1.先说下常规思路:
写追加模式,第一次写入头header,第二次开始:header =None
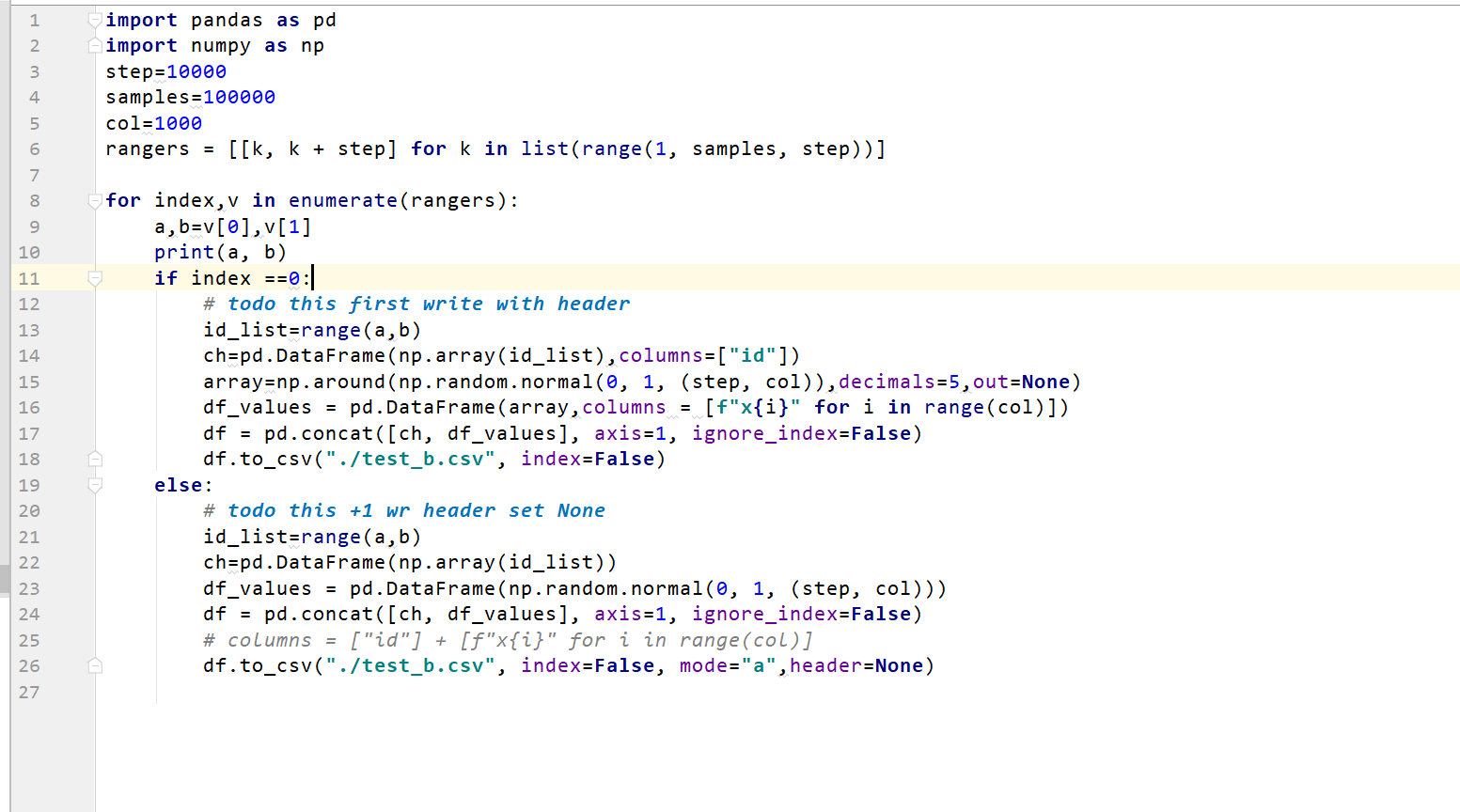
2.后来想了下,还是不够灵敏:id列不够随意,就用生成器来yield,不断批量batch_size 内存生成就返回,避免Memory Error:
d分两步:
第一步:
唯一id列:10w,sha256加密:
import csv
import uuid
from hashlib import sha256
import numpy as np
import argparse
import random,string
def gen_demo(rows:int, each_iter:int, features,mode_encrypt:int):
"""yield one batch_size data by each_iter size in case memory leak """
capacity = []
counter = 0
for i in range(rows):
temp = []
uid = str(uuid.uuid1()).replace("-", "")
if mode_encrypt:
encrypt = sha256(uid.encode("utf-8")).hexdigest()
else:
encrypt=uid+str(''.join(random.sample(string.ascii_letters+string.digits,10)))
if not features:
temp.append(encrypt)
else:
feature_value = np.around(np.random.normal(0, 1, features), decimals=5, out=None).tolist()
one_data = [encrypt] + feature_value
temp.extend(one_data)
capacity.append(temp)
counter += 1
if counter % each_iter == 0:
print(f" has gen {counter} data")
pass
yield capacity
def foo():
""" example: python generate_id.py -r 100000 -b 10000 -e 1"""
parse = argparse.ArgumentParser()
parse.add_argument("-e","--encrypt",type=int,required=True,help="encrypt 0 mean false,1 mean true ")
parse.add_argument("-r","--row",required=True,type=int,help="rows of samples")
parse.add_argument("-f","--features",required=False,type=int,help="number of cols generate features,if -f generate,else false")
parse.add_argument("-b","--batch_size",required=True,type=int,help="number of each time yield sample batch_size ")
parse.add_argument("-header","--header",required=False,type=bool,help="if generate header or not true mean yes, false no ")
parse.add_argument("-n","--name",required=False,type=str,help="the name of save output_data csv")
args = parse.parse_args()
if args.features:
features=args.features
else:
features=0
row = args.row
each_iter =args.batch_size
if args.name:
name=args.name
print("args name is %s"%name)
else:
name="id_sha256"
if args.header and features:
header = ["id"] + [f"x{i}" for i in range(features)]
else:
header=None # TODO if you want keep id_csv with id header, you can setting header=["id"]
encrypt_method=args.encrypt
data=gen_demo(row, each_iter, features, encrypt_method)
with open("./%s.csv"%name, "w", newline="")as f:
wr = csv.writer(f)
if header:
wr.writerow(header)
for dt in data:
wr.writerows(dt)
if __name__ == '__main__':
print("tip:
",foo.__doc__)
foo()
第二步:generate data and write to csv :
import pandas as pd
import numpy as np
import csv
from threading import Lock,RLock
lock=RLock()
# TODO __author__ ="Chen"
""">>>>10wx1000columns cost 143.43s <<<<< 10wx10columns cost 2.02s"""
# 特征列
col = 10
# generate samples rows numbers,must be the same with id_sha256.csv id rows
totals_row = 100000
# 每次yield分批的写入save_data output数量样本,suggest 2000 or 5000 or 10000 ,
batch_size = 10000
# data_output path for guest or host data_set
target_path = "./breast_b.csv"
# id_csv path
id_csv_path = "./id_sha256.csv"
# id_csv_path = "./ids_1sw.csv" # todo test id range(100000) int64
# with label,生成数据是否带有label
label_switch=True
if batch_size > totals_row:
raise ValueError(f"batch_size number can't more than samples")
def yield_id():
data_set = pd.read_csv(id_csv_path, chunksize=batch_size, iterator=True, header=None)
counter = 0
for it in data_set:
size = it.shape[0]
# print(f"yield id size is {size}")
a = list(map(lambda x: x[0], it.values.tolist()))
counter += size
print(f" has gen {counter} data")
yield a
def concat(with_label):
ids = yield_id()
for id_list in ids: # todo len(id_list)=batch_size
df_id = pd.DataFrame(id_list,columns=["id"],dtype=np.str)
value_a=np.around(np.random.normal(0, 1, (batch_size, col)), decimals=5, out=None)
df_feature = pd.DataFrame(value_a,columns=[f"x{i}" for i in range(col)])
if with_label:
df_y = pd.DataFrame(np.random.choice(2, batch_size),dtype=np.int64,columns=["y"])
one_iter_data = pd.concat([df_id,df_y, df_feature], axis=1,ignore_index=False)#.values.tolist()
else:
one_iter_data = pd.concat([df_id, df_feature], axis=1,ignore_index=False)#.values.tolist()
yield one_iter_data
def save_data(path,with_label):
""" if with label then generate dataout_put.csv with label y
feature_list = [f"x{i}" for i in range(col)]
if with_label:
header = ["id"] +['y']+ feature_list
else:
header = ["id"] + feature_list
<<<<
# with open(path, "w", newline="")as f:
# wr = csv.writer(f)
# if header:
# wr.writerow(header)
# for dt in one_batch:
# wr.writerows(dt)
"""
one_batch = concat(with_label)
for index,df_dt in enumerate(one_batch):
if index==0:
print(df_dt.dtypes,"
")
print(f"header of csv:
{df_dt.columns.values.tolist()}")
df_dt.to_csv(path,index=False)
else:
df_dt.to_csv(path,index=False,mode="a",header=None)
if __name__ == '__main__':
"""
before you generate data_output.csv to $target_path,you should run generate_id.py
to gen $totals_row numbers of id.then execute 'python generate_id.py -r 100000 -b 10000 -e 1' to gen data_output
"""
import time
start=time.time()
idsha256=pd.read_csv(id_csv_path,header=None)
id_sha256_rows=idsha256.shape[0]
if totals_row == id_sha256_rows:
pass
else:
raise ValueError(f"Sample total rows is {totals_row} must be the same with id_sha256.csv id rows size:{id_sha256_rows}")
save_data(target_path,with_label=label_switch)
print(time.time()-start)
测试了下:10wx10 column cost 2 s.
