原理:
完全二叉树和满二叉树:
1.满二叉树
满二叉树:在一棵二叉树中。如果所有分支结点都存在左子树和右子树,并且所有叶子都在同一层上,这样的二叉树称为满二叉树。
满二叉树的特点有:
1)叶子只能出现在最下一层。出现在其它层就不可能达成平衡。
2)非叶子结点的度一定是2。
3)在同样深度的二叉树中,满二叉树的结点个数最多,叶子数最多。
2. 完全二叉树
完全二叉树:对一颗具有n个结点的二叉树按层编号,如果编号为i(1<=i<=n)的结点与同样深度的满二叉树中编号为i的结点在二叉树中位置完全相同,则这棵二叉树称为完全二叉树。
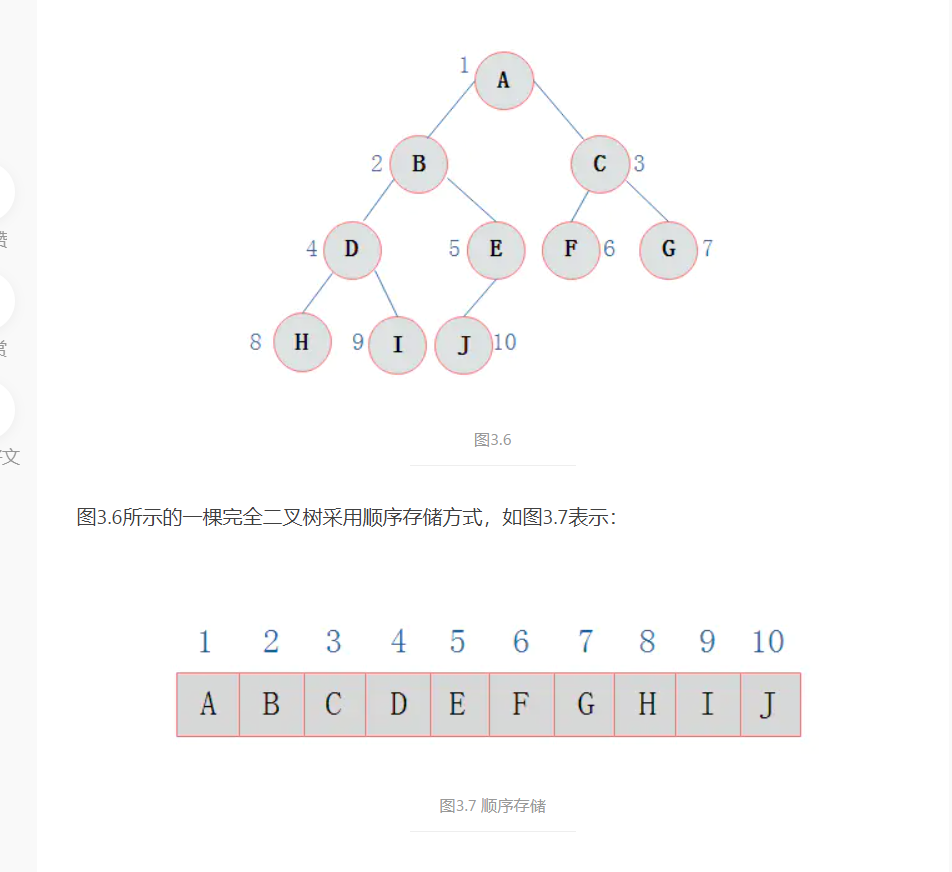
图3.5展示一棵完全二叉树
二叉树对于数据存储的实际意义:
1. 顺序存储
二叉树的顺序存储结构就是使用一维数组存储二叉树中的结点,并且结点的存储位置,就是数组的下标索引。
可以看到节点的阿拉伯标记数字和顺序存储的,索引位置的字母值存的一样,所以根据索引就可以快速找到对应树节点的值,
案例:
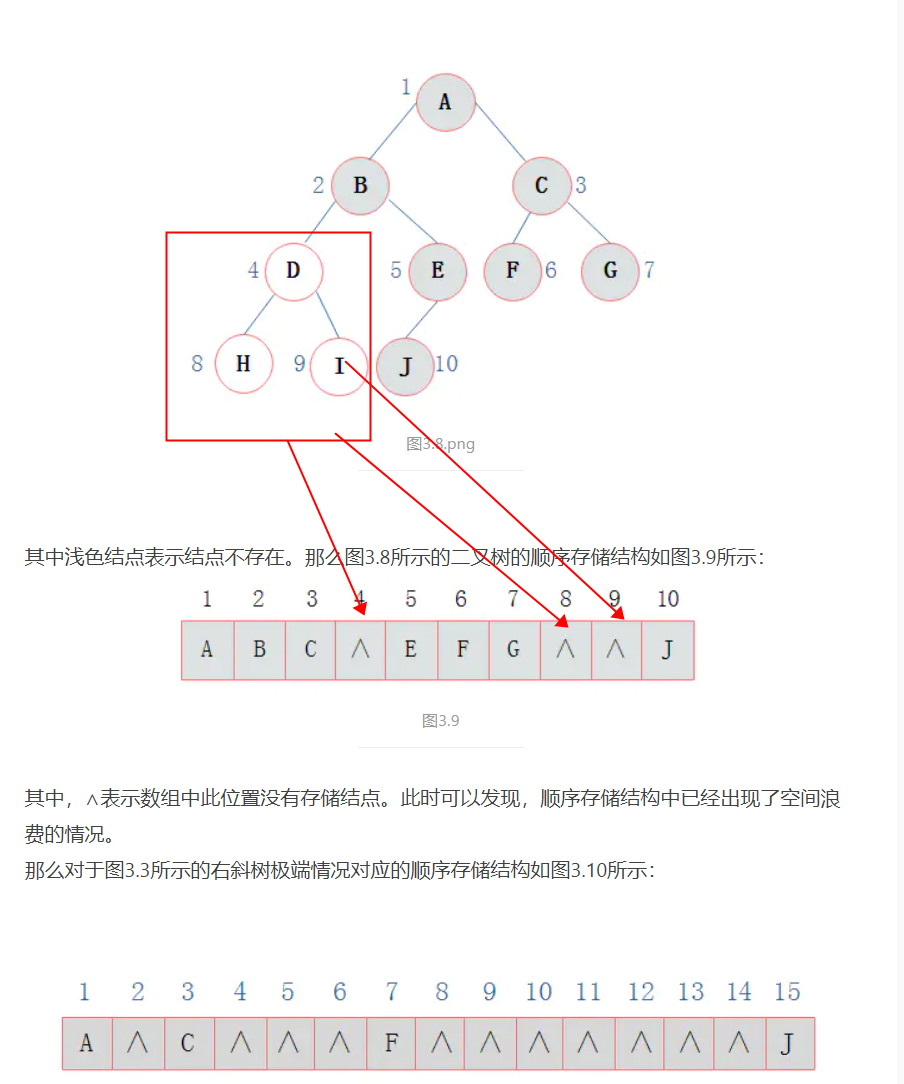
但是这样的数据结构建立在树必须是完全二叉树基础上,一旦不满足完全二叉树,就会出现存储空间浪费问题;所以这就引入了二叉链表
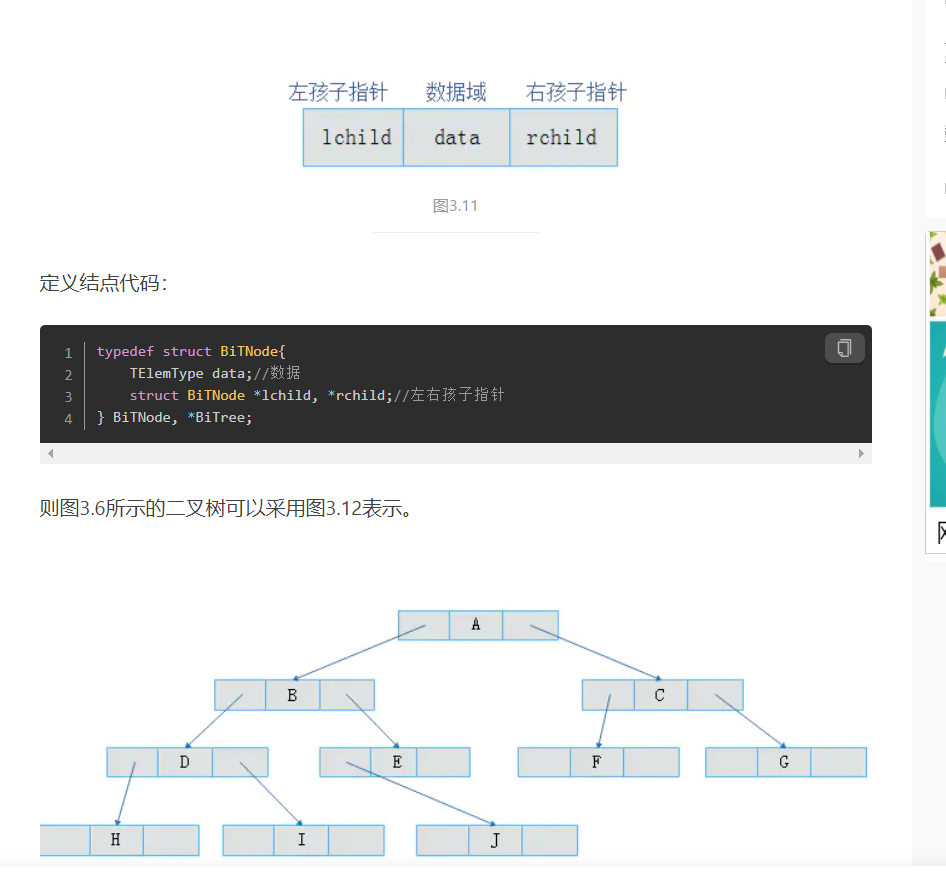
二叉链表
既然顺序存储不能满足二叉树的存储需求,那么考虑采用链式存储。由二叉树定义可知,二叉树的每个结点最多有两个孩子。因此,可以将结点数据结构定义为一个数据和两个指针域。表示方式如图3.11所示:
深度和广度优先和二叉树:
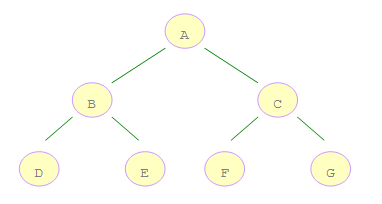
对于一颗二叉树,深度优先搜索(Depth First Search)是沿着树的深度遍历树的节点,尽可能深的搜索树的分支。以上面二叉树为例,深度优先搜索的顺序
为:ABDECFG。怎么实现这个顺序呢 ?深度优先搜索二叉树是先访问根结点,然后遍历左子树接着是遍历右子树,因此我们可以利用堆栈的先进后出的特点,
现将右子树压栈,再将左子树压栈,这样左子树就位于栈顶,可以保证结点的左子树要比右子树更早一步被遍历。
广度优先搜索(Breadth First Search),又叫宽度优先搜索或横向优先搜索,是从根结点开始沿着树的宽度搜索遍历,上面二叉树的遍历顺序为:ABCDEFG.
可以利用队列实现广度优先搜索。