Presto Dummy教程之一Presto简介
Presto历史
Facebook的数据仓库存储在少量大型Hadoop/HDFS集群。Hive是Facebook在几年前专为Hadoop打造的一款数据仓库工具。在以前,Facebook的科学家和分析师一直依靠Hive来做数据分析。但Hive使用MapReduce作为底层计算框架,是专为批处理设计的。但随着数据越来越多,使用Hive进行一个简单的数据查询可能要花费几分到几小时,显然不能满足交互式查询的需求。Facebook也调研了其他比Hive更快的工具,但它们要么在功能有所限制要么就太简单,以至于无法操作Facebook庞大的数据仓库。
2012年开始试用的一些外部项目都不合适,他们决定自己开发,这就是Presto。2012年秋季开始开发,目前该项目已经在超过 1000名Facebook雇员中使用,运行超过30000个查询,每日数据在1PB级别。Facebook称Presto的性能比Hive要好上10倍多。2013年Facebook正式宣布开源Presto。
Presto架构
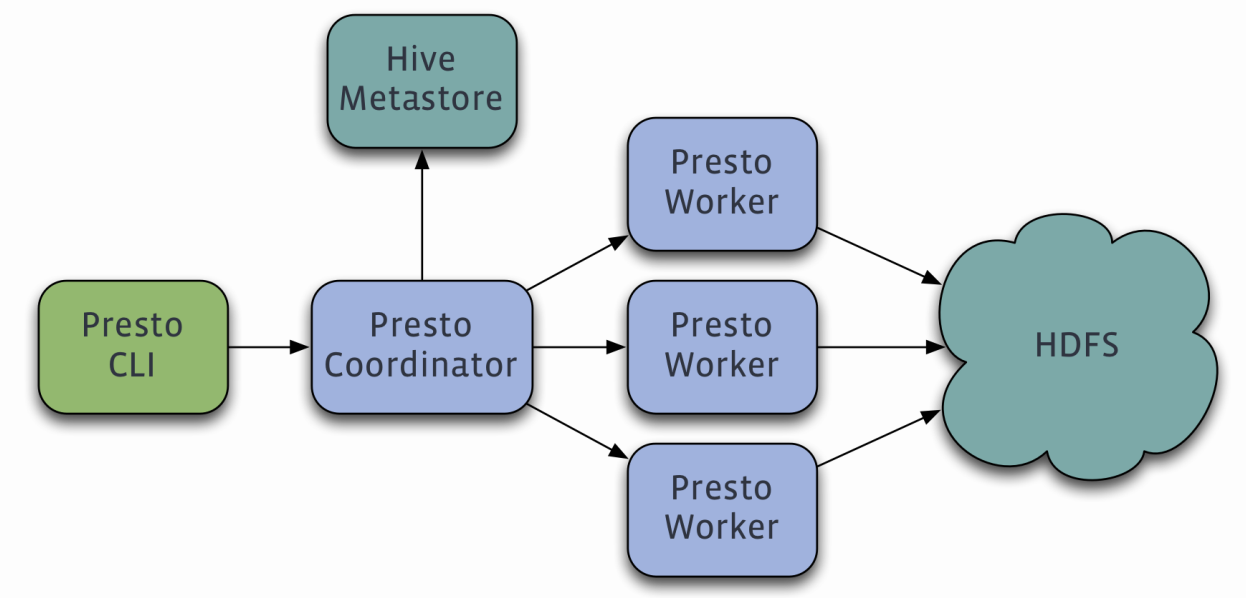
Presto查询引擎是一个Master-Slave的架构,由
- 一个Coordinator节点, Discovery Server通常内嵌于Coordinator节点中
- 一个Discovery Server节点
- 多个Worker节点组成
Coordinator负责解析SQL语句,生成执行计划,分发执行任务给Worker节点执行。
Worker节点负责实际执行查询任务。Worker节点启动后向Discovery Server服务注册,Coordinator从Discovery Server获得可以正常工作的Worker节点。如果配置了Hive Connector,需要配置一个Hive MetaStore服务为Presto提供Hive元信息,Worker节点与HDFS交互读取数据。
参考
-
Presto官方文档 http://prestodb.io/
-
Facebook Presto团队介绍Presto的文章 https://www.facebook.com/notes/facebook-engineering/presto-interacting-with-petabytes-of-data-at-facebook/10151786197628920
-
SlideShare两个分享Presto 的PPT http://www.slideshare.net/zhusx/presto-overview?from_search=1 http://www.slideshare.net/frsyuki/hadoop-source-code-reading-15-in-japan-presto
-
Presto实现原理和美团的使用实践 https://tech.meituan.com/2014/06/16/presto.html