一、前言
结对队友:031602428 苏路明
二、分工细则
作业开始做之前就确定了明确的分工
分工如下:
-关于爬虫部分我完成一份java的爬虫,他也完成了一份python的爬虫(都完成之后再进行选择使用)
-使用java分部分完成内容我完成-w及-n内容,他完善-m及剩余内容
三、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 100 | 150 |
| · Estimate | · 估计这个任务需要多少时间 | 100 | 150 |
| Development | 开发 | 700 | 900 |
| · Analysis | · 需求分析 (包括学习新技术) | 150 | 200 |
| · Design Spec | · 生成设计文档 | 40 | 60 |
| · Design Review | · 设计复审 | 100 | 150 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 0 | 0 |
| · Design | · 具体设计 | 100 | 150 |
| · Coding | · 具体编码 | 0 | 0 |
| · Code Review | · 代码复审 | 0 | 0 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 0 | 0 |
| Reporting | 报告 | 90 | 160 |
| · Test Repor | · 测试报告 | 90 | 130 |
| · Size Measurement | · 计算工作量 | 5 | 5 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 50 |
| | 合计 |1505 |2105
四、解题思路描述与设计实现说明
爬虫使用
导入jsoup使用java进行爬虫
1.给定网站地址
getContent(rooturl);```
2.对每一篇进行爬取并所需的信息并且按照正确的格式输出到result.txt中
try {
File file = new File("src\cvpr\result.txt");
BufferedWriter bufferedWriter= new BufferedWriter(new FileWriter(file));
org.jsoup.nodes.Document document = Jsoup.connect(rooturl).maxBodySize(0)
.timeout(1000000)
.get();
Elements elements = document.select("[class=ptitle]");
Elements hrefs = elements.select("a[href]");
int count = 0;
for(Element element:hrefs) {
String url = element.absUrl("href");
org.jsoup.nodes.Document documrnt2 = Jsoup.connect(url).maxBodySize(0)
.timeout(1000000)
.get();
Elements elements2 = (Elements) documrnt2.select("[id=papertitle]");
String title = elements2.text();
if(count != 0)
bufferedWriter.write("
" + "
" + "
");
bufferedWriter.write(count + "
");
bufferedWriter.write("Title: " + title + "
");
Elements elements3 = (Elements) documrnt2.select("[id=abstract]");
String Abstract = elements3.text();
bufferedWriter.write("Abstract: " + Abstract);
count++;
}
bufferedWriter.close();
}catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
**代码组织与内部实现设计(类图)**
- **类图:**

关于部分函数的结构及其函数的接口如下:
public static String Read(String pathname) //对文件进行读取且处理
public static void FindWordArray(List
public static void WordCount(List
public static void SortMap(Map<String,Integer> oldmap,int wordline,int wordcount,int characterscount,int flagN)//进行排序并输出
- **流程图:**
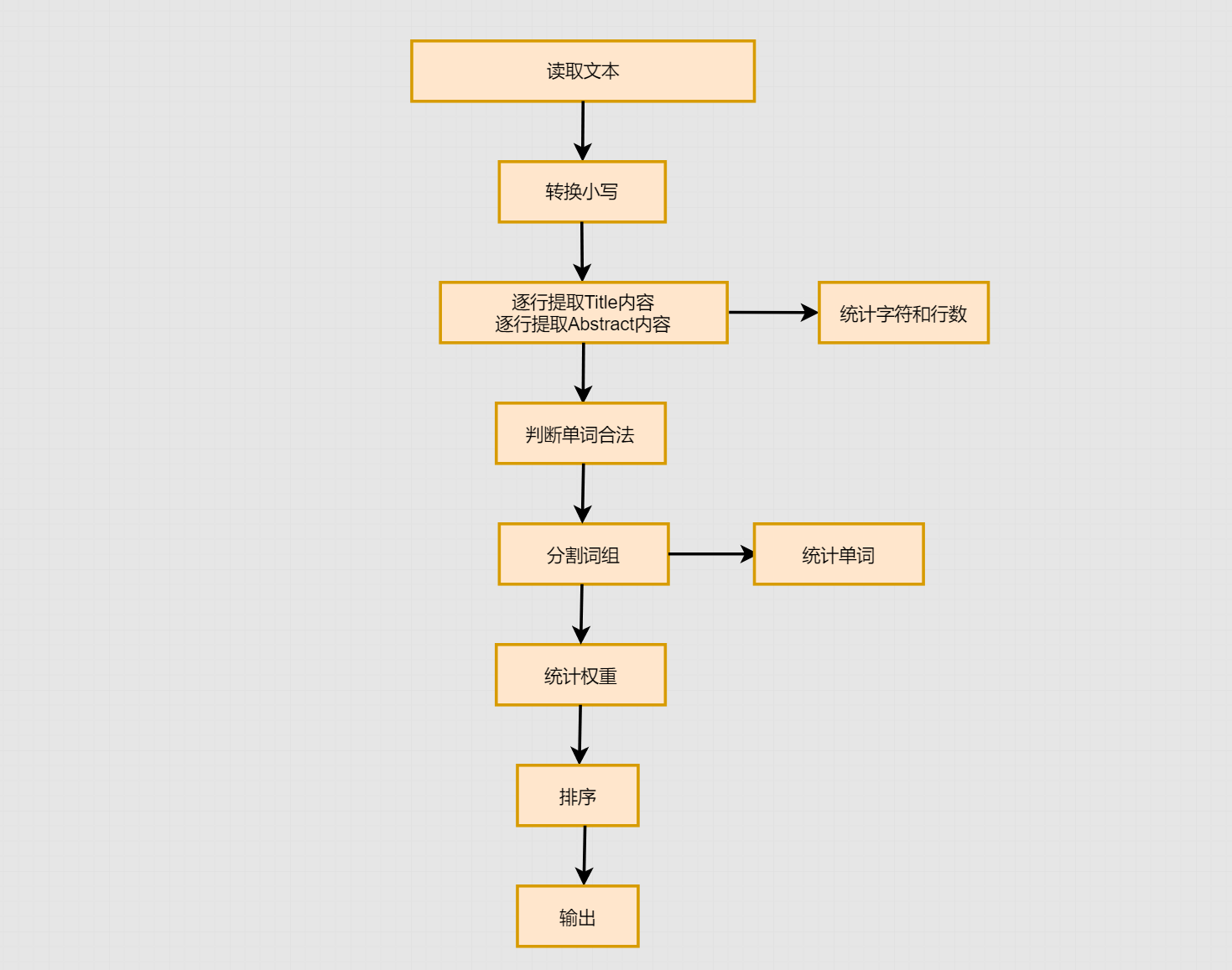
- **说明算法的关键与关键实现:**
**1.首先先对文本进行读取,且进行预处理,将文本内容转换为小写**
**2.使用Pattern和Matcher对爬取出来的Title及Abstract内容进行抽取出来,此时readline()逐行进行抽取,并且进行字符数和行数的统计**
**3.根据之前的题意,对单词合法性进行判断,不合法的单词不进行处理**
**4. 对词组进行分割,此时进行统计单词数**
**5.根据判断w是否为1,进行单词或词组的权重统计**
**6.进行排序后根据题意输出**
##五、附加题设计与展示
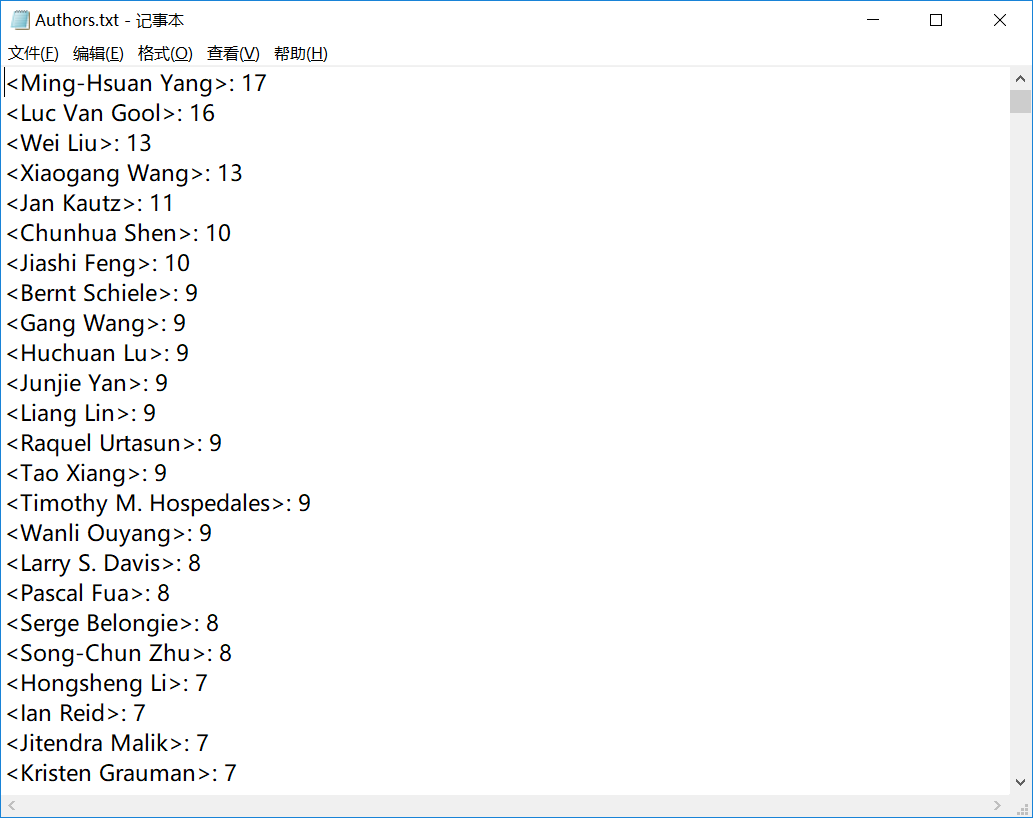
1.爬取作者信息,生成CVPR2018最强作者排行榜(将作者按关联论文数排序输出)
[作者关联论文数排行榜](https://pan.baidu.com/s/1a1tzsiIL7Qw3nVeP6TcrYA)
2.爬取2014-2018年份的CVPR论文,按年份输出并分析论文数量趋势(部分链接404导致丢失部分论文)
[2014-2018论文](https://pan.baidu.com/s/1a1tzsiIL7Qw3nVeP6TcrYA)
趋势图(待)
4.五年汇总大牛词云(部分链接404导致丢失部分词汇)

3.近五年论文的热门词汇词云

##六、关键代码解释
public static String Read(String pathname) throws Exception {
// Scanner scanner=new Scanner(System.in);
// String pathname=scanner.nextLine();
Reader myReader = new FileReader(pathname);
Reader myBufferedReader = new BufferedReader(myReader);
//先对文本处理
CharArrayWriter tempStream = new CharArrayWriter();
int i = -1;
do {
if(i!=-1)
tempStream.write(i);
i = myBufferedReader.read();
if(i >= 65 && i <= 90){
i += 32;
}
}while(i != -1);
myBufferedReader.close();
Writer myWriter = new FileWriter(pathname);
tempStream.writeTo(myWriter);
tempStream.flush();
tempStream.close();
myWriter.close();
return pathname;
}
String readLine = null;
Pattern pattern1 = Pattern.compile("(title): (.)");
Pattern pattern2 = Pattern.compile("(abstract): (.)");
while((readLine = bufferedReader.readLine()) != null)
{
Matcher matcher1=pattern1.matcher(readLine);
Matcher matcher2=pattern2.matcher(readLine);
if(matcher1.find())
{
characterscount+=matcher1.group(2).length();
wordline++;
// System.out.println(matcher1.group(2));
String[] wordsArr1 = matcher1.group(2).split("[^a-zA-Z0-9]"); //过滤
for (String newword : wordsArr1) {
if(newword.length() != 0){
if((newword.length()>=4)&&(Character.isLetter(newword.charAt(0))&&Character.isLetter(newword.charAt(1))&&Character.isLetter(newword.charAt(2))&&Character.isLetter(newword.charAt(3))))
{
wordcount++;
if(len == 1)
lib.titleLists.add(newword);
}
}
}
//new
String wordsLine = matcher1.group(2);
// System.out.println("wordsLine " + wordsLine);
if(len != 1 || wordsLine.length() < 4) {
lib.FindWordArray(lib.titleLists, len, wordsLine);
}
}
if(matcher2.find())
{
characterscount+=matcher2.group(2).length();
wordline++;
//System.out.println(matcher1.group(2));
String[] wordsArr2 = matcher2.group(2).split("[^a-zA-Z0-9]"); //过滤
for (String newword : wordsArr2) {
if(newword.length() != 0){
if((newword.length()>=4)&&(Character.isLetter(newword.charAt(0))&&Character.isLetter(newword.charAt(1))&&Character.isLetter(newword.charAt(2))&&Character.isLetter(newword.charAt(3))))
{
wordcount++;
if(len == 1)
lib.abstractLists.add(newword);
}
}
}
String AbsLine = matcher2.group(2);
if(len != 1 || AbsLine.length() < 4) {
lib.FindWordArray(lib.abstractLists, len, AbsLine);
}
}
}
public static void FindWordArray(List
int tempi = 0;
int cnti = 0;
int cntt = 0;
String temp = "";
String[] words = new String[len];
String[] separators = new String[len];
for(int i = 0; i < wordsLine.length(); i++) {
//The four words in front of a new word
if (tempi < 4 && Character.isLetter(wordsLine.charAt(i)))
{
tempi ++;
// System.out.println("<4 " + i + " " + wordsLine.charAt(i));
temp = temp + wordsLine.charAt(i);
//A new word appear.
if (i == wordsLine.length() - 1) {
words[cnti%len] = temp;
cnti ++;
cntt ++;
// System.out.println("word " + temp);
//A new wordarray appear.
if(cntt == len) {
String wordArray = "";
for(int j = 0; j < len; j++) {
wordArray = wordArray + words[(cnti + j)%len];
if(j != len-1) wordArray = wordArray + separators[(cnti + j)%len];
}
tempLists.add(wordArray);
// System.out.println("wordArray " + wordArray);
cntt --;
}
}
}
else if (tempi >= 4) {
tempi ++;
if(Character.isLetter(wordsLine.charAt(i)) || Character.isDigit(wordsLine.charAt(i))) {
// System.out.println("1 >=4 " + i + " " + wordsLine.charAt(i));
temp = temp + wordsLine.charAt(i);
//A new word appear.
if (i == wordsLine.length() - 1) {
words[cnti%len] = temp;
cnti ++;
cntt ++;
// System.out.println("word " + temp);
//A new wordArray appear.
if(cntt == len) {
String wordArray = "";
for(int j = 0; j < len; j++) {
wordArray = wordArray + words[(cnti + j)%len];
if(j != len-1) wordArray = wordArray + separators[(cnti + j)%len];
}
// add wordArray to list
tempLists.add(wordArray);
// System.out.println("wordArray " + wordArray);
cntt --;
}
}
}
else {
// System.out.println("2 >=4 " + i + " " + wordsLine.charAt(i));
//A new word appear.And a separator appear.
words[cnti%len] = temp;
cnti ++;
cntt ++;
// System.out.println("word 123 " + temp);
if(cntt == len) {
String wordArray = "";
for(int j = 0; j < len; j++) {
wordArray = wordArray + words[(cnti + j)%len];
if(j != len-1) wordArray = wordArray + separators[(cnti + j)%len];
}
// add wordArray to list
tempLists.add(wordArray);
// System.out.println("wordArray " + wordArray);
cntt --;
}
if (i + 4 >= wordsLine.length())
break;
tempi = 0;
temp = "";
//draw a separator
String tempSeparator = "" + wordsLine.charAt(i);
// System.out.println("Separator" + tempSeparator + "123");
for(int j = 1; j < wordsLine.length() - i; j++) {
if( Character.isDigit(wordsLine.charAt(i+j)) || Character.isLetter(wordsLine.charAt(i+j)) ) {
// System.out.println("123");
temp = "";
separators[(cnti-1)%len] = tempSeparator;
break;
}
else tempSeparator = tempSeparator + wordsLine.charAt(i+j);
}
}
}
//A invalid word appear
else {
// System.out.println("invalid " + i + "" + wordsLine.charAt(i));
if (i + 4 >= (int)wordsLine.length())
break;
tempi = 0;
temp = "";
cnti = 0;
cntt = 0;
}
}
}
public static void WordCount(List
for (String li : tempLists) {
if(wordsCount.get(li) != null){
wordsCount.put(li,wordsCount.get(li) + weight);
}else{
wordsCount.put(li,weight);
}
}
}
public static void SortMap(Map<String,Integer> oldmap,int wordline,int wordcount,int characterscount,int flagN) throws IOException{
ArrayList<Map.Entry<String,Integer>> list = new ArrayList<Map.Entry<String,Integer>>(oldmap.entrySet());
Collections.sort(list,new Comparator<Map.Entry<String,Integer>>(){
@Override
public int compare(Entry<String, Integer> o1, Entry<String, Integer> o2) {
return o2.getValue() - o1.getValue(); //降序
}
});
File file = new File("result.txt");
BufferedWriter bi = new BufferedWriter(new FileWriter(file));
bi.write("characters: "+characterscount+"
");
bi.write("words: "+wordcount+"
");
bi.write("lines: "+wordline+"
");
int flag = 0;
for(int i = 0; i<list.size(); i++){
if(flag>=flagN) break;
if(list.get(i).getKey().length()>=4)
bi.write("<"+list.get(i).getKey()+">"+ ": " +list.get(i).getValue()+"
");
flag++;
}
bi.close();
}
##七、性能分析与改进
- 改进思路
1.统计单词和统计词组是分离的,导致程序性能有所下降,可改善整合统计单词和统计词组部分。
2.在分割词组时,采用逐字符读取,使用循环数组保存单词和分隔符,如改善使用正则匹配,性能应该会有所提升。
3.在统计长文件时,字符数会和他人有所不同(貌似一人一个答案),寻求了解决方案后发现好像是由于存在非ASCII码的原因,改善问题不在此次作业范围内。
4.其余部分在个人作业时,所表现的性能还是比较好的,暂时没有改善的思路。
- 代码覆盖率
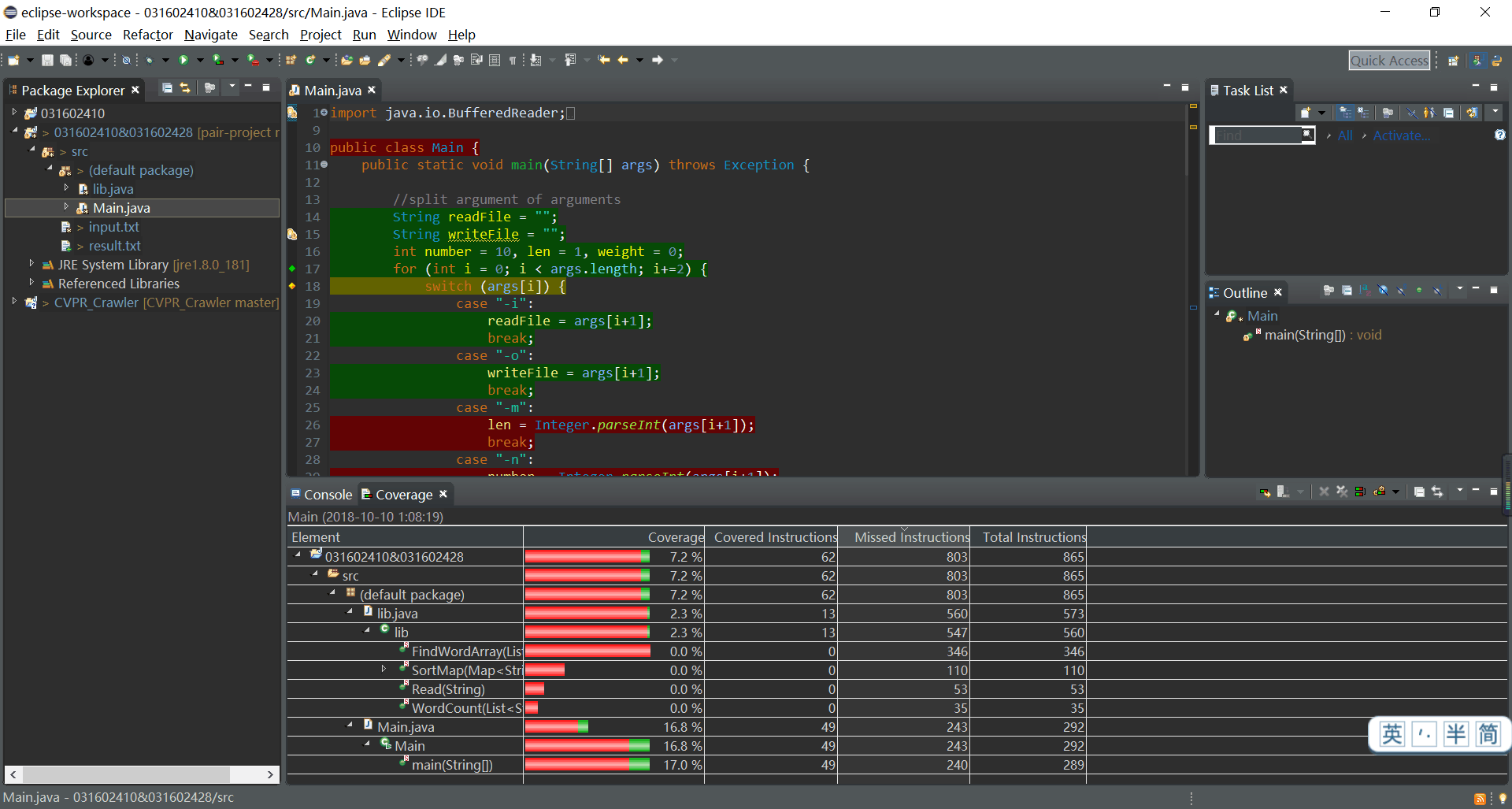
- 性能测试
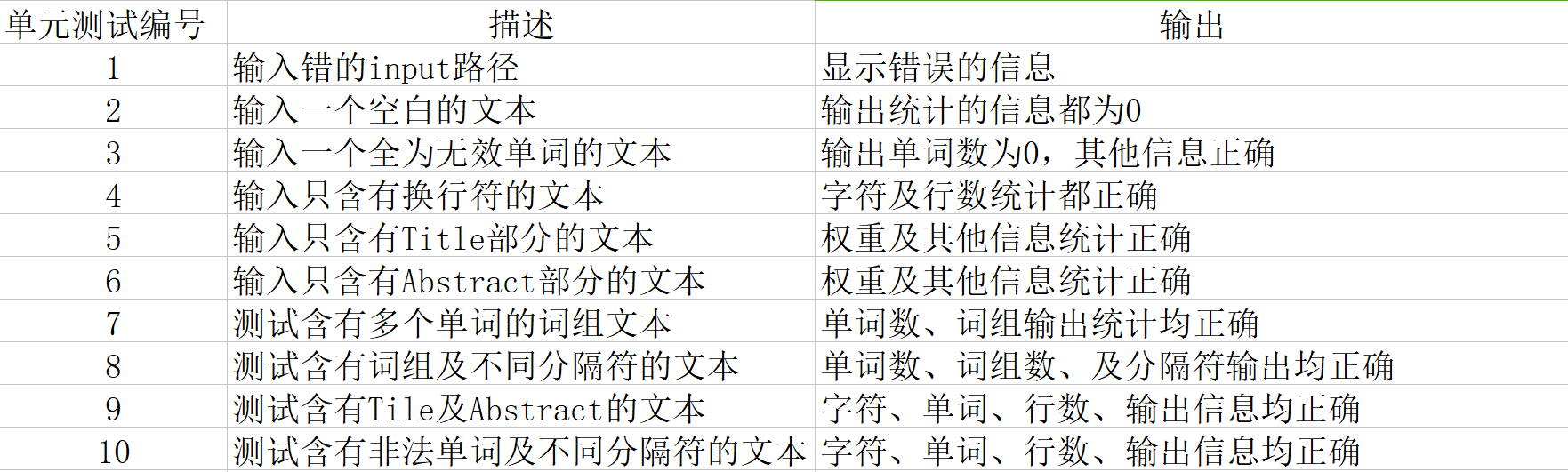
##八、单元测试
以下为我进行的单元测试,包含大概的描述和输出的信息
##九、Github的代码签入记录

##十、遇到的代码模块异常或结对困难及解决方法
- **问题描述**:
1.使用python进行爬虫时有时候缺少部分内容
2.使用正则分割去出单词时,无法保留最后需输出的分隔符
- **做过哪些尝试**:
1.
·对代码进行查错
·上网查询类似问题及解决方法
·对代码进行改进
2.
·对正则进行更多学习了解
·使用其他方法进行分割保留分隔符
- **是否解决**:
·重新学习写一个java的爬虫
- **有何收获**:
·解决一个问题的时候,如果一种方式怎么样都做不到,解决不了,可以尝试换一种方法来解决
##十一、我的队友
我的队友是真的牛,什么都会,我写到不会的或者有缺少的,他都会告诉我,超级厉害的。
##末:学习进度条
|||||||
|:--|:--|:--|:--|:--|:--|
|**第N周**|**新增代码(行)**|**累计代码(行)**|**本周学习耗时(小时)**|**累计学习耗时(小时)**|**重要成长**|
|1|500|500|10|30|eclipse的新学习,发现熟悉更多新方法|
|2|0|200|4|10|了解api,学习新用法新接口新类|
|3|0|300|12|12|加深掌握了Axure的使用,学会了使用NABCD模型进行需求分析|
|4|200|200|10|10|学会简单的java爬虫|
|5|200|200|10|40|eclipse的新学习,发现熟悉更多新方法|