好用的不是一点点、、=-=、、
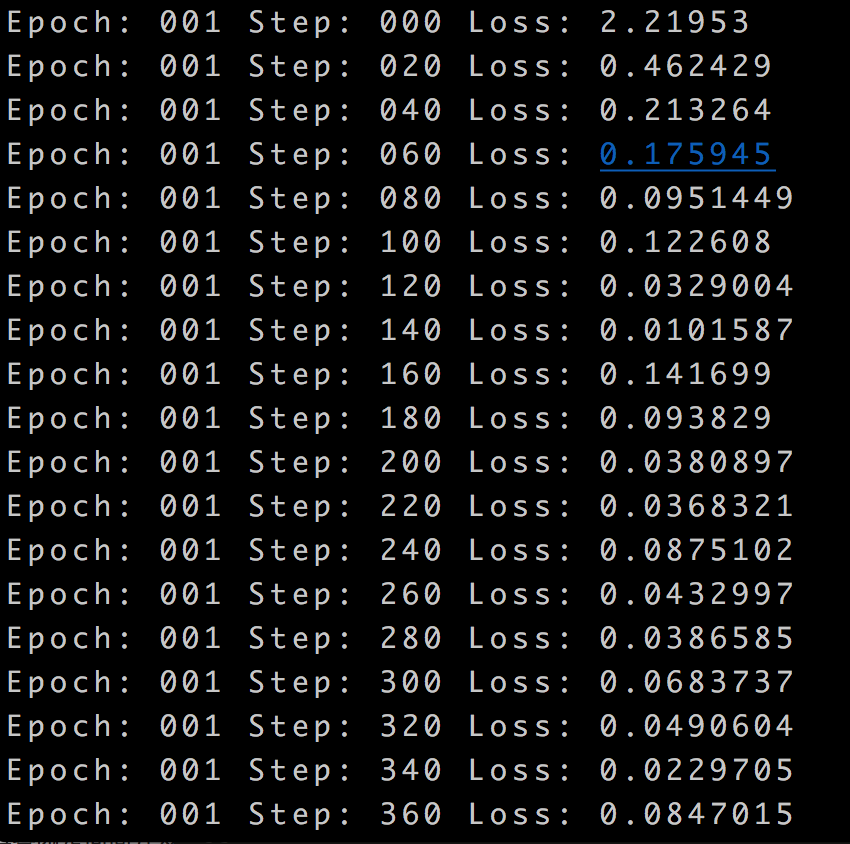
import tensorflow as tf import tflearn import tflearn.datasets.mnist as mnist # Using MNIST Dataset import tflearn.datasets.mnist as mnist mnist_data = mnist.read_data_sets(one_hot=True) # User defined placeholders with tf.Graph().as_default(): # Placeholders for data and labels X = tf.placeholder(shape=(None, 784), dtype=tf.float32) Y = tf.placeholder(shape=(None, 10), dtype=tf.float32) net = tf.reshape(X, [-1, 28, 28, 1]) # Using TFLearn wrappers for network building net = tflearn.conv_2d(net, 32, 3, activation='relu') net = tflearn.max_pool_2d(net, 2) net = tflearn.local_response_normalization(net) net = tflearn.dropout(net, 0.8) net = tflearn.conv_2d(net, 64, 3, activation='relu') net = tflearn.max_pool_2d(net, 2) net = tflearn.local_response_normalization(net) net = tflearn.dropout(net, 0.8) net = tflearn.fully_connected(net, 128, activation='tanh') net = tflearn.dropout(net, 0.8) net = tflearn.fully_connected(net, 256, activation='tanh') net = tflearn.dropout(net, 0.8) net = tflearn.fully_connected(net, 10, activation='linear') # Defining other ops using Tensorflow loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=net, labels=Y)) optimizer = tf.train.AdamOptimizer(learning_rate=0.01).minimize(loss) # Initializing the variables init = tf.initialize_all_variables() # Launch the graph with tf.Session() as sess: sess.run(init) batch_size = 128 for epoch in range(2): # 2 epochs avg_cost = 0. total_batch = int(mnist_data.train.num_examples/batch_size) for i in range(total_batch): batch_xs, batch_ys = mnist_data.train.next_batch(batch_size) sess.run(optimizer, feed_dict={X: batch_xs, Y: batch_ys}) cost = sess.run(loss, feed_dict={X: batch_xs, Y: batch_ys}) avg_cost += cost/total_batch if i % 20 == 0: print "Epoch:", '%03d' % (epoch+1), "Step:", '%03d' % i, "Loss:", str(cost)
结果: