selenium 爬虫流程如下:
1、对某职位进行爬虫 ---如:自动化测试
2、用到IDE为 pycharm
3、爬虫职位导入到MongoDB数据库中
4、在线安装 pip install pymongo
5、本次使用到脚本化无头浏览器 --- PhantomJS
MongoDB安装说明连接:https://www.twblogs.net/a/5c27009bbd9eee16b3dba7bc/zh-cn
PhantomJS 下载地址和API连接:http://phantomjs.org/download.html , http://phantomjs.org/api/
下载后添加path中 --- CMD窗口输入 PhantomJS 按回车 --- 出现 phantomjs> 说明配置成功
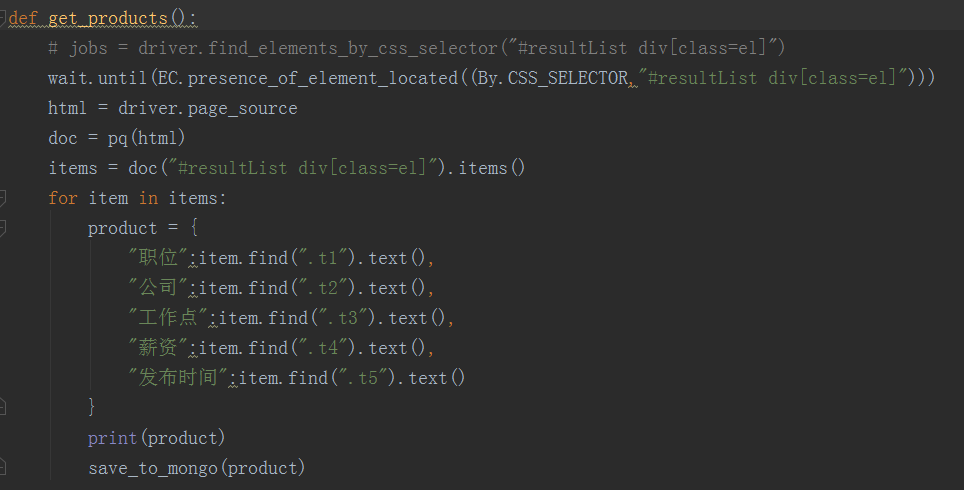
如下为 51job.py 截图:
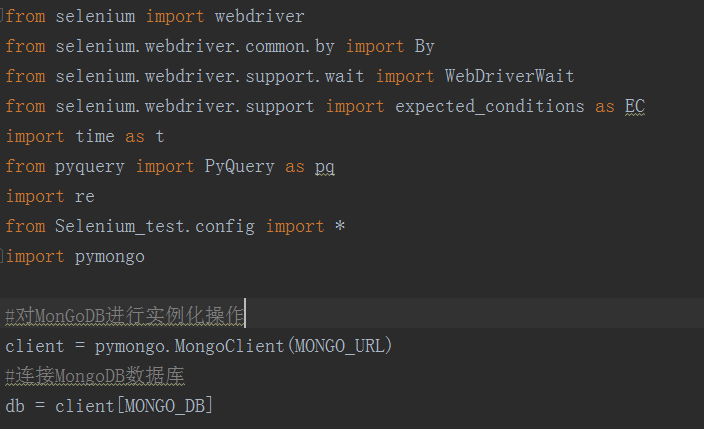

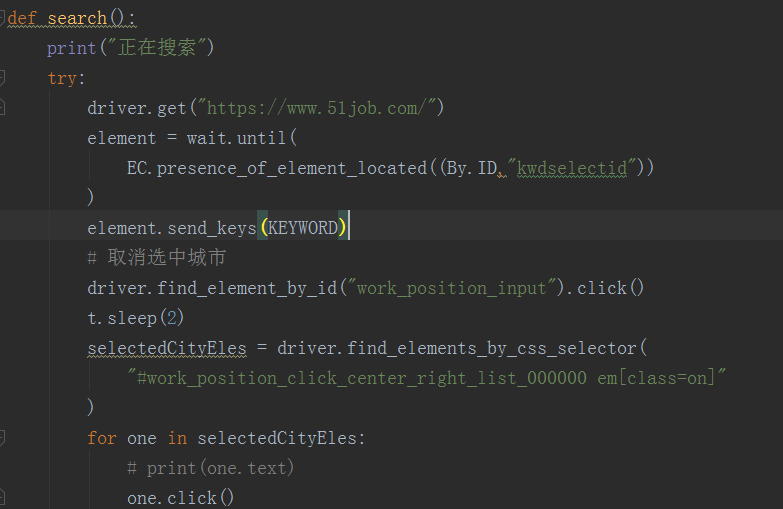
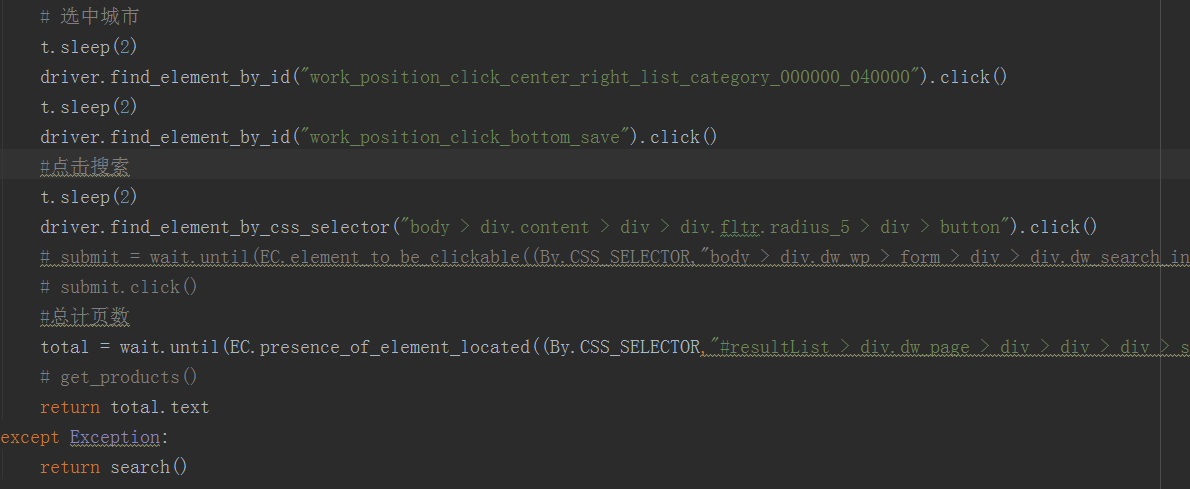
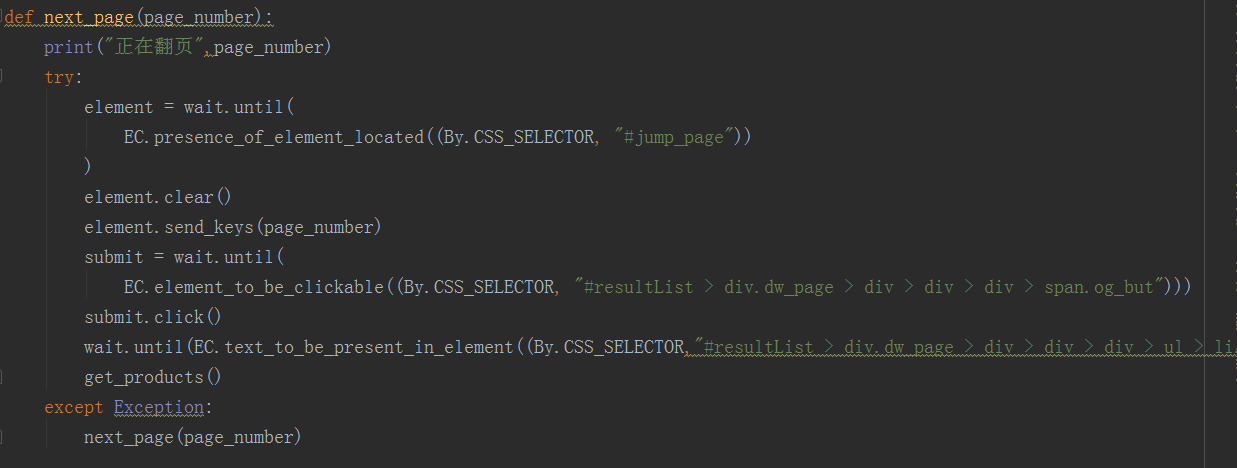
config配置文件如下:

pycharm 运行结果:

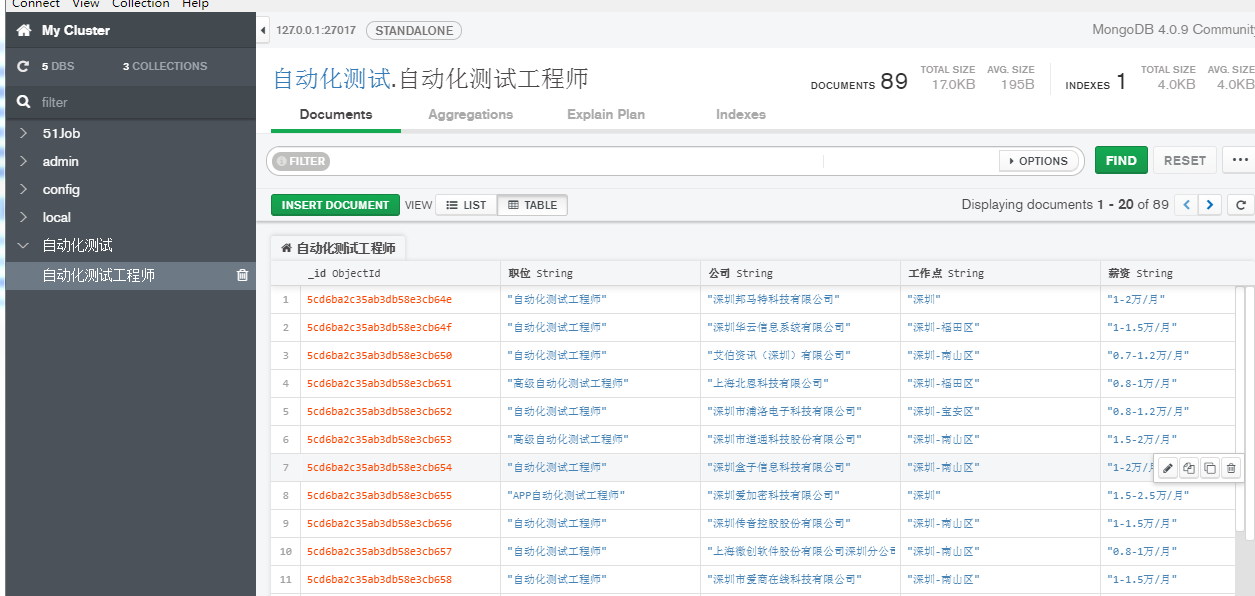
MongoDB 数据库截图:
如下为config 配置文件:
MONGO_URL = "mongodb://127.0.0.1:27017/"
MONGO_DB = "自动化测试"
MONGO_TABLE = "自动化测试工程师"
KEYWORD = "自动化测试工程师"
SERVICE_ARGS = ["--load-images=false","--disk-cache=true"] #忽略缓存和图片加载
爬虫源码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time as t
from pyquery import PyQuery as pq
import re
#config -- 上面已展示
from Selenium_test.config import *
import pymongo
#对MonGoDB进行实例化操作
client = pymongo.MongoClient(MONGO_URL)
#连接MongoDB数据库
db = client[MONGO_DB]
#浏览器实例化
driver = webdriver.PhantomJS(service_args=SERVICE_ARGS)
# driver = webdriver.Chrome()
driver.set_window_size(1400,900)
driver.maximize_window()
driver.implicitly_wait(10)
#显示等待
wait = WebDriverWait(driver,10)
def search():
print("正在搜索")
try:
driver.get("https://www.51job.com/")
element = wait.until(
EC.presence_of_element_located((By.ID,"kwdselectid"))
)
element.send_keys(KEYWORD)
# 取消选中城市
driver.find_element_by_id("work_position_input").click()
t.sleep(2)
selectedCityEles = driver.find_elements_by_css_selector(
"#work_position_click_center_right_list_000000 em[class=on]"
)
for one in selectedCityEles:
# print(one.text)
one.click()
# 选中城市
t.sleep(2)
driver.find_element_by_id("work_position_click_center_right_list_category_000000_040000").click()
t.sleep(2)
driver.find_element_by_id("work_position_click_bottom_save").click()
#点击搜索
t.sleep(2)
driver.find_element_by_css_selector("body > div.content > div > div.fltr.radius_5 > div > button").click()
# submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,"body > div.dw_wp > form > div > div.dw_search_in > button")))
# submit.click()
#总计页数
total = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,"#resultList > div.dw_page > div > div > div > span:nth-child(2)")))
# get_products()
return total.text
except Exception:
return search()
def next_page(page_number):
print("正在翻页",page_number)
try:
element = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#jump_page"))
)
element.clear()
element.send_keys(page_number)
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#resultList > div.dw_page > div > div > div > span.og_but")))
submit.click()
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,"#resultList > div.dw_page > div > div > div > ul > li.on"),str(page_number)))
get_products()
except Exception:
next_page(page_number)
def get_products():
# jobs = driver.find_elements_by_css_selector("#resultList div[class=el]")
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,"#resultList div[class=el]")))
html = driver.page_source
doc = pq(html)
items = doc("#resultList div[class=el]").items()
for item in items:
product = {
"职位":item.find(".t1").text(),
"公司":item.find(".t2").text(),
"工作点":item.find(".t3").text(),
"薪资":item.find(".t4").text(),
"发布时间":item.find(".t5").text()
}
print(product)
save_to_mongo(product)
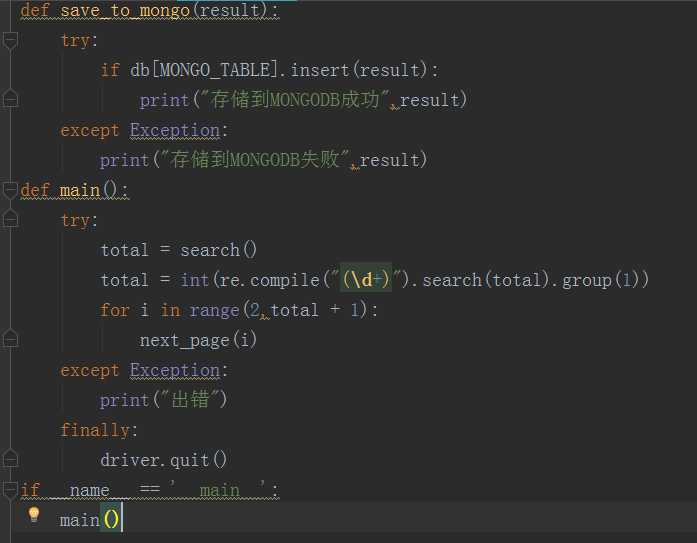
def save_to_mongo(result):
try:
if db[MONGO_TABLE].insert(result):
print("存储到MONGODB成功",result)
except Exception:
print("存储到MONGODB失败",result)
def main():
try:
total = search()
total = int(re.compile("(d+)").search(total).group(1))
for i in range(2,total + 1):
next_page(i)
except Exception:
print("出错")
finally:
driver.quit()
if __name__ == '__main__':
main()