简介:这篇文章属于跨域无监督行人再识别,不同于大部分文章它使用了属性标注。旨在于能够学习到有属性语义与有区分力的身份特征的表达空间(TJ-AIDL),并能够转移到一个没有看到过的域。
贡献:
- 提出了一个联合属性与身份的异质多任务无监督行人重识别深度模型
- 从有标注的源域图片中同时学习全局的身份信息与局部的属性信息,并通过一个身份推断属性(IIA)空间来最大化学习的有效性
- 提出一个属性一致框架来在无标注的目标域上进行无监督的自适应
之前工作存在的问题:
Re-ID: 依赖手工特征;缺乏有效域适应能力;单独利用身份与属性标注信息忽略了它们的联系与互补性
Re-ID的属性:语义协作表达对身份识别来说没有卷积特征向量有效,因为:属性协助表达通常是低维的,所以区分力不够;在标注数据比较稀疏而且行人图片质量不高时,一次预测出所有属性比较困难。
TJ-AIDL的特殊性:
- 不同于身份标签,属性检测是一个多标签识别问题,因为一个行人照片会同时对应几个标注
- 身份与属性监督对应了不同级别的约束:许多属性都是对应了某一个图片区域而身份标签则对应整张图片,所以两者结合在一起能够学习到一个更加全面的表达空间
方法:
整体的模型框架图如下所示,使用一个多分支的网络结构来进行有监督的异质多任务学习。上面的身份分支来在源域中提取Re-ID的敏感信息;下面的属性分支来从属性标签提取语义信息;后面的身份推断空间IIA使得这两种信息和谐地融合在一起。在测试时,选择训练好的属性分支来提取特征表达进行检索。整个网络的训练分为两步,一是在有标注的源域数据上进行监督训练,二是在无标注的目标域上进行域适应。
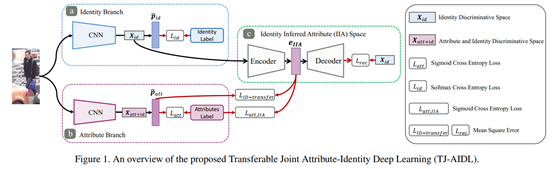
一:源域数据上的监督训练
首先介绍第一步,就是在源域数据上进行监督训练,这里的CNN用的是轻量化的MobileNet,身份分支(a)的监督损失如下,是一个常见的交叉熵损失:
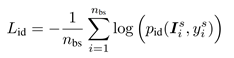
下面的属性分支(b)的监督损失其实就是如下的BCELoss,因为属性预测是一个多label的问题。
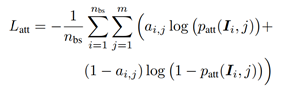
现在这两者之间是独立的,一般的做法是建立一个多任务联合学习框架在这两个约束下映射到一个共享的特征空间。但是这篇文章提出了一个更加高效的多源信息融合框架,与之前方法的准确率对比如下:

这一框架就是身份推断属性空间(c),简称为IIA.它使用的自动编码机结构,理由如下:(1)自动编码机能够在给定的目标任务下提取输入数据的重要信息并通过一个简洁的特征向量表示出来;(2)这样的一个简洁的特征表达能够简化任务间的信息传递,同时为每个单独任务的学习保留自由的更新空间。
使用身份分支a的特征向量作为IIA的输入与重建输出的真值,首先是一个IIA的均方误差重建损失:

通过上面这个损失我们得到了eIIA,它是重要身份信息的编码,使用它在分支间传递信息。向属性分支的传递也使用的是均方误差:
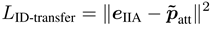
因为eIIA是使用一个无监督方式得到的,它可能偏离了对应的属性预测,比较难以对齐,所以给eIIA加了属性预测。
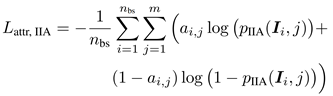
与IIA有关的损失就是将这三者加起来:
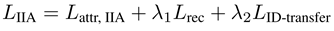
IIA对身份分支的影响:无影响,因为IIA采用的输入就是身份分支得到的特征表达,所以得到的eIIA不需要对身份分支特征进行约束
IIA对属性分支的影响:加了一个eIIA与属性向量的均方误差约束,所以属性有关的约束变成了:
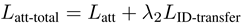
二:无监督的目标域适应
这里的跨域是基于属性一致性原则。这基于一个观察,也就是训练好的TJ-AIDL模型在两个不同的属性视角有着更小的差异。如下所示:
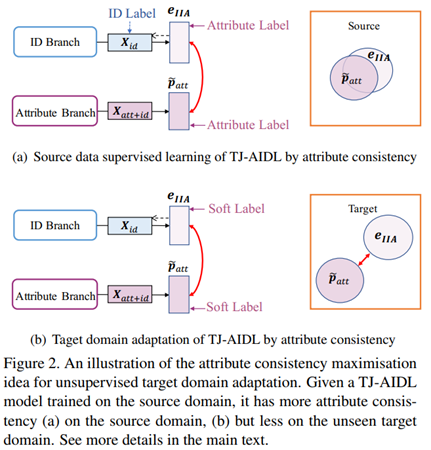
然后这篇文章就使用这两者之间的差异来显示模型在给定域上是否契合。
因为在测试时使用的是属性分支,所以目标是对属性分支进行适应而不用去管身份分支的更新。更新算法如下:
- 将源域上训练好的TJ-AIDL模型放到无标注的目标域来从属性分支得到属性预测patt,t
- 之后使用得到的软标签patt,t来作为伪标签来更新属性分支和IIA来减小域间的属性差异。直觉上,软标签保留了从源域获得的最具区分力的属性能够防止模型过度漂移。
- 在目标域上进行适应直到模型收敛。
整体算法如下:
