一、删除草稿箱
1、参数这篇https://www.cnblogs.com/Teachertao/p/11144726.html
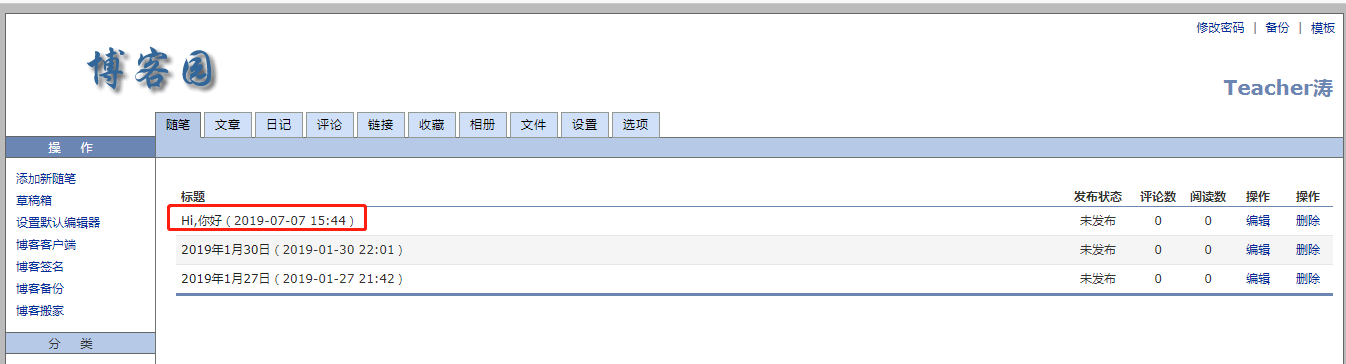
2、删除刚才保存的草稿
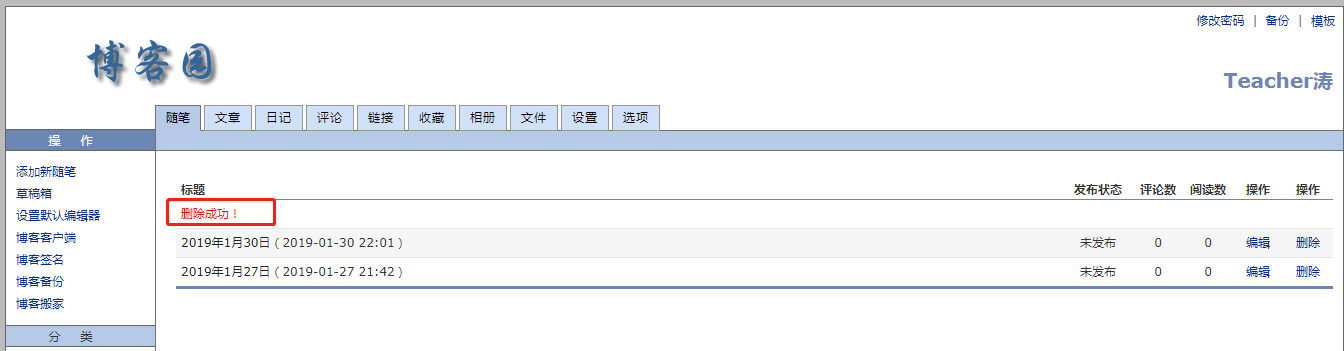
3、用 fiddler 抓包,抓到删除帖子的请求,从抓包结果可以看出,传的 json 参数是 postId
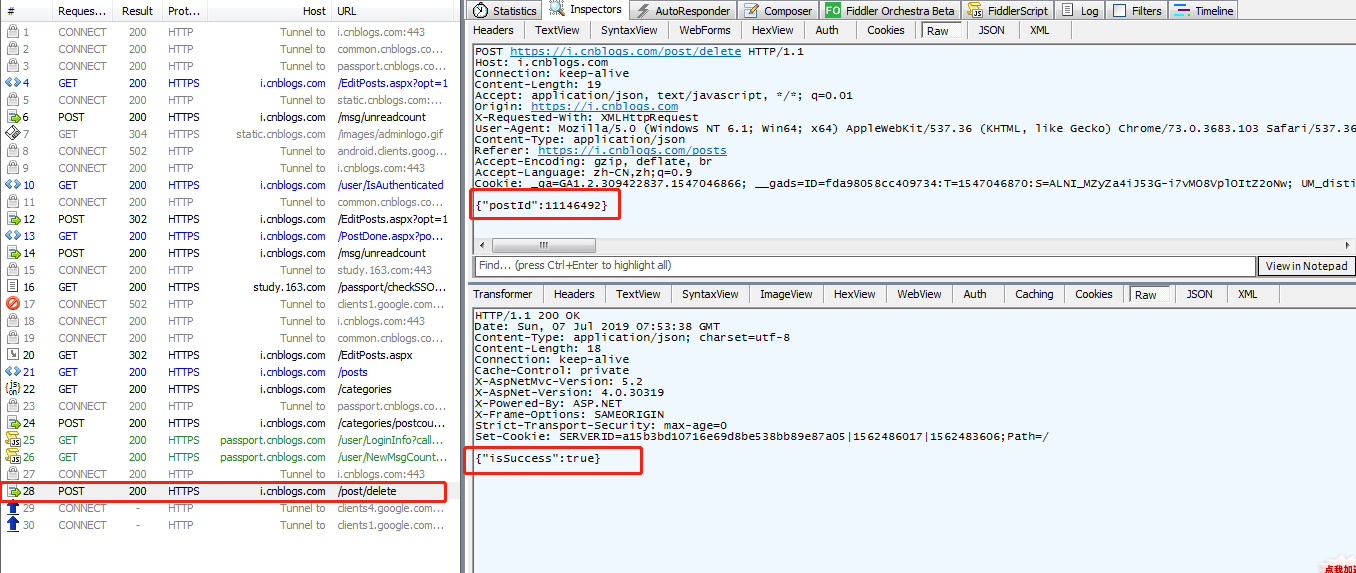
4、这个 postId 哪里来的呢?可以看上个请求 url 地址

5、也就是说保存草稿箱成功之后,重定向一个 url 地址,里面带有 postId 这个参数。那接下来我们提取出来就可以了
二、提取参数
1.我们需要的参数 postId 是在保存成功后 url 地址,这时候从 url 地址提出对应的参数值就行了,先获取保存成功后 url
2.通过正则提取需要的字符串,这个参数值前面(postid=)和后面(&)字符串都是固定的
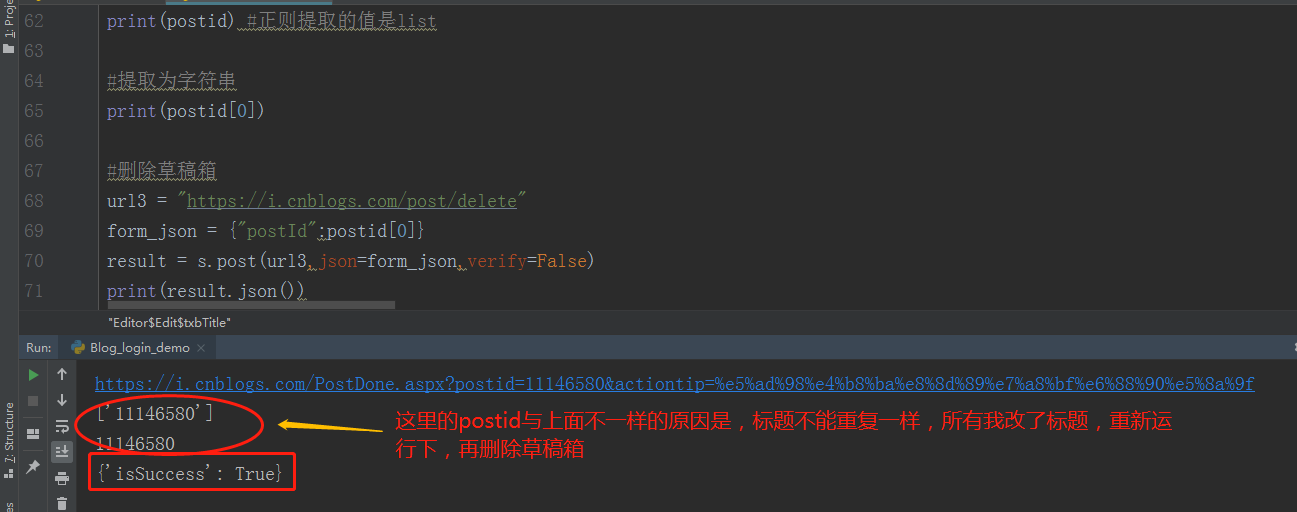
3.这里正则提出来的是 list 类型,取第一个值就可以是字符串了(注意:每次保存需要修改内容,不能重复)

三、传参
1.删除草稿箱的 json 参数传上面取到的参数:{"postId": postid[0]}
2.json 数据类型 post 里面填 json 就行,会自动转 json
3.接着前面的保存草稿箱操作,就可以删除成功了
四、参照代码
import requests
#禁用安全请求警告
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
"""
1.由于登录时候是多加 2 个 cookie,我们可以先用 get 方法打开登录首页,获取部分 cookie
2.再把登录需要的 cookie 添加到 session 里
3.添加成功后,随便编辑正文和标题保存到草稿箱
"""
# 先打开登录首页,获取部分 cookie
url = "https://account.cnblogs.com/signin?returnurl=https%3A%2F%2Fwww.cnblogs.com%2F"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"
}
s = requests.Session()
r = s.get(url,headers=header)
print(r.cookies)
# 添加登录需要的两个 cookie
c = requests.cookies.RequestsCookieJar()
c.set(".Cnblogs.AspNetCore.Cookies","自己抓取的cookie")
c.set(".CNBlogsCookie","自己抓取的cookie")
# c.set('AlwaysCreateItemsAsActive',"True")
# c.set('AdminCookieAlwaysExpandAdvanced',"True")
s.cookies.update(c)
print(s.cookies)
# 登录成功后保存编辑内容
r1 = s.get("https://i.cnblogs.com/EditPosts.aspx?opt=1", headers=header,verify=False)
print(r1.text)
# 保存草稿箱
url2 = "https://i.cnblogs.com/EditPosts.aspx?opt=1"
body = {
"__VIEWSTATE":"",
"__VIEWSTATEGENERATOR":"FE27D343",
"Editor$Edit$txbTitle":"Hi,扭扭",
"Editor$Edit$EditorBody":"<p>你们好吗 ?</p><p>Are you ok ?</p>",
"Editor$Edit$Advanced$ckbPublished":"on",
"Editor$Edit$Advanced$chkDisplayHomePage":"on",
"Editor$Edit$Advanced$chkComments":"on",
"Editor$Edit$Advanced$chkMainSyndication":"on",
"Editor$Edit$Advanced$txbEntryName":"",
"Editor$Edit$Advanced$txbExcerpt":"",
"Editor$Edit$Advanced$txbTag":"",
"Editor$Edit$Advanced$tbEnryPassword":"",
"Editor$Edit$lkbDraft":"存为草稿",
}
r2 = s.post(url2,data=body,verify=False)
# print(r.content.decode("utf-8"))
#获取当前的url地址
save_url = r2.url
print(save_url)
#正则获取需要的postid参数
import re
postid = re.findall(r"postid=(.*?)&",r2.url)
print(postid) #正则提取的值是list
#提取为字符串
print(postid[0])
#删除草稿箱
url3 = "https://i.cnblogs.com/post/delete"
form_json = {"postId":postid[0]}
result = s.post(url3,json=form_json,verify=False)
print(result.json())