Motivation
在命名体识别领域,由于选择偏差的存在,模型对于训练和测试分布不一样的数据表现很差,这背后的原因就是模型学习了数据中表现出的虚假因果关系。在这篇文章中,我们从因果角度主要研究NER问题中的虚假关联。我们将这个问题拆解成两部分:实体和上下文。考虑句子“John lives in New York”,我们观察到位置实体“New York”和上下文“John lives in”高度相关,但是之间却没有因果关系,换句话说,可以干预实体却不破坏整个句子的正确性和语法。
反事实生成器(Counterfactual Generator)
令\(\mathrm{x} = (x_1, x_2, \cdots, x_n)\)表示输入token的序列,对于每一个token \(x_i\),有一个标签\(y_i \in \mathcal{Y}\)。对于每个句子,我们有实体集\(\varepsilon\)包含所有的实体,最后,我们还有一个标签集\(\mathcal{D} = \{ (x,y) \}\)
图1
将句子分为两部分:实体\(E\)和上下文\(C\),\(G\)是混淆因子,\(X\)是输入的样例由\(E\)和\(X\)生成,\(Y\)为评估结果,\(U^{*}\)表示不可观测的变量。
我们的方法基于已有的观测数据生成更多的反事实样例,这些反事实样例帮助我们的NER模型解决虚假相关性,学习鲁棒的特征。
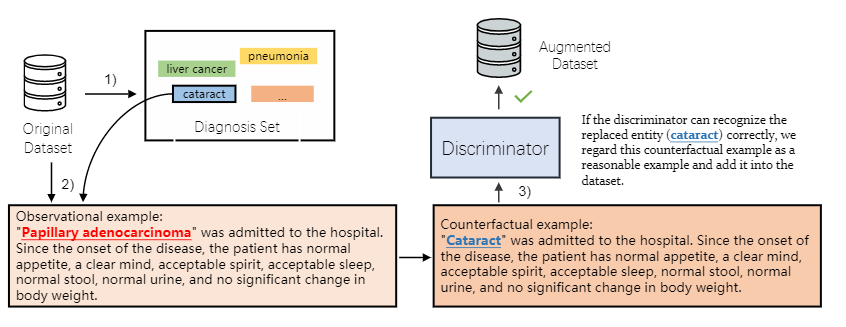 图2
图2
方法如图2所示,分为三步。
- 我们采用局部实体作为实体集,该实体集是从原始数据集中提取的。
例如,我们在训练数据集中迭代所有的观察例子,收集所有的诊断,形成一个诊断集\(\varepsilon_d\) - 实体干预。我们考虑使用干预实体创造新的反事实样例。如图3(2)所示,对于每一个观测样例,我们随机选择一个实体\(e \in \varepsilon\),将它替换为另一个实体\(e^{'} \in \varepsilon_d\),为了保证替换的正确性,我们保证替换的实体具有相同的尸体标签类别。
- 实例检查。为了保证生成的实例是正确的,需要用在原始数据上训练出的模型来预测这个新的实体,如果可以预测出来,就保留,否则就丢弃。