标签个数没有限制
数据是以二进制存储在Hbase (hbase 更像是一个数据管理系统,数据存储在HDFS中 ,这一点与DB2 和 oracle 类似 ,关系数据库 数据存储在磁盘上)中,
所以在通过java API操作Hbase时候,需要通过.getBytes() 转化成字节码形式
单元格 Cell 是基本存储单元 ,一行数据 是有 一个cell 加上一个rowkey 加上 timestamp 组成的 ,这迫使设计人员用简单,短小的rowkey 来节省存储空间。
同时 rowkey 上应该承载一些重要的业务信息 。
Example :
scan 'tablename'
1531187321_20161230224431 column=cfOne:addr, timestamp=1466343766398, value=Shanghai
1531187321_20161230224431 column=cfOne:phone, timestamp=1466343766398, value=153765324169
1531187321_20161230224431 column=cfOne:time, timestamp=1466343766398, value=218
1531187321_20161230224431 column=cfOne:type, timestamp=1466343766398, value=1
Hbase 思想是 ?
百度百科 似乎解释的还不错
Hbase 不支持join
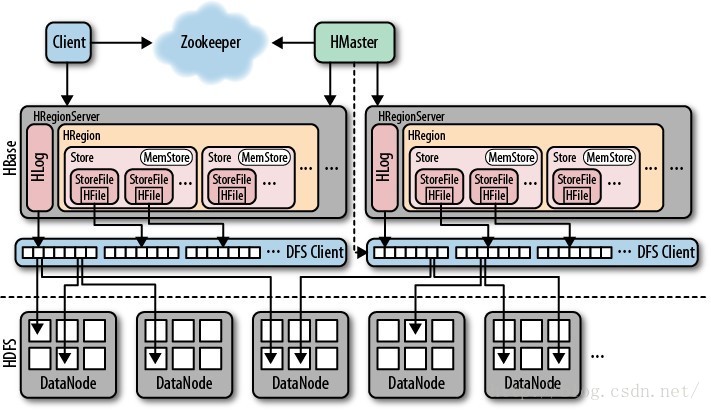
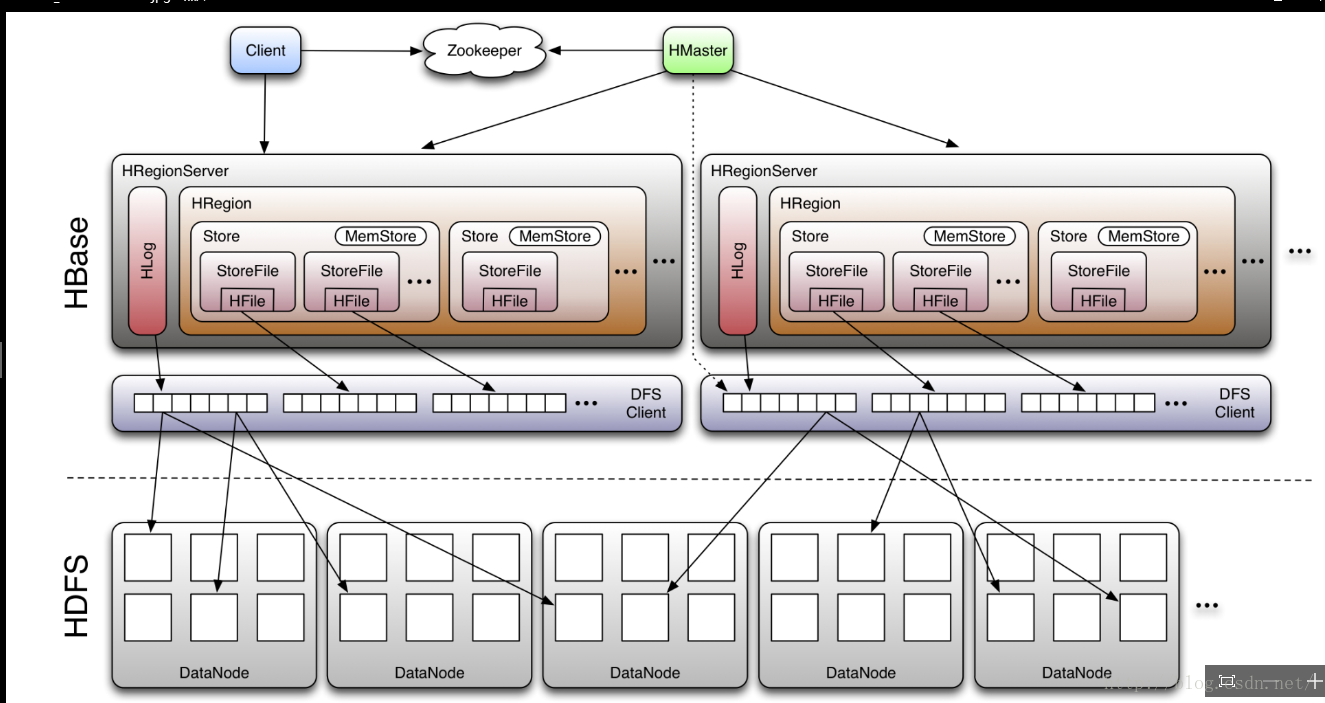
Hbase 简介
Hbase --hadoop database 是一个高可靠性 高性能 面向列 可伸缩 实时读写的 分布式数据库
利用Hadoop hdfs 作为其文件存储系统,利用 MapReduce 处理Hbase 中的海量数据 ,利用zookeeper 作为分布式协同服务
主要用来存储非结构化 半结构松散数据
Zookeeper
保证任何时候 集群中只有一个Master
存储所有Region 的寻址入口
实时监控Region server 的上线和下线信息 ,并实时通知Master
存储Hbase的schema 和 table 元 数据
Master
为Region server 分配 region
负责region server 的负载均衡
为失效的region server 重新分配其上的 region
管理用户对table 的ddl dml 操作
Regionserver
维护 region 处理这些region 上的IO请求
负责切分在运行过程中变大的region