GROUP BY 子句用于聚合信息
先看个实例,没有使用 GROUP BY 子句
SELECT SalesOrderID,OrderQty FROM Sales.SalesOrderDetail WHERE SalesOrderID IN (43660,43670)
结果: 结果可以得知,有很多重复的列(SalesOrderID)
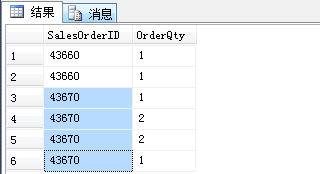
为什么会出现这种结果了?
查看一下表结构可知,这张表 的主键是个组合主键, 分别有 SalesOrderID 和 SalesOrderDetailID 组成,当我们在 select中只选择SalesOrderID 时,所以会出现上图的结果
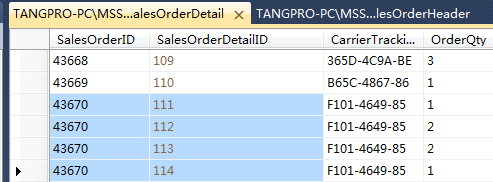
再来看使用了 GROUP BY 子句的结果:
SELECT SalesOrderID,OrderQty FROM Sales.SalesOrderDetail WHERE SalesOrderID IN (43660,43670) GROUP BY SalesOrderID
此时会报错: 显示 OrderQty 列没有包含在 聚合函数 或 GROUP BY 子句中
说明: 当我们在使用 group by 子句的时候, select 中选取的列 要么要包含在 group by 子句中,要么要包含在 聚合函数中

此时我们修改代码:
SELECT SalesOrderID,OrderQty FROM Sales.SalesOrderDetail WHERE SalesOrderID IN (43660,43670) GROUP BY SalesOrderID,OrderQty
结果: 这个实例包含了 group by 子句,但是没有 聚合函数
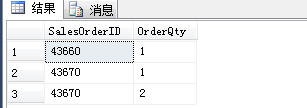
再来看看包含聚合函数的实例,通常有四个聚合函数
- SUM()
- MAX()
- MIN()
- COUNT()
在看一下:
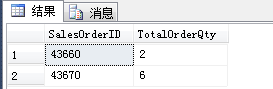
SELECT SalesOrderID,SUM(OrderQty) AS TotalOrderQty FROM Sales.SalesOrderDetail WHERE SalesOrderID IN (43660,43670) GROUP BY SalesOrderID
结果: 这个才算真正的分组了, 把每个 SalesOrderID 对应的 总OrderQty 显示出来了
先说说 GROUP BY 子句的作用:
它的作用是通过一定的规则将一个数据集划分成若干个小的区域,然后针对若干个小区域进行数据处理。
通过一个实例说明:
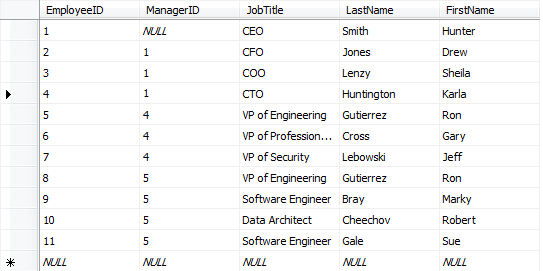
假设数据库中有张表结果如下:
由表中可分析出:
- ManagerID 为 1 的经理 有 3 名员工,其EmployeeID 分别为 2,3,4
- ManagerID 为 4 的经理 有 3 名员工,其EmployeeID 分别为 5,6,7
- ManagerID 为 5 的经理 有 4 名员工,其EmployeeID 分别为 8,9,10,11
- 员工号 EmployeeID 为 1 的员工 对应的 经理 ManagerID 为 NULL, 这点说明这名员工没有与之对应的经理, 可能是公司的总裁之类。
然后使用SQL 进行分析:
SELECT ManagerID, COUNT(*) --选出每个ManagerID,并且该MangerID所对应的数据条数 FROM HumanResources.Employee2 GROUP BY ManagerID --以 ManagerID 分组
结果如下:
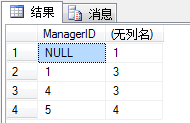
说明: ManagerID 为1 有3条数据与之对应
ManagerID 为4 有3条数据与之对应
ManagerID为5 有4条数据与之对应
其中ManagerID 为NULL 的有一条数据与之对应, 假设为 总裁
- 添加HAVING 子句
HAVING 与 Where 语句类似,Where 是在分类之前过滤,而 HAVING 是在分类之后过滤。
如果想对以上返回结果,进行相应条件的搜索,则可以添加HAVING子句,假设这里需要返回 ManagerID 对应数据量 大于 3 的结果,则SQL如下:
SELECT COUNT(*) AS Reposrts FROM HumanResources.Employee2 GROUP BY ManagerID HAVING COUNT(*) > 3
结果:
