
目录:
- 相关链接
- 方法亮点
- 相关工作
- 方法细节
- 实验结果
- 总结与收获
相关链接
论文:https://arxiv.org/abs/1803.02077
代码:https://github.com/roimehrez/contextualLoss
方法亮点
- 文章主要提出了一个新的损失函数Contextual Loss,这个loss一开始是针对Non-Align Data提出的损失函数。主要通过计算图像特征的相似度来衡量两张图片的相似性。
最令人惊艳的是,使用该损失函数,一个简单的CNN网络就能够达到和CycleGAN一样的效果。
作者在紧接着的论文中也证明了该损失函数在一对一图像超分中也能取得不错的结果。
相关工作
目前针对loss的研究有很多,在今年ECCV上收录的文章中就可以看出来。
目前已有的loss主要有一下几种:
- 针对图像的pixel2pixel的loss:L1 , L2,SSIM
- 针对图像特征的loss:perceptual loss,Gram loss
- 针对生成图像和目标图像的“逼真”程度的loss:GAN loss
L1 , L2,SSIM这类损失函数对input 和GT 的要求比较高,是逐像素进行匹配的,对以PSNR、SSIM为客观评价指标的问题贡献比较大,但是从目前的研究来看,单单用这类损失函数,已经不能够满足我们的需求了。比如SRGAN这篇论文中提到MSE代价函数使重建结果有较高的信噪比PSNR,但是缺少了高频信息,出现过度平滑的纹理。perceptual loss的提出主要是为了更好的保留图像的高频信息https://www.jianshu.com/p/58fd418fcabf,与perceptual loss相似的,Gram loss也是计算在特征层上的损失,这两个损失都是在整个VGG网络中得到的特征层进行的计算,约束的是全局高频特征的相似性;然而图像的相似性一般是局部的,这些约束也不是十分的合理,本文的方法提出的损失函数约束的是局部的特征。在风格转换、图像翻译等任务中,GAN loss是一个常见的损失函数,通过简单的判断生成的图像是否“逼真”到以假乱真的程度,但是GAN的模式崩溃问题到目前都没有一个较好的解决办法。
方法细节

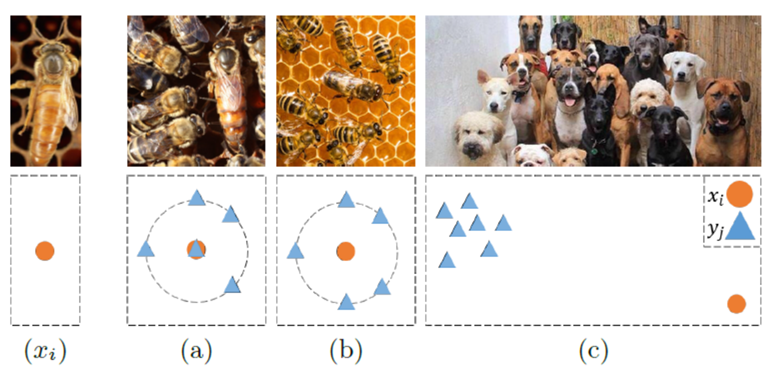
两张图片要怎么判断是否相似呢?作者认为只要两张图片的特征中,相同区域的大部分特征能找到彼此相似的点就可以认为两张图片是相似的。如图3(a),两张图像同一区域的特征块中大部分是相似的(与点在特征图块的位置无关,只要能相似即可),就可以认为两张图像相似。这跟perceptual loss最不同的就是perceptual loss是跟特征的位置相关的(位置按点一一对应起来)。
在这篇文章中,作者利用了余弦相似的方法,通过计算特征之间的余弦距离衡量两个特征的相似性。
具体计算方法如下:
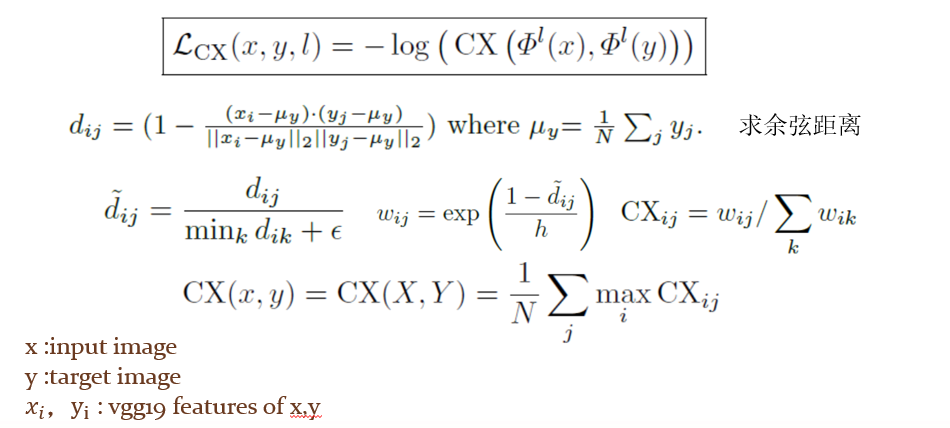
其中的xi ,yj 为1*1*Channel大小的特征向量,N为特征patch大小
实验结果
作者通过一系列的实验来验证他们提出的损失函数的有效性;

图6的实验:一张噪声图像(input)和多张清晰图像(GT)(数据采集方法为,一张高清图像中裁剪出N+1张图片,每张图片的采集的位置随机小偏移,对其中一张图片加入噪声作为input,其他N张图片作为GT),从图6可以看出,由于随机偏移的存在,如果单纯的使用L1 损失(位置相关)的话,会引入模糊而使用本文提出的损失函数并不会引入模糊。并且我们训练的时候并不需要指定一张GT和input进行训练,每一轮的GT都可以是不一样的。(即Non-paired)
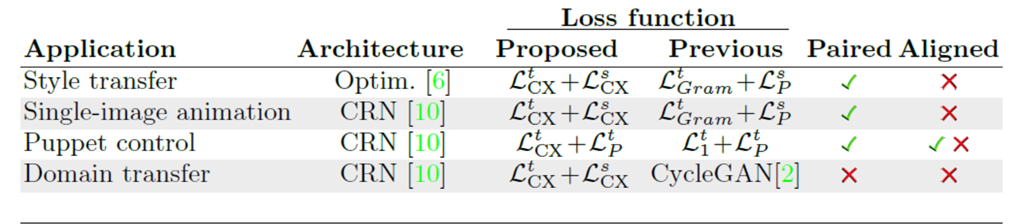
本文还通过修改一些经典方法的损失函数与原有的方法进行对比,修改方式如下表所示:
style transfer:

从上面的结果对比中可以看出来,本文提出的方法学习的是局部的特征,而不是全局的特征。CNNMRF方法学习到的是图片的全局特征,将Target的背景信息也学习到了。

在上面这个实验中,本文的方法仅使用了一个简单的CNN网络和本文提出的损失函数就能够达到和CycleGAN(两个生成器和两个判别器)差不多的效果。
另外两个实验的结果是以动画的形式展现的,这里没法展现就不放出来了,有兴趣的可以下载原论文看。
紧接着作者将提出的损失函数应用到超分中,也取得不错的效果,这便是另外一篇文章的工作了。Maintaining Natural Image Statistics with the Contextual Loss
文章对比实验的设置如下:(其中我们的方法的网络结构是基于SRGAN,只修改了损失函数)
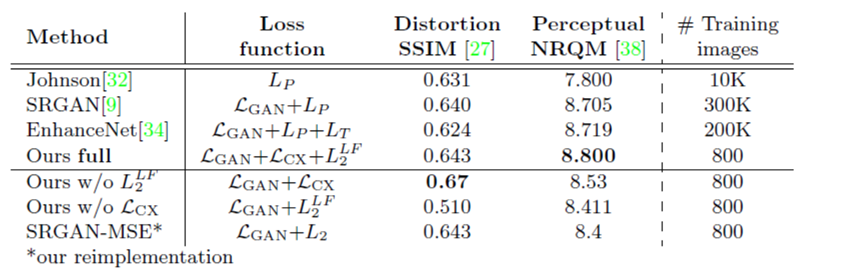
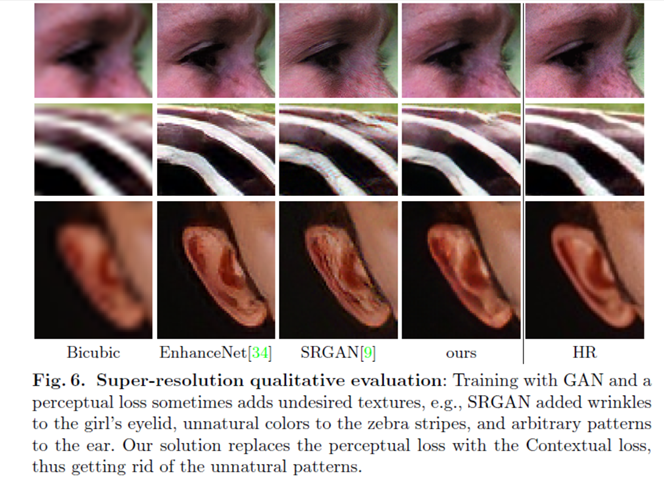
从上图中可以很直观的看出,引用了本文提出的损失函数,生成的图像更接近GT,而不会像baseline方法,在耳朵地方多出一些皱纹。并且加入本文的损失函数,不仅在客观指标上,在感知指标上均得到了很大的提升。
总结与收获
本文主要是提出了一个基于余弦相似度的损失函数,该函数应用在VGG提取的特征层上,与以往的损失函数最大不同的是,该损失函数应用在特征层相应位置上的patch块,而不是应用在整个特征。高层特征层一般包含的是图像的语义特征,也就是说文章的损失函数是基于语义的,这也就是本文的loss为什么Contextual Loss。应用该损失函数做图像风格转换任务,能够实现眼睛-》眼睛、嘴巴-》嘴巴等对应区域的风格转换。该损失函数目前看来可以应用的领域有很多,不仅仅局限于风格转换的任务,缺点大概就是计算量比16年提出的perceptual loss要来的高,不过这主要取决于特征的patch块(或对特征进行采样)的大小。从这个角度来看,perceptual loss算是 Contextual Loss 的一个特例。