1. 正则表达式是一个用于查找的,含有通用字符串和匹配元字符的字符串
2. 正则表达式对象的创建
①构造函数
var regex = new RegExp(正则表达式 , 匹配模式)
var regex1 = new RegExp("abc");
②字面量
var regex = /正则表达式/;
var regex2 = /abc/;
3. 正则表达式的匹配
语法: 正则对象.test(“字符串”)----->boolean值
var str="hudfpfomnvaioHellosaiossadf"
var regex = /Hello/;
console.log(regex.test(str)); 返回true
4. 元字符
①基本元字符
1). 表示任意一个非换行的字符,没有限制
案例:foot 或者food或者foo…,可写成foo.
2)( ) 表示分组和提高优先级
3)[ ] 表示一个出现在[ ]中的字符
案例:[abc]表示匹配a或b或c;foo[td]匹配foot或food
如果是连续数字或字母可使用连字符链接例如:
[0123456789]: 等价于[0-9],只能是一位数字,如果超过一位例如[0-12]则表示0或1或2,并不是0,1,2,3,4,5,6,7,8,9,10,11,12
[abcdef……xyz]:等价于 [a-z]
4)| 表示或
5) 转义字符 使符号表示其原貌
案例:表示点: . 表示( ): ( ) 表示[ ]: [ ]
②限定元字符
1)* 表示紧跟前面的一个字符或一组字符出现0次或多次
案例:123* 表示12、123、1233、……、12333333……
1(23)* 表示12、12323、1232323、……、1232323…….
2)+ 表示紧跟前面的一个字符或一组字符出现1次或多次
案例:123+ 表示123、1233、……、12333333……
1(23)+ 表示12323、1232323、……、1232323…….
3)? 表示紧跟前面的一个字符或一组字符出现0次或1次
案例:http://.+ | https://.+ 可写成https?: //.+
可使用(正则|)的表达方式,表示出现或者为空不出现
例如上述代码可写成http(s|): //.+ 这样的写法可提高代码性能
4){数字} 表示紧跟前面的字符出现的指定次数
案例:a{3} 表示aaa
5){数字 , }表示紧跟前面的字符至少出现指定次数
案例:a{3 , } 表示aaa、aaaa、aaaaa、aaaaaa……
6){数字, 数字}表示紧跟前面的字符出现的次数范围
案例:a{1 , 3} 表示a或aa或aaa
7)?: 匹配但不捕获的元字符
案例:使用exec()和()匹配和捕获邮箱信息时,在不需要捕获的正则表达式之前加上?:即可 : /([a-zA-Zd]+)@([a-zA-Zd]+(?:.[a-zA-Zd]+)+)/g
8)数字反向引用元字符
在正则表达式中使用组( )匹配到某一数据时, 允许在该正则表达式中使用数字的方式引用该组,数字代表匹配到的组的序号,即从左到右数第几组
案例:/<(w+)>.*</1>/g; 具体信息见第7节
9)[^字符] 否定元字符,表示[^ ]中的字符不出现
案例:[^abc] 表示不是a,也不是b,也不是c
③首尾元字符
1)首 ^ 表示必须以XXX开头
案例:^a 表示必须以a开头的字符串
2)尾 $ 表示必须以XXX结尾
案例:a$ 表示必须以a结尾的字符串
④简写元字符
1)s 表示空白字符,包括空格,Tab,回车换行等
S 表示非空白字符,常常用[sS]表示任意字符
2)w 表示字符,包含字母,数字,下划线
W 表示非字符
3)d 表示数字 0~9
D 表示非数字
5. 正则表达式简单案例
①邮箱:
/^[0-9a-zA-Z]+@[0-9a-zA-Z]+(.[0-9a-zA-Z]+)+$/
②匹配0~255之间的数字
/^([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])$/
③匹配小数
/^((-?[1-9][0-9]*|0)(.[0-9]*[1-9]|))$/
6. 正则表达式的提取exec
语法:正则表达式对象.exec(字符串) --> 封装成数组
var str = "asa123sfsgd345dfgshd456";
var regex = /d+/;
var result = regex.exec(str);
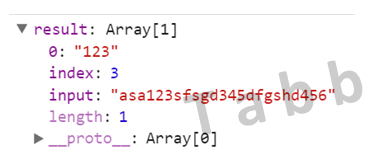
获得一个只有一个索引号0的数组
循环提取
在一个字符串中将所有复合的要求的字符串提取出来
a) 正则表达式需要使用全局模式 使用g表示全局模式
var regex = new RegExp( '正则', 'g' );
var regex = /正则/g;
b) 调用 exec()
首先获得第一个匹配项,再调用一次,就可再获得一个匹配项,循环调用下去,可以得到所有的匹配项,直到全部匹配完后还用调用该方法, 则返回 null
示例代码如下:
var str = "asa123sfsgd345dfgshd456";
var regex = /d+/g;
regex.exec( str ) 获得 123
regex.exec( str ) 获得 345
regex.exec( str ) 获得456
regex.exec( str ) 获得 null
使用while循环替代上述操作:
while ( res = regex.exec( str ) ) {
console.log(res);
}
提取出匹配的数组,共提出3个数组

c) 正则表达式的匹配分组
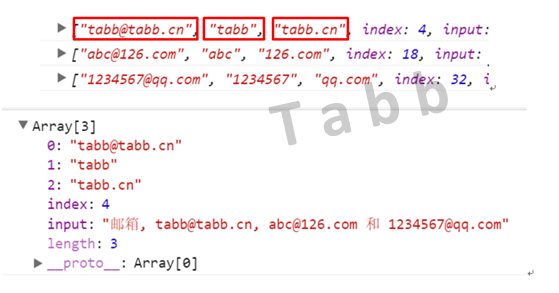
var str = "邮箱, tabb@tabb.cn, abc@126.com 和 1234567@qq.com";
var regex = /([a-zA-Zd]+)@([a-zA-Zd]+(.[a-zA-Zd]+)+)/g;
var res;
while (res = regex.exec(str)) {
console.log(res);
}

正则表达式通过调用exec()提取出的数组,如果正则表达式中有( ),则首先按照完整的正则表达提取内容,然后再依次按照” ( ”左括号,从左到右的顺序提取( )括号中的内容,所有内容按照数组索引顺序放入数组中,得到如上图所示的结果
正则表达式匹配但不捕获的元字符(?:) 可提高性能
var str = "邮箱, tabb@tabb.cn, abc@126.com 和 1234567@qq.com";
var regex = /([a-zA-Zd]+)@([a-zA-Zd]+(?:.[a-zA-Zd]+)+)/g;
var res;
while (res = regex.exec(str)) {
console.log(res);
}
匹配但不捕获最后一个(?:.[a-zA-Zd]+) 即.cn、.com等的正则表达式内容
7. 正则表达式的反向引用数字
在正则表达式中使用组( )匹配到某一数据时, 允许在该正则表达式中使用数字的方式引用该组,数字代表匹配到的组的序号,即从左到右数第几组
匹配HTML的示例代码:
var str = "123<div>456</div>abc<span>sdf</span><i></i>123";
var regex = /<(w+)>.*</1>/g; 引用第一组数据,即内容与其一样才匹配
var res;
while (res = regex.exec(str)) {
console.log(res[0]);
}
如果代码做如下修改</div>改为</dv>,则匹配结果发生变化:
var str = "123<div>456</dv>abc<span>sdf</span><i></i>123";
var regex = /<(w+)>.*</1>/g;
var res;
while (res = regex.exec(str)) {
console.log(res[0]);
}

即不能匹配到<div></div>,说明反向引用1必须和其引用项内容一致才匹配
8. 正则表达式的贪婪模式
凡是在正则表达式中, 涉及到次数限定的, 一般默认都是尽可能的多匹配,这就是贪婪模式
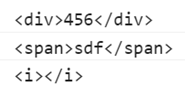
var str = "123<div>456</div>abc<div>sdf</div><i></i>123";
var regex = /<(w+)>.*</1>/g;
var res;
while (res = regex.exec(str)) {
console.log(res[0]);
}

匹配结果如上图所示,"123<div>456</div>abc<div>sdf</div><i></i>123"中匹配了包含内容最多的<div></div>标签,表现出贪婪模式效果
解除贪婪模式:
解除贪婪模式. 只需要在次数限定符后面加上?即可
上述代码中*即为次数限定符,只需在其后添加?即可解除贪婪模式
var regex = /<(w+)>.*?</1>/g;
值得注意的是,贪婪模式的性能会略高于非贪婪模式的性能,所以一般不考虑贪婪的问题,只有在却有需求时,才取消贪婪
9. 正则替换
①简单替换
'aaaaa-bbbbb-ccccc'.replace( /w+/g, 'good' )
将字符串中的aaaaa、bbbbb、ccccc替换成good
'a-----b-----c'.replace( /-+/g, '-' )
将字符串中的-----符号替换成-符号,字符串变为:a-b-c
②分组替换
'2016-8-28'.replace( /(d+)-(d+)-(d+)/g , '$1年$2月$3日' )
将”2016-8-28”替换为了2016年8月28日
使用( )对正则表达式进行分组,其中( )包裹的内容为一个组,从左至右一共有3个组,$1表示获取第一个组的内容,$2表示获取第二个组的内容,$3表示获取第三个组的内容
③函数替换
将邮箱名用*号隐藏起来:
console.log('邮箱:abc@abctabb.cn, 邮箱: defhchd@deftabb.cn'.
replace( /(w+)@(w+(.w+)+)/g, function ( s, g1, g2, g3 ) {
var first = g1.charAt( 0 ); 保留邮箱名首字母
var arr = [ ];
for ( var i = 0; i < g1.length - 1; i++ ) {
arr.push( '*' );
}
return first + arr.join(“”)+"@"+g2;
} ))
![]()
以( )为分组,从左向右数” ( ”,函数中s代表整个正则表达式,g1代表第一组,g2代表第二组,g3代表第三组