学习历程:
bilibili嵩天教授网课 + 个人练习 — 《python网络爬虫从入门到实践》,前后一共1个半月左右
中间出现的无数次问题找度娘解决了,自学确实比较艰辛,因为一个问题经常想一两天都解决不了。
再来谈谈我看过的这本书:《python网络爬虫从入门到实践》。
这本书说实话写的很浅,虽然内容比较适合新手,但是内容都是浅尝辄止,想要速成的同学可以看。但是想要学习的有深度,可以买这本《python3 网络爬虫开发实战》 讲的很细,也很全面。当然,自学过程中遇到问题多去看看别人的博客,累计经验,多多总结。
我个人是边学边试着爬自己学校网站中个人数据,刚刚学到requests库,我就已经在考虑如何登陆(我的学校的官网在提交登录表格以后会隐含提交一个随机生成的重要参数。因为初学,什么也不懂,在这里停了2天左右)。这样提高确实比较快,而且知识点掌握比较牢固,但是有时遇到问题以后,我也体会到当无头苍蝇的那种抓狂…有时候真的特别想要有人点拨一下。
爬虫入门以后我个人推荐学习顺序:
1、requests库的学习,试着爬取一下网站,print一下网站的内容,找找成就感。但必须深入下去,比如:requests库的常用函数(如get,post)以及其常用参数(如headers,proxy,data等),参数的用法等等。(部分函数以及参数留到后面进阶的时候学)
2、尝试学习如何登陆网站,以及学习了解网站的时候可能遇到的反爬虫机制。
3、BeautifulSoup以及lxml对网站内容的提取和处理。当然,正则表达式也要掌握。不然之后爬到了网站页面只能看着数据干瞪眼。
4、学习如何爬取动态网站:使用Selenium库配合目前浏览器的无头模式。
5、学习数据库(MySQL,Mongodb)
6、学习如何提高爬虫效率(多线程,多进程,多协程)
7、学习分布式爬虫(scrapy,Redis)
该建议仅作参考。
对了,还要注意以下python里面的编码问题,这个可以参考我的另外一篇博客,讲的还算比较简单和清楚。要是有什么问题请多多指教!
https://blog.csdn.net/JasonRaySHD/article/details/82558316
下一步准备去看看网络安全。到底是应该注重知识的广度还是深度?很多人难以抉择。其实我觉得这就要看个人的生活节奏了。你要是急着找工作肯定先深度后广度,先学好一方面,再稍微拓展一点。要是学个兴趣,生活抽得出事件。我觉得广度还是比较重要的。当然,前提是得有好的编程基础;其次,学东西不能学一点就跑,起码有一个系统化的入门。不然学了就忘,没有效果。这里讲的好的编程基础意思是至少掌握一门语言,比如:C和C++或Python或Java。我觉得C和C++是分不开的,就学一门C其实离编程世界还很远,因此要学C就一定要学C++。
学习过程中最重要的还是自己做点项目,比如爬取自己官网上的成绩,爬取一些较难爬的网站。
要是学习爬虫过程中有什么问题请留言,大家多多交流经验,相互学习,共同提高。
下一步要是要提高自己写python爬虫的水平,可以:
1、深度学习正则表达式,BeautiSoup以及lxml对文本的处理
2、深度学习selenium元素定位方法
3、深度学习代理服务器方法,避开ip封杀
4、深度学习分布式爬虫scrapy或redis
5、深度学习requests其他不常用参数的含义
6、深度学习多线程,多协程,多进程的爬虫编写方法,提高编写效率
7、系统学习python语法,工欲善其事必先利其器。
…..学无止境!
下面列出在学习爬虫过程中,遇到的让我印象深刻的问题:
1、UnicodeEncodeError: 'latin-1' codec can't encode character 'u2026' in position 30
我遇到的这个错误发生有2种情况:
- 在设置headers的时候直接复制粘贴,导致拷贝了浏览器用于表示省略后部分内容的特殊符号。 这里只要拷贝完全就好了。
- python的编码形式没有设置好。以后变成要养成习惯,在程序最上方加上 # coding:utf-8 或者# -- encoding:utf-8 -
2、在安装python包时,发生Microsoft visual C++ 14.0 问题。这里见我的另外一篇博客:
https://blog.csdn.net/JasonRaySHD/article/details/82493776
3、在python调用MySQL中的数据时,执行:
cur.execute("SELECT user,password FROM account WHERE id=%s ",n)- 1
报错:_mysql_exceptions.ProgrammingError: not all arguments converted during string formatting
找了很久原因,最终结果在stackoverflow找到了解释。原文地址:
https://stackoverflow.com/questions/49094213/mysql-exceptions-programmingerror-not-all-arguments-converted-during-string-fo
这里po出解释的关键部分:
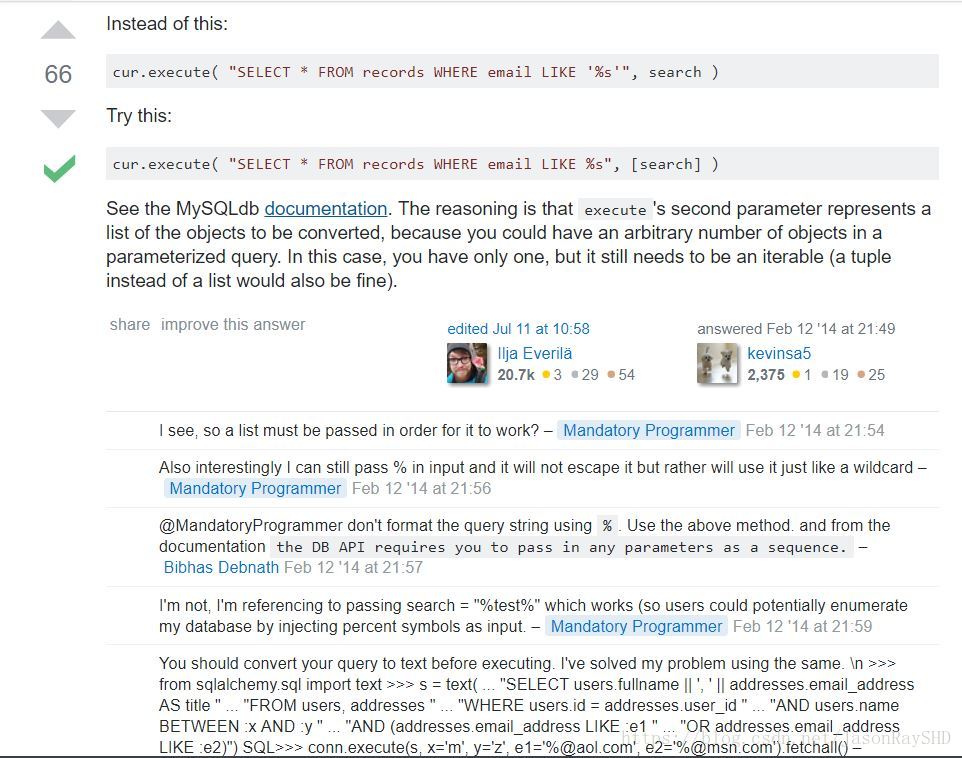
翻译一下:
正确的执行命令应该是:
cur.execute("SELECT user,password FROM account WHERE id=%s ",[n])- 1
看到n加了个小方括号没有?
这是由于execute函数第二个参数代表一个将要被转化的list(列表),tuple(元组)也行)
可以参见MySQLdb documentation:
http://mysql-python.sourceforge.net/MySQLdb.html#some-examples
这里其实还可以利用format函数:
cur.execute("SELECT user,password FROM account WHERE id={1} ".format(这里加入想要填写的值))- 1
4、 退出MySQL的shell程序时,最好用exit命令,养成好的习惯,不要直接点×关闭窗口。之前我就有一次直接点×关闭了程序导致重新打开程序后一直显示Access denied ,无法登陆。
5、 IndexError: list index out of range,详见:
https://blog.csdn.net/smf0504/article/details/54645917
6、Warning(1265)Data truncated for column 'v_mmi' at row 1 详见:
https://blog.csdn.net/zm2714/article/details/7950081
7、善用异常处理 try,raise,except:
https://www.cnblogs.com/Lival/p/6203111.html
8、UnboundLocalError: local variable 'xxx' referenced before assignment
在函数外部已经定义了变量n,在函数内部对该变量进行运算,运行时会发生以上错误。这主要是因为没有让解释器清楚变量是全局变量还是局部变量。
其他的问题暂时还没想到,想到了会继续把遇到的所有问题更新在这里。