说到数据库,大家第一反映就是表格,2维的表格,一个维度代表属性,一个维度代表对象。
某某对象的某某属性是多少多少。2维表格大概就是这样描述数据和存放数据的。
不过,其实生活中,很多事物的相互联系并非是 2维的,更多的阶层形状的。
一个世界里面有很多国家,一个国家下面有很多省,每个省下面可能有市,也可能没有[直辖市]。
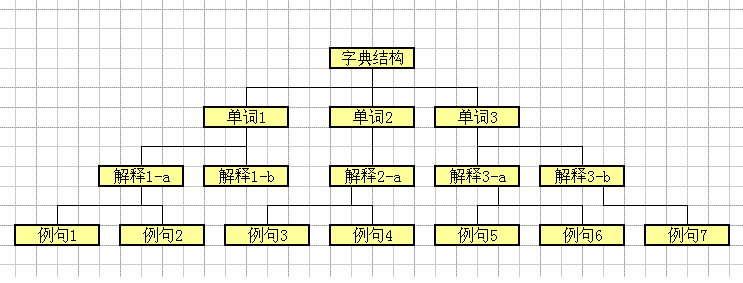
其实,字典这样的东西,就是一个典型的阶层数据。
每个词汇就是一个顶层对象,平假名,片假名,罗马字是属性,
第二层是中文解释,一个词语可能有若干个中文解释。
第三层是例句,每个例句有日语例句和中文解释两个成员。
[当然这个只是最简单的字典模型,没有考虑到各种扩展情况。]
老实说,如果数据不多的话,这样的东西,最好放到XML里面,然后用那个LQ来做。那样子的话,效率应该是最高的。
同时,XML里面的数据可读性也非常好,它如实的还原了真实领域数据的相互关系,而不是靠数据库的外键来维持这种一对多的关系。特别是在数据库出现局部逻辑错误[不是指2进制层面的物理损坏]的时候,阶层数据库影响非常小。(关系数据库把一个对象放在不同的分散的表格里面,一个地方出问题了,可能影响到所有的其他表格,阶层性的话,一个对象的所有东西都放在一起,高度内聚,要出问题也就只出现在自己这里)。
一直在做OS390上的大型机开发,IBM有一套IMSDB的数据库系统,那个就是传说中的DB2的前辈,它是阶层数据库,不过它只是用在大型机上面(就是那种大的柜子里面的家伙)。可惜,Windows平台对于大数据,好像没有什么阶层数据库的解决方案。(DB2-最新版本貌似有,不过。。。个人网站。。。。,或者那位大哥知道阶层结构的平民数据库)没有办法,老老实实做成多个数据库,用主键,外键链接起来吧。。。
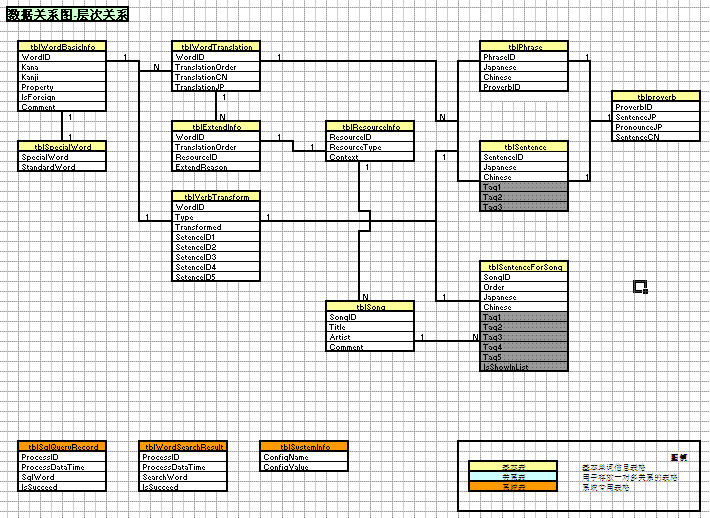
【上图是项目第一阶段的数据库关系图,手工绘制的。。。。】
大家是怎么看待阶层结构数据库的呢,对于大规模的阶层数据库有什么好的解决方式吗?请大家畅所欲言啊。
有兴趣的写信给我 root#magicdict.com [convert # to @ ]
或者加MSN mynightelfplayer@hotmail.com