1、古诗文网直接登录时,用浏览器F12抓取登录接口的入参,我们可以看到框起来的key对应的value是动态参数生成的,需获取到;
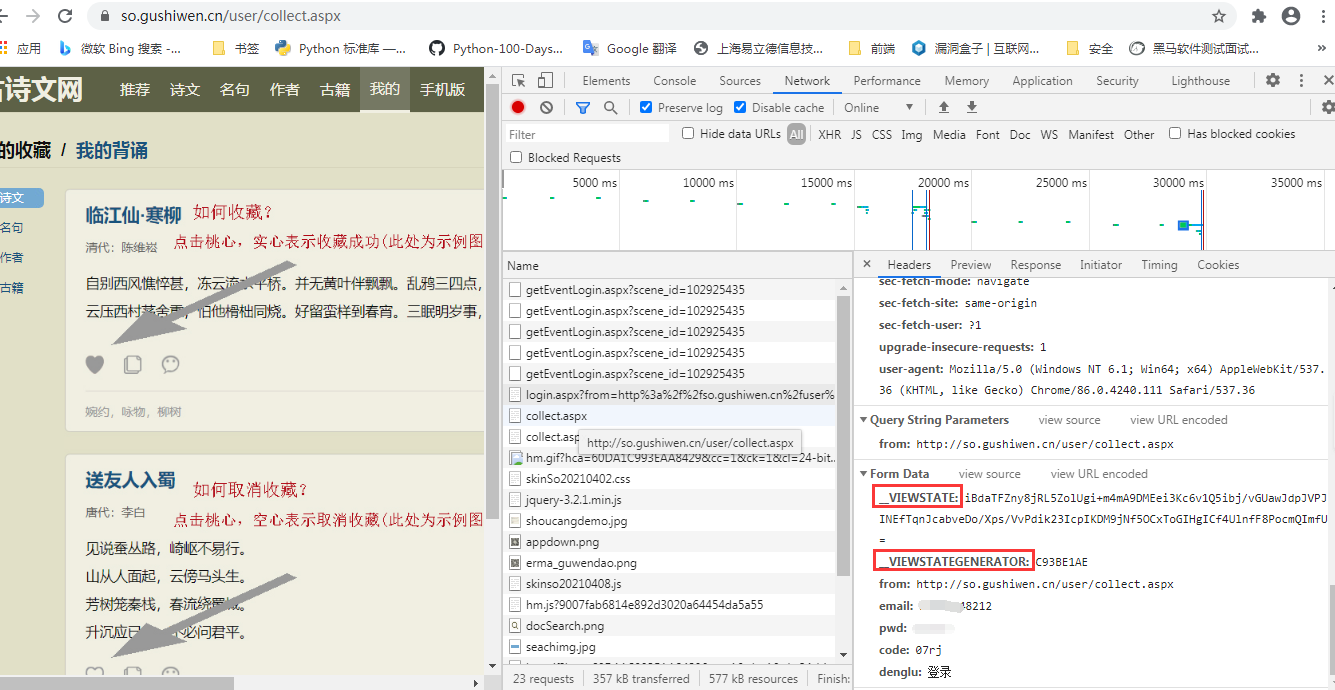
2、登录接口入参的值一般是登录接口返回的原数据值,若刷新后接口与对应源码(element)的值存在一个为空一个有值,那么久看下是否存在ajax请求,再获取动态参数的值
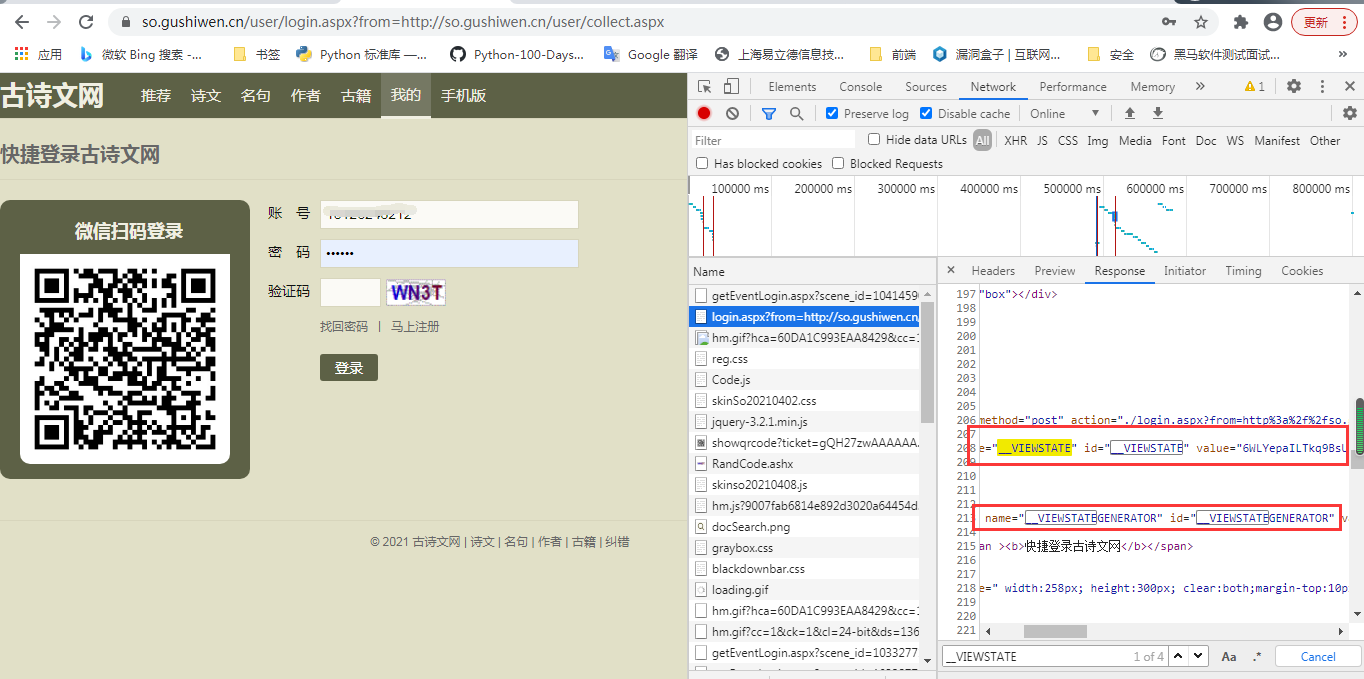
3、我们获取动态参数的值,使用到etree中的xpath进行解析
from TestCase.Api_Review.ClassCode import Chaojiying_Client
from lxml import etree
import requests
import os
s = requests.Session()
# 新建文件夹
if not os.path.exists('./gushiwenLibs'):
os.makedirs('./gushiwenLibs')
# 对验证码图片进行抓捕及识别
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'
}
page_text = s.get(url=url,headers=headers,proxies=None).text
tree = etree.HTML(page_text)
img_url = "https://so.gushiwen.cn/RandCode.ashx"+tree.xpath('//*[@id="imgCode"]/@src')[0]
__VIEWSTATE = tree.xpath('//*[@id="__VIEWSTATE"]/@value')[0]
__VIEWSTATEGENERATOR = tree.xpath('//*[@id="__VIEWSTATEGENERATOR"]/@value')[0]
4、登录界面的图片验证码,我们先获取对应的图形验证码,下载到本地,然后再使用第三方平台进行提取
参考此链接:Python+Request库+第三方平台实现验证码识别示例
img_src = s.get(url=img_url,headers=headers).content
# 图片存储的路径
fileName = './gushiwenLibs/'+'code_img_data.jpg'
with open(fileName, 'wb') as fp:
fp.write(img_src)
# 使用超级鹰平台实现验证码识别
chaojiying = Chaojiying_Client('TeacherTao', 'TeacherTao', '96001')
with open(fileName, 'rb') as fp:
img = fp.read()
result = chaojiying.PostPic(img, 1004)['pic_str']
# print(result)
5、最后再使用登录接口发起请求,我们使用Session进行登录的,因为请求头中携带Cookies进行登录了
# 登录Url
url_login = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
data = {
'__VIEWSTATE': __VIEWSTATE,
'__VIEWSTATEGENERATOR': __VIEWSTATEGENERATOR,
'from': 'http://so.gushiwen.cn/user/collect.aspx',
'email': '18126248212',
'pwd': 'qqq123',
'code': result,
'denglu': '登录',
}
post_text = s.post(url_login,data=data,headers=headers)
# print(post_text.text)
fileName1 = './gushiwenLibs/'+'gushiren.html'
with open(fileName1, 'w',encoding='utf-8') as fp:
fp.write(post_text.text)
6、整个项目的源码:
from TestCase.Api_Review.ClassCode import Chaojiying_Client
from lxml import etree
import requests
import os
s = requests.Session()
# 新建文件夹
if not os.path.exists('./gushiwenLibs'):
os.makedirs('./gushiwenLibs')
# 对验证码图片进行抓捕及识别
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'
}
page_text = s.get(url=url,headers=headers,proxies=None).text
tree = etree.HTML(page_text)
img_url = "https://so.gushiwen.cn/RandCode.ashx"+tree.xpath('//*[@id="imgCode"]/@src')[0]
__VIEWSTATE = tree.xpath('//*[@id="__VIEWSTATE"]/@value')[0]
__VIEWSTATEGENERATOR = tree.xpath('//*[@id="__VIEWSTATEGENERATOR"]/@value')[0]
img_src = s.get(url=img_url,headers=headers).content
# 图片存储的路径
fileName = './gushiwenLibs/'+'code_img_data.jpg'
with open(fileName, 'wb') as fp:
fp.write(img_src)
# 使用超级鹰平台实现验证码识别
chaojiying = Chaojiying_Client('TeacherTao', 'TeacherTao', '96001')
with open(fileName, 'rb') as fp:
img = fp.read()
result = chaojiying.PostPic(img, 1004)['pic_str']
print(result)
# 登录Url
url_login = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
data = {
'__VIEWSTATE': __VIEWSTATE,
'__VIEWSTATEGENERATOR': __VIEWSTATEGENERATOR,
'from': 'http://so.gushiwen.cn/user/collect.aspx',
'email': '账号',
'pwd': '密码',
'code': result,
'denglu': '登录',
}
post_text = s.post(url_login,data=data,headers=headers)
# print(post_text.text)
fileName1 = './gushiwenLibs/'+'gushiren.html'
with open(fileName1, 'w',encoding='utf-8') as fp:
fp.write(post_text.text)