一 基础回顾

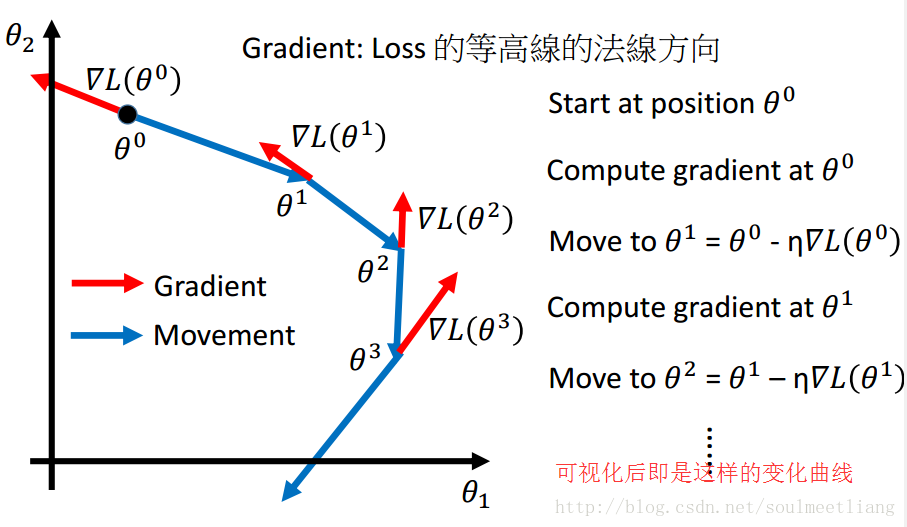
二 梯度下降的三个小贴士
2.1 tuning your learning rate
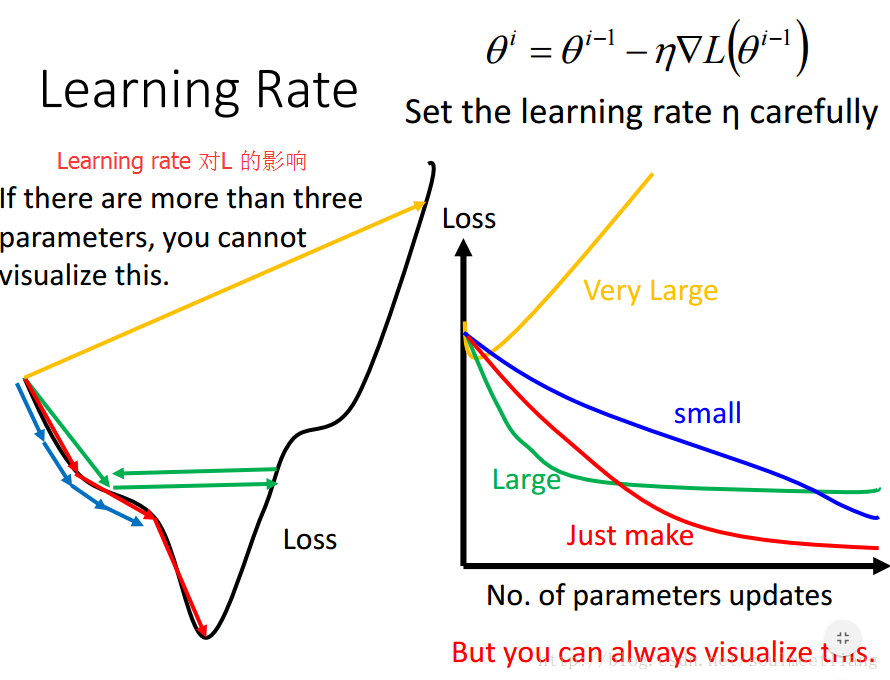
(1) 最流行也是最简单的做法就是:在每一轮都通过一些因子来减小learning rate。
- 最开始时,我们距离最低点很远,所以我们用较大的步长。
- 经过几轮后,我们接近了最低点,所以我们减少learning rate。
- 比如: 1/t 衰减ηn=ηt+1
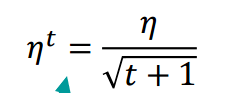
(2) learning rate 不能从一而终。
- 要给不同的参数设置不同的learning rate。
为了达到此目的,有许多种技巧,而Adagrad就是一种不错的选择。

这样操作后,每组参数的learning rate 都不同。
举个例子:
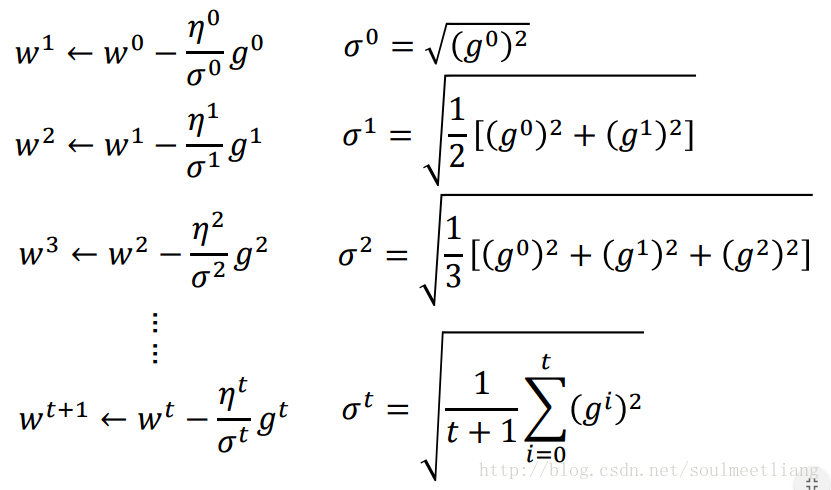
所以用Adagrad后,我们的参数变化要写成这样:
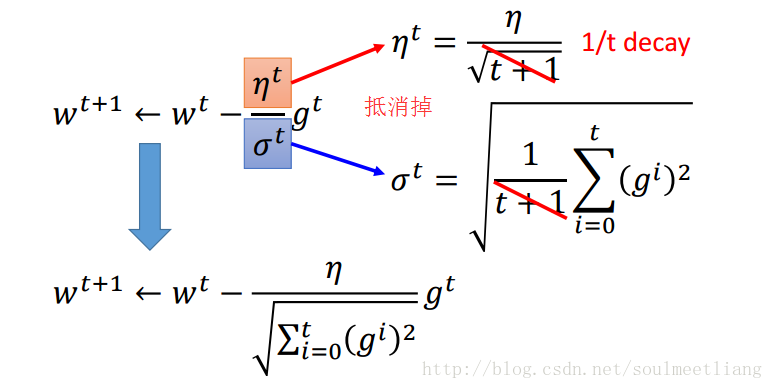
Adagrad越到后面改变会越慢,这是一个正常现象。
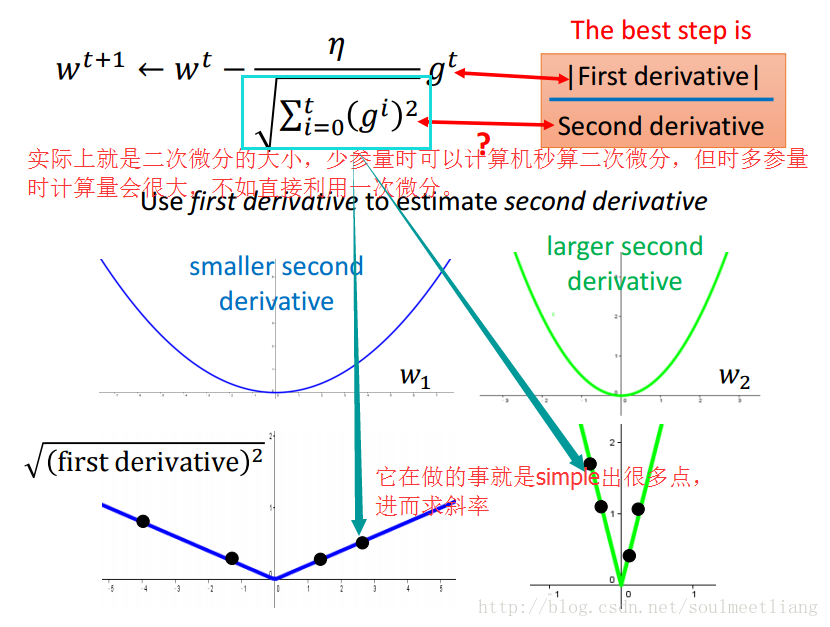
那么我们从该表达式中有没有发现奇怪的地方??或者是否有所冲突??
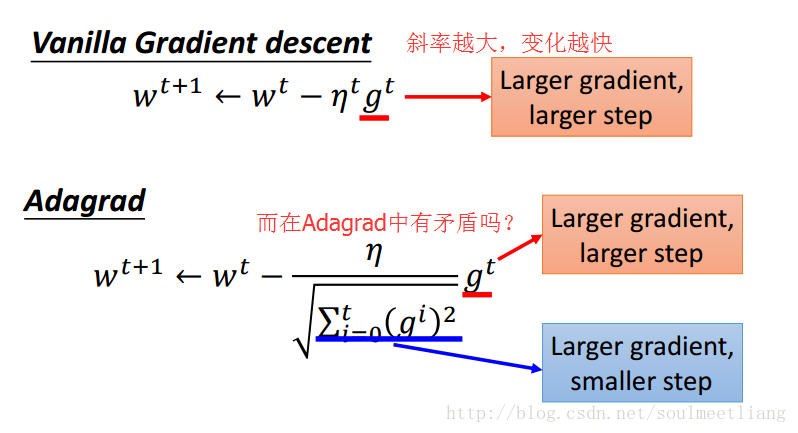
直观解释

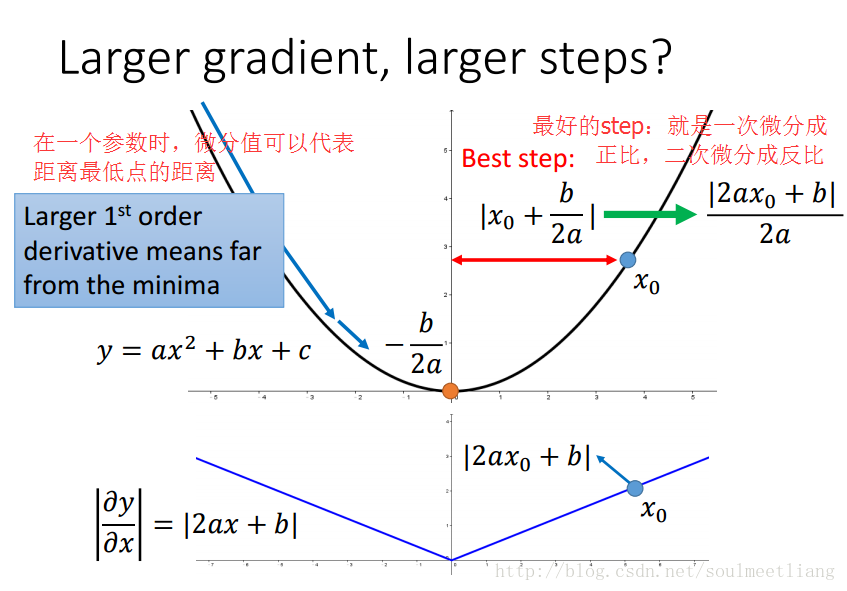
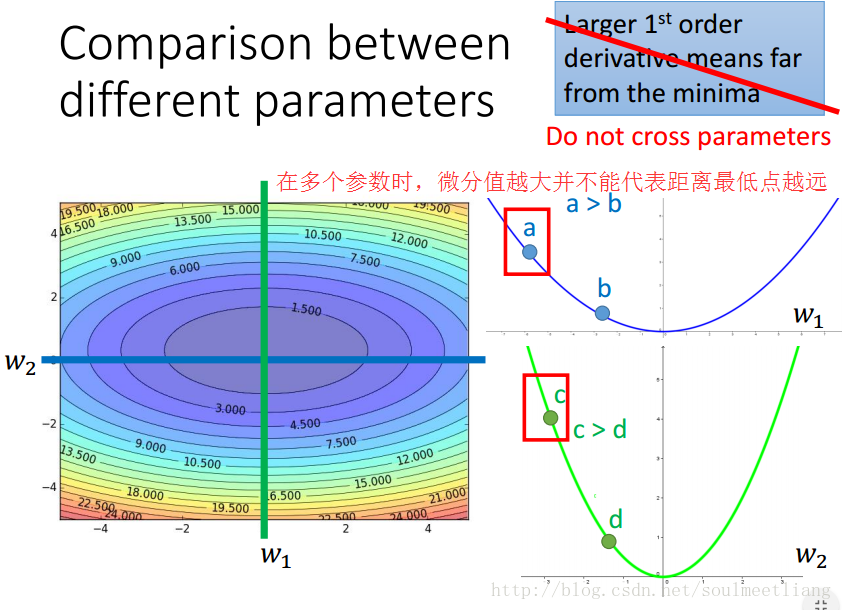
更容易让人信服的解释
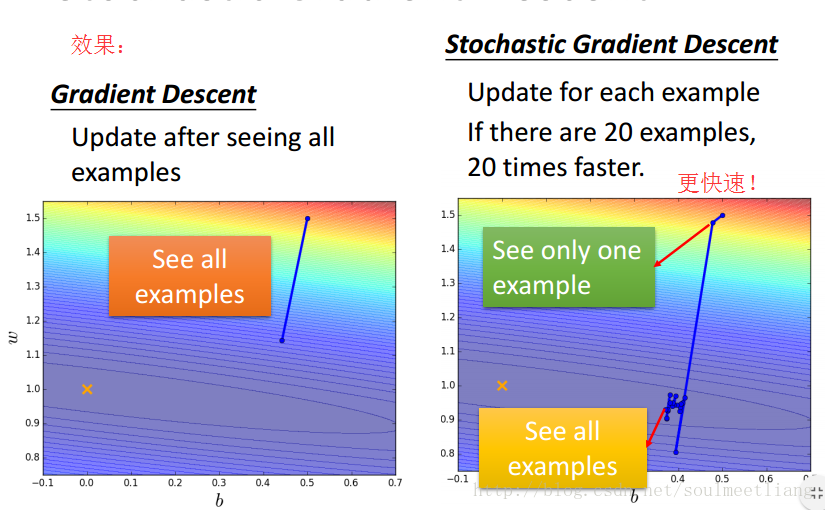
2.2 Stochastic Gradient Descent
随机梯度下降法让你的training更快一些。

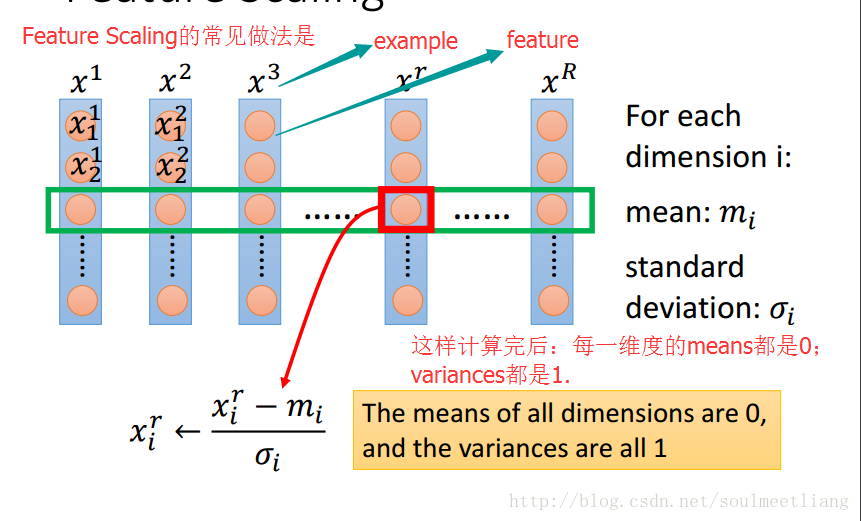
2.3 Feature Scaling
让不同的特征值具有相同的缩放程度。
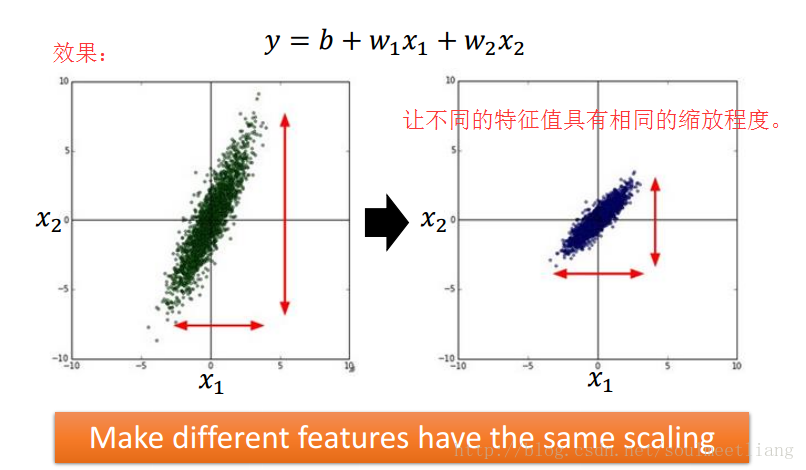
举例:
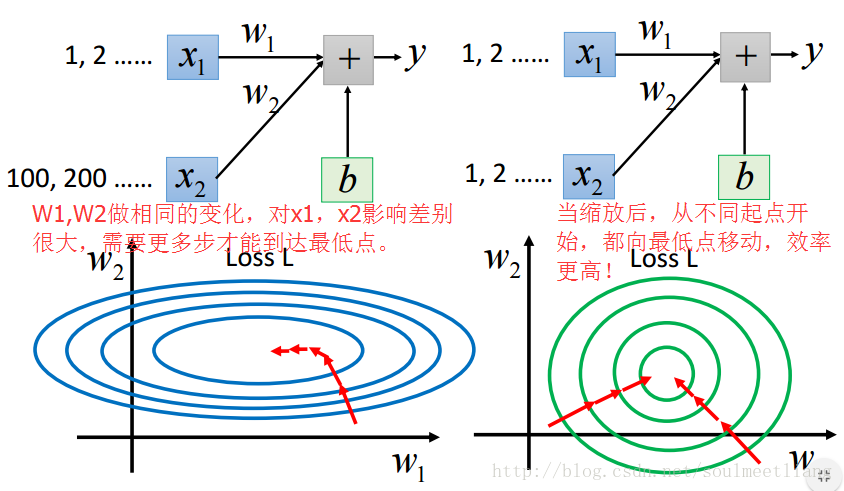
常见的 Feature Scaling
参考:https://blog.csdn.net/soulmeetliang/article/details/72830179