前言
之前有说到这学期打算在学习操作系统这门课的时候,去简单了解一下Linux内核的内容。那时候以为学习内核(简单浏览一下Linux内核的一些源码以及大概了解一些板块的内容)和内核pwn关系很密切,但是自己学了一下之后,其实感觉差异挺大的。因为学习内核的系统,肯定是大部分板块都牵涉到,但是内核pwn的话更多是一些固定方向的漏洞以及利用姿势。所以现在打算将学习内核以及学习内核pwn分开来搞。今天开始了解一下内核pwn的内容,下面先记录一下内核pwn入门的一些基础知识。若有错误之处,恳请师傅们斧正
kernel
kernel 也是一个程序,用来管理软件发出的数据 I/O 要求,将这些要求转义为指令,交给 CPU 和计算机中的其他组件处理,kernel 是现代操作系统最基本的部分。
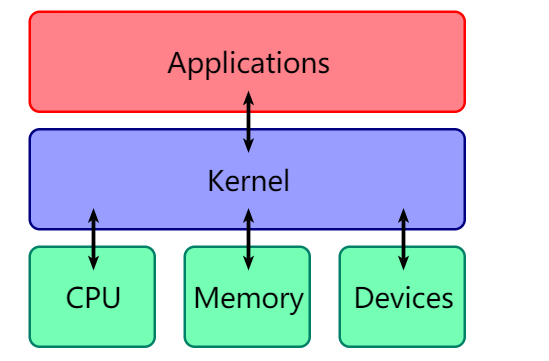
kernel 最主要的功能有两点:
控制并与硬件进行交互
提供 application 能运行的环境
包括 I/O,权限控制,系统调用,进程管理,内存管理等多项功能都可以归结到上边两点中。
需要注意的是,kernel 的 crash 通常会引起重启。
Ring Model
intel CPU 将 CPU 的特权级别分为 4 个级别:Ring 0, Ring 1, Ring 2, Ring 3。
Ring0 只给 OS 使用,Ring 3 所有程序都可以使用,内层 Ring 可以随便使用外层 Ring 的资源。
使用 Ring Model 是为了提升系统安全性,例如某个间谍软件作为一个在 Ring 3 运行的用户程序,在不通知用户的时候打开摄像头会被阻止,因为访问硬件需要使用 being 驱动程序保留的 Ring 1 的方法。
大多数的现代操作系统只使用了 Ring 0 和 Ring 3。
user space to kernel space
当发生 系统调用,产生异常,外设产生中断等事件时,会发生用户态到内核态的切换,具体的过程为:
- 通过 swapgs 切换 GS 段寄存器,将 GS 寄存器值和一个特定位置的值进行交换,目的是保存 GS 值,同时将该位置的值作为内核执行时的 GS 值使用。
- 将当前栈顶(用户空间栈顶)记录在 CPU 独占变量区域里,将 CPU 独占区域里记录的内核栈顶放入RSP/ESP。
- 通过 push 保存各寄存器值
具体的 代码 如下:
ENTRY(entry_SYSCALL_64)
/* SWAPGS_UNSAFE_STACK是一个宏,x86直接定义为swapgs指令 */
SWAPGS_UNSAFE_STACK
/* 保存栈值,并设置内核栈 */
movq %rsp, PER_CPU_VAR(rsp_scratch)
movq PER_CPU_VAR(cpu_current_top_of_stack), %rsp
/* 通过push保存寄存器值,形成一个pt_regs结构 */
/* Construct struct pt_regs on stack */
pushq $__USER_DS /* pt_regs->ss */
pushq PER_CPU_VAR(rsp_scratch) /* pt_regs->sp */
pushq %r11 /* pt_regs->flags */
pushq $__USER_CS /* pt_regs->cs */
pushq %rcx /* pt_regs->ip */
pushq %rax /* pt_regs->orig_ax */
pushq %rdi /* pt_regs->di */
pushq %rsi /* pt_regs->si */
pushq %rdx /* pt_regs->dx */
pushq %rcx tuichu /* pt_regs->cx */
pushq $-ENOSYS /* pt_regs->ax */
pushq %r8 /* pt_regs->r8 */
pushq %r9 /* pt_regs->r9 */
pushq %r10 /* pt_regs->r10 */
pushq %r11 /* pt_regs->r11 */
sub $(6*8), %rsp /* pt_regs->bp, bx, r12-15 not saved */
通过汇编指令判断是否为 x32_abi。
通过系统调用号,跳到全局变量 sys_call_table 相应位置继续执行系统调用。
kernel space to user space
退出时,流程如下:
- 通过 swapgs 恢复 GS 值
- 通过 sysretq 或者 iretq 恢复到用户控件继续执行。如果使用 iretq 还需要给出用户空间的一些信息(CS, eflags/rflags, esp/rsp 等)
Loadable Kernel Modules(LKMs)
LKMs(Loadable Kernel Modules)称为可加载核心模块(内核模块),其可以看作是运行在内核空间的可执行程序,包括:
- 驱动程序(Device drivers)设备驱动文件系统驱动…
- 内核扩展模块 (modules)
LKMs 的文件格式和用户态的可执行程序相同,Linux 下为 ELF,Windows 下为 exe/dll,mac 下为 MACH-O,因此我们可以用 IDA 等工具来分析内核模块。
模块可以被单独编译,但不能单独运行。它在运行时被链接到内核作为内核的一部分在内核空间运行,这与运行在用户控件的进程不同。
模块通常用来实现一种文件系统、一个驱动程序或者其他内核上层的功能。
Linux 内核之所以提供模块机制,是因为它本身是一个单内核 (monolithic kernel)。单内核的优点是效率高,因为所有的内容都集合在一起,但缺点是可扩展性和可维护性相对较差,模块机制就是为了弥补这一缺陷。
通常情况下,Kernel漏洞的发生也常见于加载的LKMs出现问题。
内核中的模块相关指令:
- insmod: 将指定模块加载到内核中。
- rmmod: 从内核中卸载指定模块。
- lsmod: 列出已经加载的模块。
- modprobe: 添加或删除模块,modprobe 在加载模块时会查找依赖关系。
syscall
系统调用,指的是用户空间的程序向操作系统内核请求需要更高权限的服务,比如 IO 操作或者进程间通信。系统调用提供用户程序与操作系统间的接口,部分库函数(如 scanf,puts 等 IO 相关的函数实际上是对系统调用的封装 (read 和 write))。
在 /usr/include/x86_64-linux-gnu/asm/unistd_64.h 和 /usr/include/x86_64-linux-gnu/asm/unistd_32.h 分别可以查看 64 位和 32 位的系统调用号。
ioctl
ioctl 也是一个系统调用,用于与设备通信。
int ioctl(int fd, unsigned long request, ...) 的第一个参数为打开设备 (open) 返回的 文件描述符,第二个参数为用户程序对设备的控制命令,再后边的参数则是一些补充参数,与设备有关。
使用 ioctl 进行通信的原因:
操作系统提供了内核访问标准外部设备的系统调用,因为大多数硬件设备只能够在内核空间内直接寻址, 但是当访问非标准硬件设备这些系统调用显得不合适, 有时候用户模式可能需要直接访问设备。
比如,一个系统管理员可能要修改网卡的配置。现代操作系统提供了各种各样设备的支持,有一些设备可能没有被内核设计者考虑到,如此一来提供一个这样的系统调用来使用设备就变得不可能了。
为了解决这个问题,内核被设计成可扩展的,可以加入一个称为设备驱动的模块,驱动的代码允许在内核空间运行而且可以对设备直接寻址。一个 Ioctl 接口是一个独立的系统调用,通过它用户空间可以跟设备驱动沟通。对设备驱动的请求是一个以设备和请求号码为参数的 Ioctl 调用,如此内核就允许用户空间访问设备驱动进而访问设备而不需要了解具体的设备细节,同时也不需要一大堆针对不同设备的系统调用。
struct cred
kernel 记录了进程的权限,更具体的,是用 cred 结构体记录的,每个进程中都有一个 cred 结构,这个结构保存了该进程的权限等信息(uid,gid 等),如果能修改某个进程的 cred,那么也就修改了这个进程的权限。
源码可以参考一下我的这篇博文
内核态函数
相比用户态库函数,内核态的函数有了一些变化
printf() -> printk(),但需要注意的是 printk() 不一定会把内容显示到终端上,但一定在内核缓冲区里,可以通过 dmesg 查看效果
memcpy() -> copy_from_user()/copy_to_user()
copy_from_user() 实现了将用户空间的数据传送到内核空间
copy_to_user() 实现了将内核空间的数据传送到用户空间
malloc() -> kmalloc(),内核态的内存分配函数,和 malloc() 相似,但使用的是 slab/slub 分配器
free() -> kfree(),同 kmalloc()
另外要注意的是,kernel 管理进程,因此 kernel 也记录了进程的权限。kernel 中有两个可以方便的改变权限的函数:
int commit_creds(struct cred *new)
struct cred* prepare_kernel_cred(struct task_struct* daemon)
从函数名也可以看出,执行 commit_creds(prepare_kernel_cred(0)) 即可获得 root 权限,0 表示 以 0 号进程作为参考准备新的 credentials。
执行 commit_creds(prepare_kernel_cred(0)) 也是最常用的提权手段,两个函数的地址都可以在 /proc/kallsyms 中查看(较老的内核版本中是 /proc/ksyms)。
内核中的保护机制
canary, NX, PIE, RELRO 等保护与用户态原理和作用相同,也就是跟我们普通的Linux平台下的保护机制一致,这里就不解释。
KPTI
KPTI,Kernel PageTable Isolation,内核页表隔离。进程地址空间被分成了内核地址空间和用户地址空间,其中内核地址空间映射到了整个物理地址空间,而用户地址空间只能映射到指定的物理地址空间。内核地址空间和用户地址空间共用一个页全局目录表。为了彻底防止用户程序获取内核数据,可以令内核地址空间和用户地址空间使用两组页表集
KASLR
KASLR中的K指kernel,也就是内核地址空间布局随机化。可以在内核命令行中加入nokaslr关闭KASLR。
SMAP/SMEP
SMAP(Supervisor Mode Access Prevention,管理模式访问保护)和SMEP(Supervisor Mode Execution Prevention,管理模式执行保护)的作用分别是禁止内核访问用户空间的数据和禁止内核执行用户空间的代码。arm里面叫 PXN(Privilege Execute Never) 和PAN(Privileged Access Never)。
SMEP类似于用户态下的NX,不过一个是在内核态中,一个是在用户态中。和NX一样SMAP/SMEP需要处理器支持,可以通过cat /proc/cpuinfo查看,在内核命令行中添加nosmap和nosmep禁用。
Stack Protector
Stack Protector,当然在内核中也是有这种防护的,编译内核时设置CONFIG_CC_STACKPROTECTOR 选项即可,该补丁是Tejun Heo在09年给主线kernel提交的。
address protection
address protection,由于内核空间和用户空间共享虚拟内存地址,因此需要防止用户空间mmap的内存从0开始,从而缓解NULL解引用攻击。windows系统从win8开始禁止在零页分配内存。
pwn题相关
不同于用户态的pwn,Kernel-Pwn不再是用python远程链接打payload拿shell,而是给你一个环境包,下载后qemu本地起系统。对于一个Kernel-Pwn来说,题目通常会给定以下文件:
- boot.sh: 一个用于启动 kernel 的 shell 的脚本,多用 qemu,保护措施与 qemu 不同的启动参数有关
- bzImage: kernel binary
- rootfs.cpio: 文件系统映像
本地写好 exploit 后,可以通过 base64 编码等方式把编译好的二进制文件保存到远程目录下,进而拿到 flag。同时可以使用 musl, uclibc 等方法减小 exploit 的体积方便传输。
参考
https://ctf-wiki.github.io/ctf-wiki/pwn/linux/kernel/basic_knowledge-zh/#_1
https://zhuanlan.zhihu.com/p/140338884