 (1, 111) 14 (2, 222) 15 '''
1 import queue 2 # 排序 ASCII 码排序 3 q = queue.PriorityQueue(3) 4 q.put(333) 5 q.put(222) 6 q.put(111) 7 print(q.get()) 8 print(q.get()) 9 print(q.get()) 10 print(q.get()) 11 ''' 12 结果: 13 111 14 222 15 333 16 '''
三. 线程池
concurrent.futures模块 使用threadPoolExecutor 和ProcessPoolExecutor的方式一样,
concurrent.futures模块提供了高度封装的异步调用接口 ThreadPoolExecutor:线程池,提供异步调用 ProcessPoolExecutor: 进程池,提供异步调用 Both implement the same interface, which is defined by the abstract Executor class. #2 基本方法 #submit(fn, *args, **kwargs) 异步提交任务 #map(func, *iterables, timeout=None, chunksize=1) 取代for循环submit的操作 #shutdown(wait=True) 相当于进程池的pool.close()+pool.join()操作 wait=True,等待池内所有任务执行完毕回收完资源后才继续 wait=False,立即返回,并不会等待池内的任务执行完毕 但不管wait参数为何值,整个程序都会等到所有任务执行完毕 submit和map必须在shutdown之前 #result(timeout=None) 取得结果 #add_done_callback(fn) 回调函数
1 import time 2 import os 3 import threading 4 from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor 5 6 def func(n): 7 time.sleep(2) 8 print('%s打印的:'%(threading.get_ident()),n) 9 return n*n 10 tpool = ThreadPoolExecutor(max_workers=5) #默认一般起线程的数据不超过CPU个数*5 11 # tpool = ProcessPoolExecutor(max_workers=5) #进程池的使用只需要将上面的ThreadPoolExecutor改为ProcessPoolExecutor就行了,其他都不用改 12 #异步执行 13 t_lst = [] 14 for i in range(5): 15 t = tpool.submit(func,i) #提交执行函数,返回一个结果对象,i作为任务函数的参数 def submit(self, fn, *args, **kwargs): 可以传任意形式的参数 16 t_lst.append(t) # 17 # print(t.result()) 18 #这个返回的结果对象t,不能直接去拿结果,不然又变成串行了,可以理解为拿到一个号码,等所有线程的结果都出来之后,我们再去通过结果对象t获取结果 19 tpool.shutdown() #起到原来的close阻止新任务进来 + join的作用,等待所有的线程执行完毕 20 print('主线程') 21 for ti in t_lst: 22 print('>>>>',ti.result()) 23 24 # 我们还可以不用shutdown(),用下面这种方式 25 # while 1: 26 # for n,ti in enumerate(t_lst): 27 # print('>>>>', ti.result(),n) 28 # time.sleep(2) #每个两秒去去一次结果,哪个有结果了,就可以取出哪一个,想表达的意思就是说不用等到所有的结果都出来再去取,可以轮询着去取结果,因为你的任务需要执行的时间很长,那么你需要等很久才能拿到结果,通过这样的方式可以将快速出来的结果先拿出来。如果有的结果对象里面还没有执行结果,那么你什么也取不到,这一点要注意,不是空的,是什么也取不到,那怎么判断我已经取出了哪一个的结果,可以通过枚举enumerate来搞,记录你是哪一个位置的结果对象的结果已经被取过了,取过的就不再取了 29 30 #结果分析: 打印的结果是没有顺序的,因为到了func函数中的sleep的时候线程会切换,谁先打印就没准儿了,但是最后的我们通过结果对象取结果的时候拿到的是有序的,因为我们主线程进行for循环的时候,我们是按顺序将结果对象添加到列表中的。 31 # 37220打印的: 0 32 # 32292打印的: 4 33 # 33444打印的: 1 34 # 30068打印的: 2 35 # 29884打印的: 3 36 # 主线程 37 # >>>> 0 38 # >>>> 1 39 # >>>> 4 40 # >>>> 9 41 # >>>> 16
ProcessPoolExecutor的使用:
只需要将这一行代码改为下面这一行就可以了,其他的代码都不用变 tpool = ThreadPoolExecutor(max_workers=5) #默认一般起线程的数据不超过CPU个数*5 # tpool = ProcessPoolExecutor(max_workers=5) 你就会发现为什么将线程池和进程池都放到这一个模块里面了,用法一样
map的使用
1 import time 2 from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor 3 from multiprocessing import Pool 4 5 def fun(n): 6 time.sleep(1) 7 print(n) 8 return n**2 9 if __name__ == '__main__': 10 t_p = ThreadPoolExecutor(4) 11 # t_p = ProcessPoolExecutor(4) 12 p_pool = Pool(4) 13 res_lst = [] 14 15 # res = t_p.map(fun ,range(10)) 16 # 17 # print(res) 18 # t_p.shutdown() 19 # print('主线程结束') 20 # for i in res: 21 # print(i) 22 # ------------------------------------/ 23 # for i in range(10): 24 # res = t_p.submit(fun,i) 25 # res_lst.append(res) 26 # t_p.shutdown() 27 # 28 # for i in res_lst: 29 # print(i.result()) 30 # --------------------------------------- 31 # for i in range(10): 32 # res = p_pool.apply_async(fun,(i,)) 33 # res_lst.append(res) 34 # print(res.get()) 35 # p_pool.close() 36 # p_pool.join() 37 # for i in res_lst: 38 # print(i.get())
四. 线程池的回调函数
1 import time 2 from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor 3 from multiprocessing import Pool 4 5 def fun(n): 6 time.sleep(1) 7 return n*n 8 def call_bcak(m): 9 print('结果为: %s' %m.result()) 10 11 def c_back(m): 12 print('结果为: %s' %m) 13 if __name__ == '__main__': 14 p = Pool(4) 15 16 # t_p = ThreadPoolExecutor(4) 17 # lst = [] 18 # for i in range(10): 19 # res = t_p.submit(fun,i) 20 # lst.append(res) 21 # t_p.shutdown() 22 # for i in lst: 23 # i.add_done_callback(call_bcak) 24 # ----------------------------------------------------- 25 # lst = [] 26 # for i in range(10): 27 # res = p.apply_async(fun,args=(i,),callback=c_back) 28 # # print(res.get()) 29 # p.close() 30 # p.join()