在机器学习的面试中,能不能讲清楚偏差方差,经常被用来考察面试者的理论基础。偏差方差看似很简单,但真要彻底地说明白,却有一定难度。作者能力有限,只能讲解到这种程度,欢迎大家指正。
-
模型与训练模型的概念
-
偏差和方差概念举例
-
偏差和方差分解
-
打靶图讲解
-
高偏差和高方差的解决办法
-
如何判断模型处于高偏差还是高方差
1、模型与训练模型的概念
- 模型与训练模型
这个概念如果没有搞清楚,后面的一切都是空谈。我们每次使用一个训练集训练出一个“模型”,其实应该叫做训练模型。因为每次更换训练集,训练出的“模型”并不一样,即各个训练模型被训练出来的参数(系数)是不一样的。
举个例子,我们在拟合一个y=ax+b的模型,第一个训练集训练的结果是y=x+0.9,第二个训练集训练的结果是y=x+1……因为我们不可能得到用于训练这个模型的所有数据,也就无法训练出使模型y=ax+b理论上100%正确的参数,所以我们只能得到不同的训练模型。
既然我们永远无法训练出那个理想的模型,只能训练出训练模型,那么训练模型预测的结果和理论模型(即现实)的结果肯定就存在误差。我们肯定希望这个误差越小越好,并且将这个训练模型应用在其他数据集上的误差也是越小越好。那么问题来了,如果这个误差很大,我们该如何是好?
- 要收集更多的训练数据么?
- 需要抽取更多的数据特征么?
2、偏差和方差概念举例
假设我们要训练一个股票市场的模型,模型的目标是预测某支股票第2天的收益率,如果收益为正则买入,反之则卖出。我们的模型天天都想发财,它希望能准确预测每一天的涨跌,所以它关注的是第二天的收益,什么一年翻一倍之类的中长线策略它根本不关心。
- A模型:阅读了大量的巴菲特,彼得林奇等等各种大师的书籍和数据,它发现买入低估值股票的收益很可观,于是每天满仓杀入估值最低的N支股票。没过几天,它亏成了狗。它去质问股神,股神曰:“你把投资想象的太简单了,除了看估值,我还看很多其他指标”。
- B模型:吸取A模型的教训,它罗列了各种稀奇古怪的指标,最终惊喜的发现,模型成功的预测某支股票第二天的收益。万分惊喜下,它满仓杀入。第三天,第四天,第N天过去了,模型有时预测的准确,但大多时候谬之千里,还是亏成了狗。
上面训练的2种模型,和我们期待的“神预测”模型有很大误差。我们要想减少预测误差,就要分析造成误差的原因。这里的误差包含:
- 偏差(bias):我们要预测第二天的收益,而估值指标经常用于长线投资,虽然每次预测都是信誓旦旦,但是模型从本质上就把目标搞错了。
- 方差(variance):过多的已知条件,导致模型无法给出确定的预测,预测结果和瞎蒙一样,给人的感觉是不靠谱。
- 无法消除的误差:我们都知道,完美预测第二天的情况,是不可能的。这样的误差难以消除,我们希望它越小越好,一般就忽略掉了。
所以,我们可以优化的误差=偏差+方差
3、偏差和方差分解


4、打靶图讲解

我第一次看到这张图时,把图上的蓝点理解成了每次射击时的结果,即一个训练模型对不同输入X作出的不同预测Y。如果是这么理解的话,就没法解释后面的高方差了。其实,每一个蓝点,都代表了一个训练模型的预测数据,即根据不同的训练集训练出一个训练模型,再用这个训练模型作出一次预测结果。如果将这个过程重复N次,相当于进行了N次射击。我们假设真实的函数关系是Y=f(x),而训练模型预测的结果是p(x),则
- 偏差错误:偏差是衡量预测值和真实值的关系。即N次预测的平均值(也叫期望值),和实际真实值的差距。所以偏差bias=E(p(x)) - f(x)。
即bias是指一个模型在不同训练集上的平均表现和真实值的差异,用来衡量一个模型的拟合能力。 - 方差错误:方差用于衡量预测值之间的关系,和真实值无关。即对于给定的某一个输入,N次预测结果之间的方差。variance= E((p(x) - E(p(x)))^2)。这个公式就是数学里的方差公式,反应的是统计量的离散程度。只不过,我们需要搞清楚我们计算的方差的意义,它反应的是不同训练模型针对同一个预测的离散程度。
即variance指一个模型在不同训练集上的差异,用来衡量一个模型是否容易过拟合。
- 高偏差,低方差:
每次射击都很准确的击中同一个位置,故极端的情况方差为0。只不过,这个位置距离靶心相差了十万八千里。对于射击而言,每次都打到同一个点,很可能是因为它打的不是靶心。对于模型而言,往往是因为模型过于简单,才会造成“准”的假象。提高模型的复杂度,往往可以减少高偏差。 - 高方差,低偏差:
是不是偏差越低越好?是不是低偏差时,方差也会低呢?通过对偏差的定义,不难发现,偏差是一个期望值(平均值),如果一次射击偏左5环,另一次射击偏右5环,最终偏差是0。但是没一枪打中靶心,所以方差是巨大的,这种情况也是需要改进的。
5、高偏差和高方差的解决办法
一般来说,当一个模型在训练集上的错误率比较高时,说明模型的拟合能力不够,偏差较高。
欠拟合(高偏差)的解决办法:
- 增加数据特征
- 提高模型负责度
- 减少正则化系数
当模型在训练集上的错误率比较低,但验证集上错误率比较高时,说明模型过拟合,方差比较高。
过拟合(高方差)的解决方法:
- 减低模型复杂度
- 加大正则化系数
- 引入先验知识
- 使用集成模型,即通过多个高方差模型的平均来降低方差
6、如何判断模型处于高偏差还是高方差
当我们了解了高偏差和高方差的含义以及解决方式,接下来讲解如何判断模型处于高方差还是处于高偏差,这就需要学习曲线的帮助。
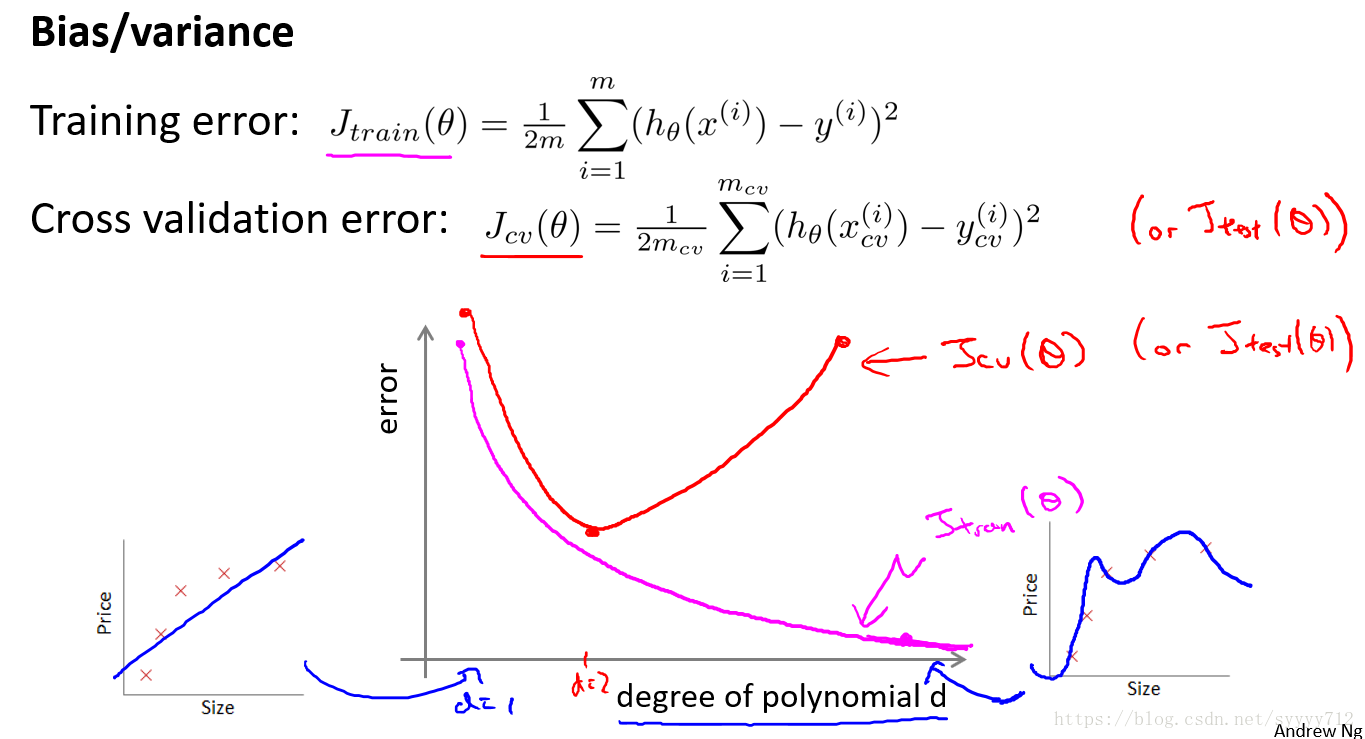
从上述这幅图中可以看到,横坐标是多项式的次数,纵坐标是误差,可以看出粉红色线为训练误差随着多项式次数的增加越来越小,大红色线为交叉验证集误差曲线,类似于二次函数曲线,在曲线图左边,训练集误差和验证集误差均很大,说明训练集和验证集均拟合的不是很佳,因此处于欠拟合状态即(高偏差),在最右边,训练集拟合的很好,但是验证集误差很大,说明模型的泛化能力很差,只认识看到过的数据集,不认识没看到的数据集说明处于模型处于高方差问题。因此通过该条曲线可以大概选择出最佳的多项式次数。
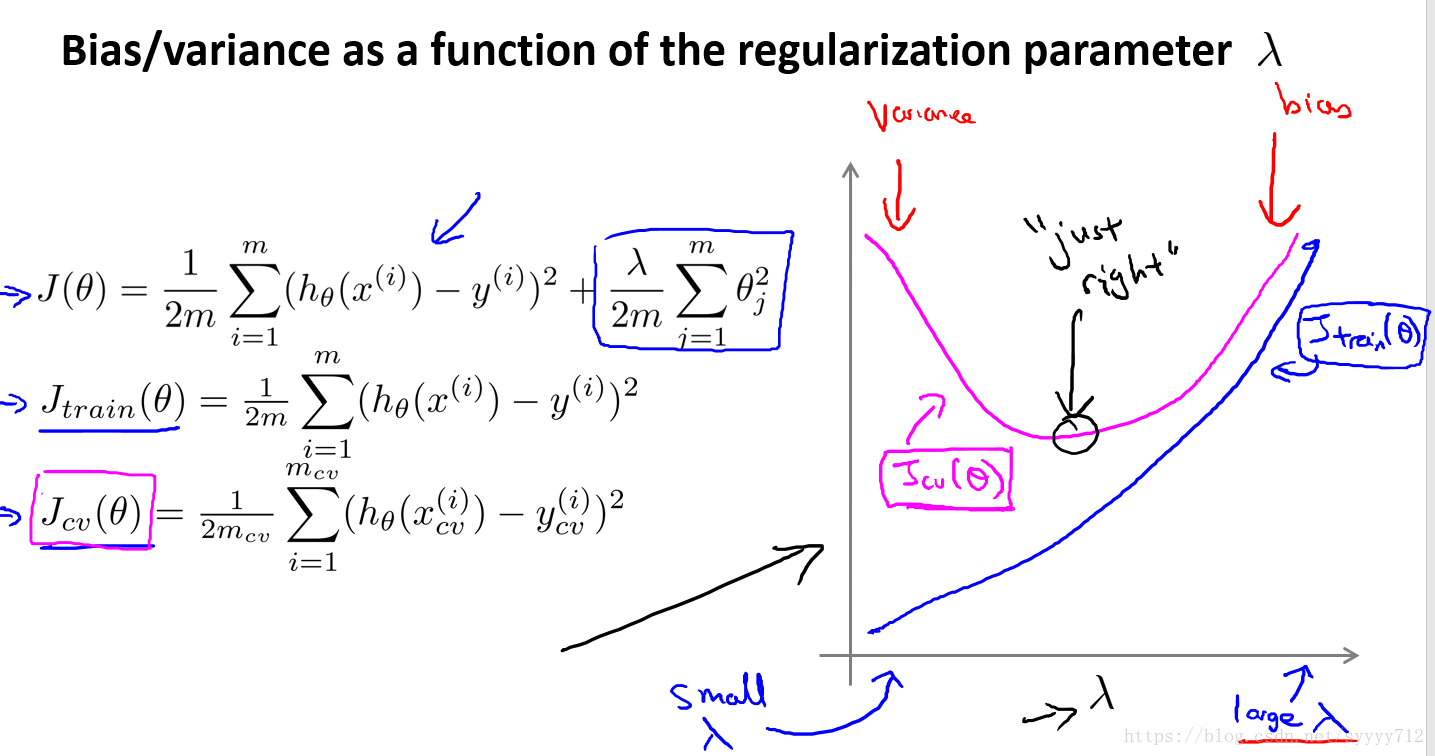
在上述解决办法中提到了修改lamda值可以解决高偏差高方差问题,下图即是lamda值和两者之间的关系,
 在实际的cost function函数中是没有正则化项,但是为了防止过拟合而加入了正则化项,目的是降低多项式中的权重(见以下两个公式),以使得模型变得简单,
在实际的cost function函数中是没有正则化项,但是为了防止过拟合而加入了正则化项,目的是降低多项式中的权重(见以下两个公式),以使得模型变得简单,
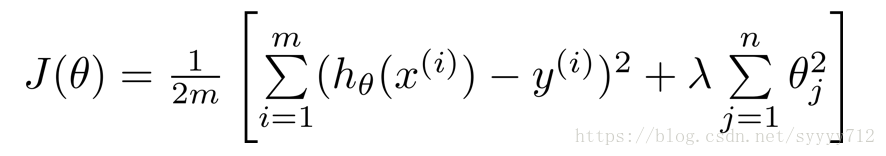
 因此对于lamda越大针对训练集拟合的越差因此训练集误差会上升,而验证集一开始下降后来上升,lamda越大会使得模型变得简单容易出现欠拟合,lamda越小会使得模型出现过拟合,因此对于高偏差可以降低lamda值使模型变得复杂,对于高方差可以增加lamda值使模型每一项权重降低从而变得简单。
因此对于lamda越大针对训练集拟合的越差因此训练集误差会上升,而验证集一开始下降后来上升,lamda越大会使得模型变得简单容易出现欠拟合,lamda越小会使得模型出现过拟合,因此对于高偏差可以降低lamda值使模型变得复杂,对于高方差可以增加lamda值使模型每一项权重降低从而变得简单。
最后一组曲线是数据集的大小对高偏差和高方差的影响:
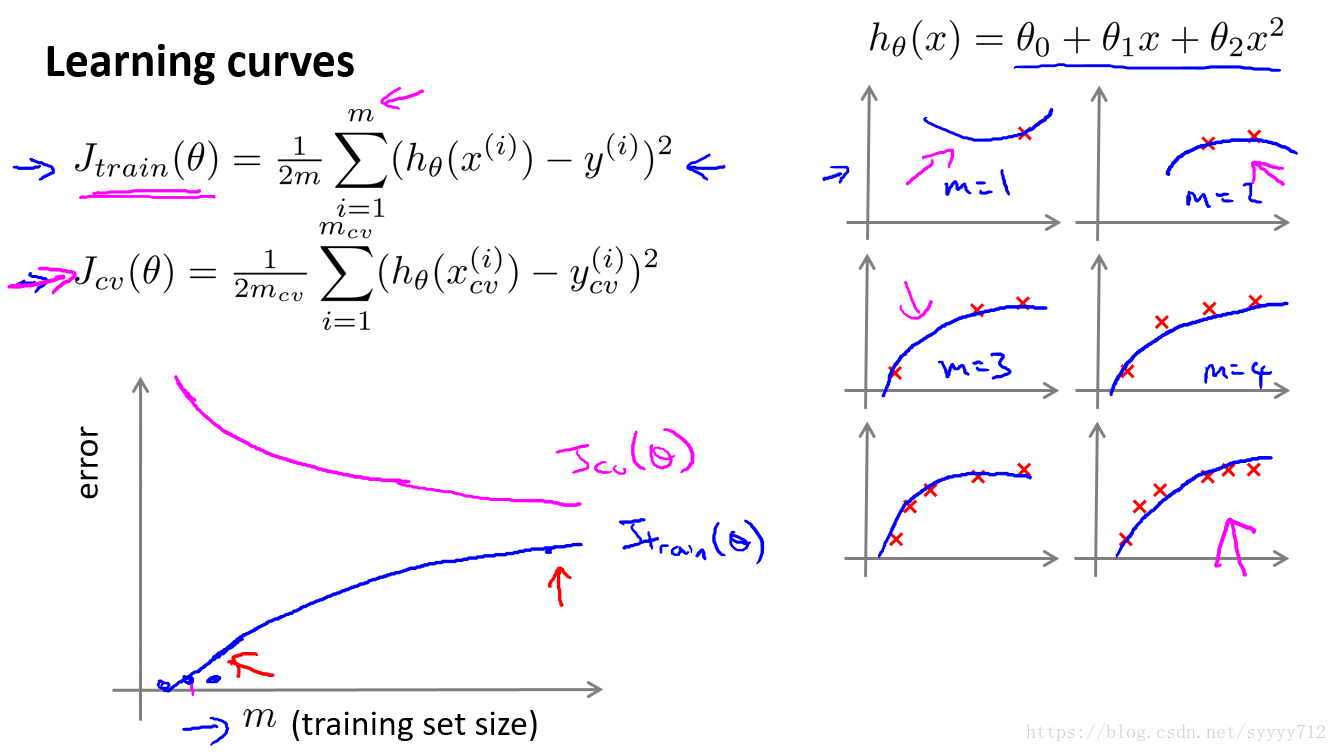
随着数据集的增加,模型的拟合越来越困难,因此训练集误差会有所上升,而对于验证集,随着数据的增加,模型的泛化能力越来越强,验证集误差会有所下降。但是验证集误差值不会低于训练集,因为训练集是模型能见到的数据,而验证集对模型来说是新数据。
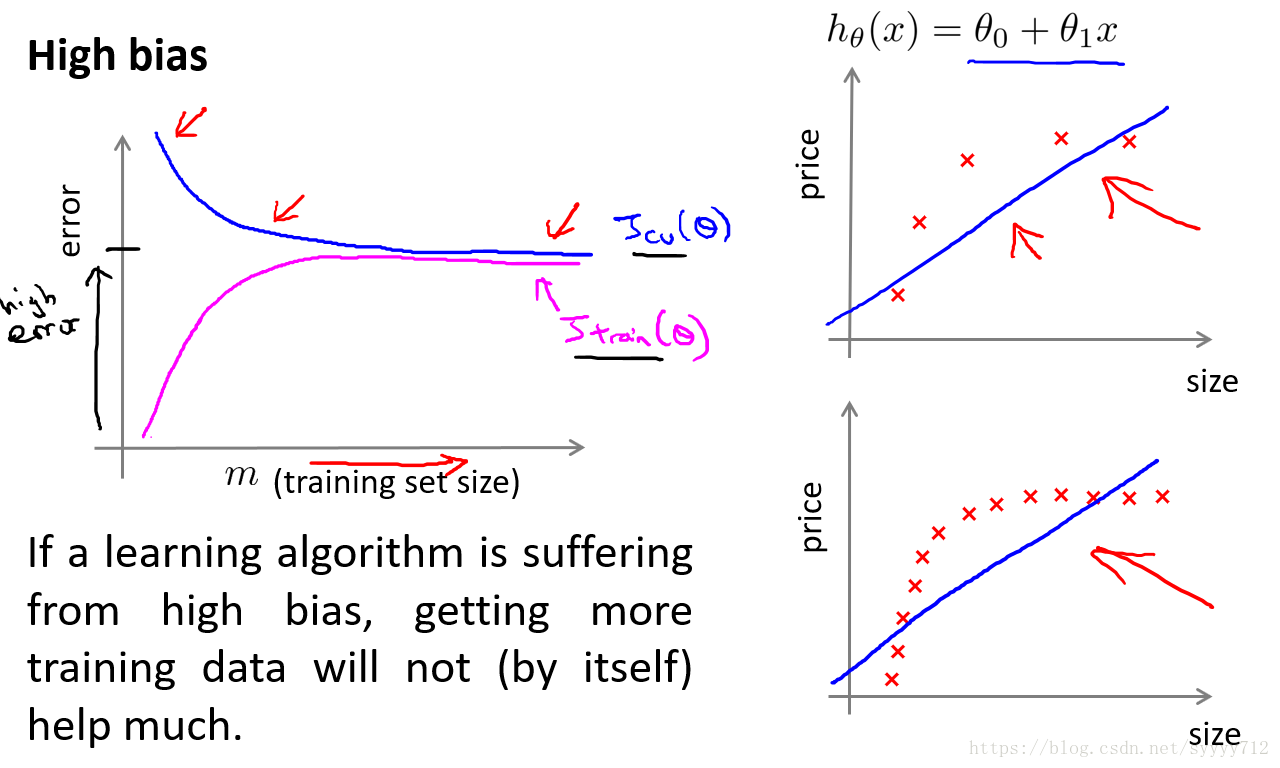
对于高偏差问题,说明模型存在欠拟合,当数据集增加的时候训练集误差一定会上升,因为模型欠拟合,数据集增多,模型还是拟合很困难,但是在改善,因此验证集会有所下降,但是最后的误差都会很大,而且训练集误差和验证集误差会很相近并且数值很大,因此对于高偏差增加数据集会徒劳无用。
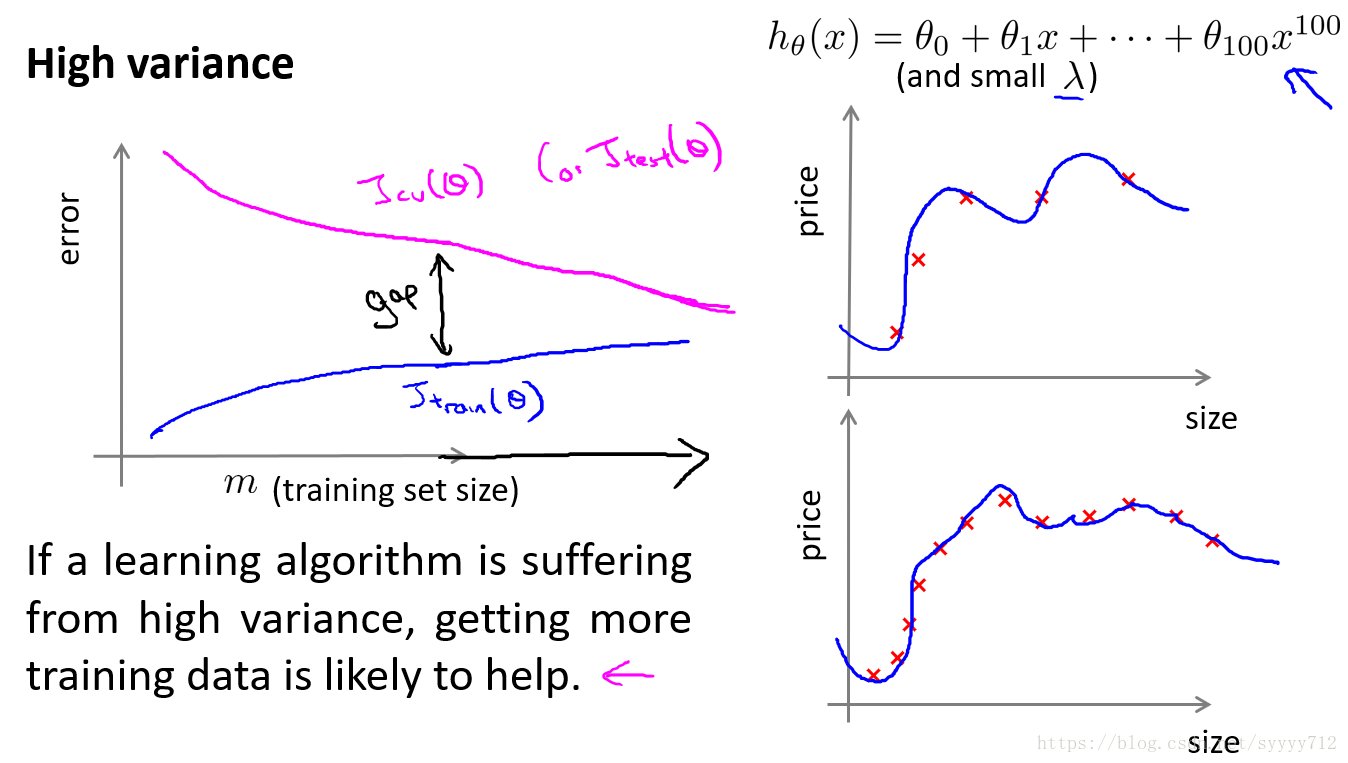 针对高方差问题,模型对于训练集拟合的很好,但是泛化能力太差,因此验证集和训练集的误差值会增加,但是随着数据集的增加,模型越来越困难拟合每一个点,提高一定的泛化能力,最后会使得验证集和训练集误差慢慢接近,因此针对高方差问题可以增加数据集提高模型泛化能力。
针对高方差问题,模型对于训练集拟合的很好,但是泛化能力太差,因此验证集和训练集的误差值会增加,但是随着数据集的增加,模型越来越困难拟合每一个点,提高一定的泛化能力,最后会使得验证集和训练集误差慢慢接近,因此针对高方差问题可以增加数据集提高模型泛化能力。
————————————————
参考文献:
1、https://blog.csdn.net/syyyy712/article/details/79960726