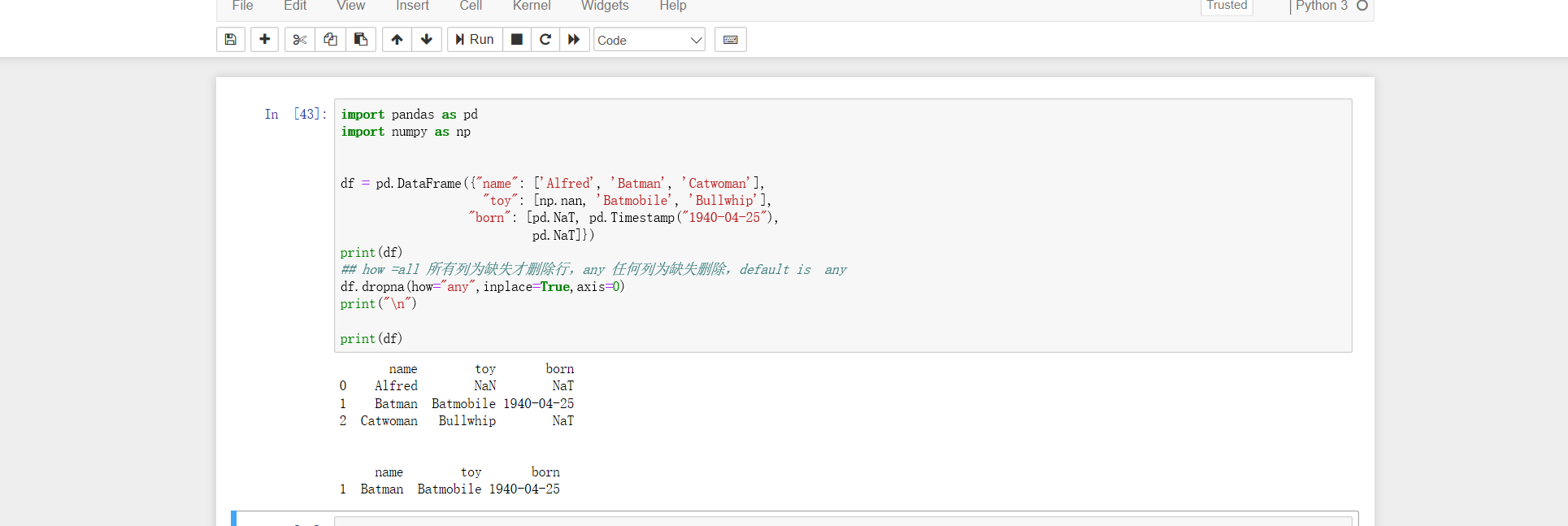
df.lookup()
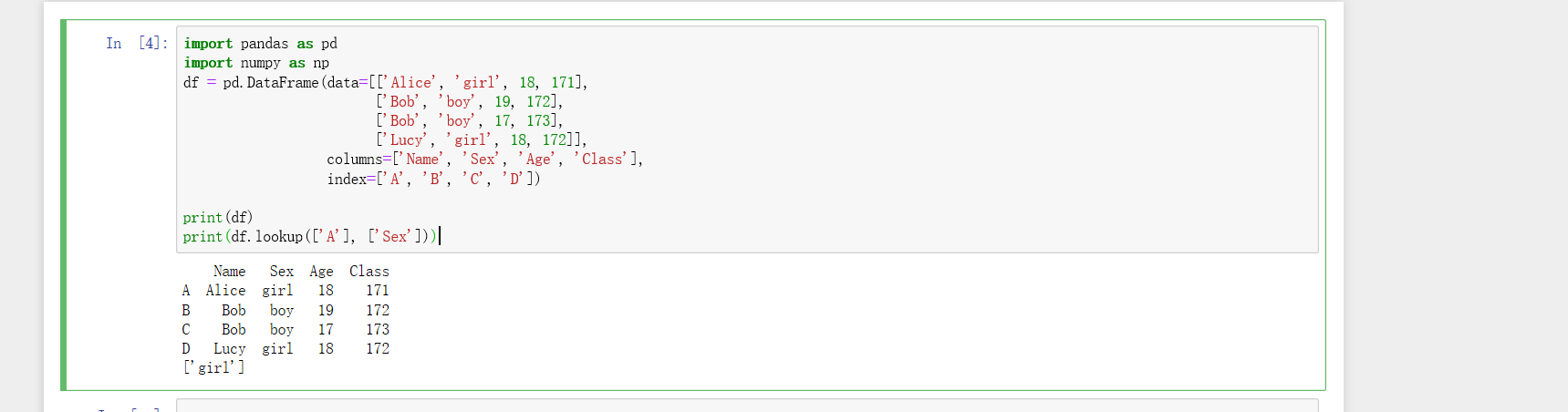
df.query():查询符合某个条件语句的 and or == != < > <= >=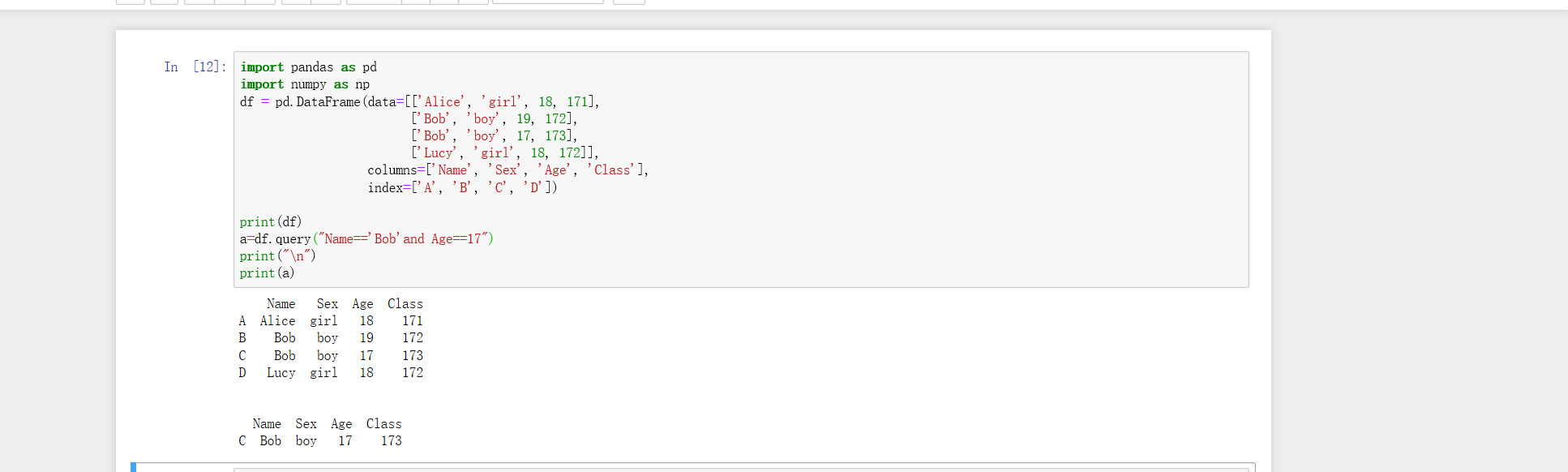
###添加一列的值等于df其中两列的加和
df[colname]=Series
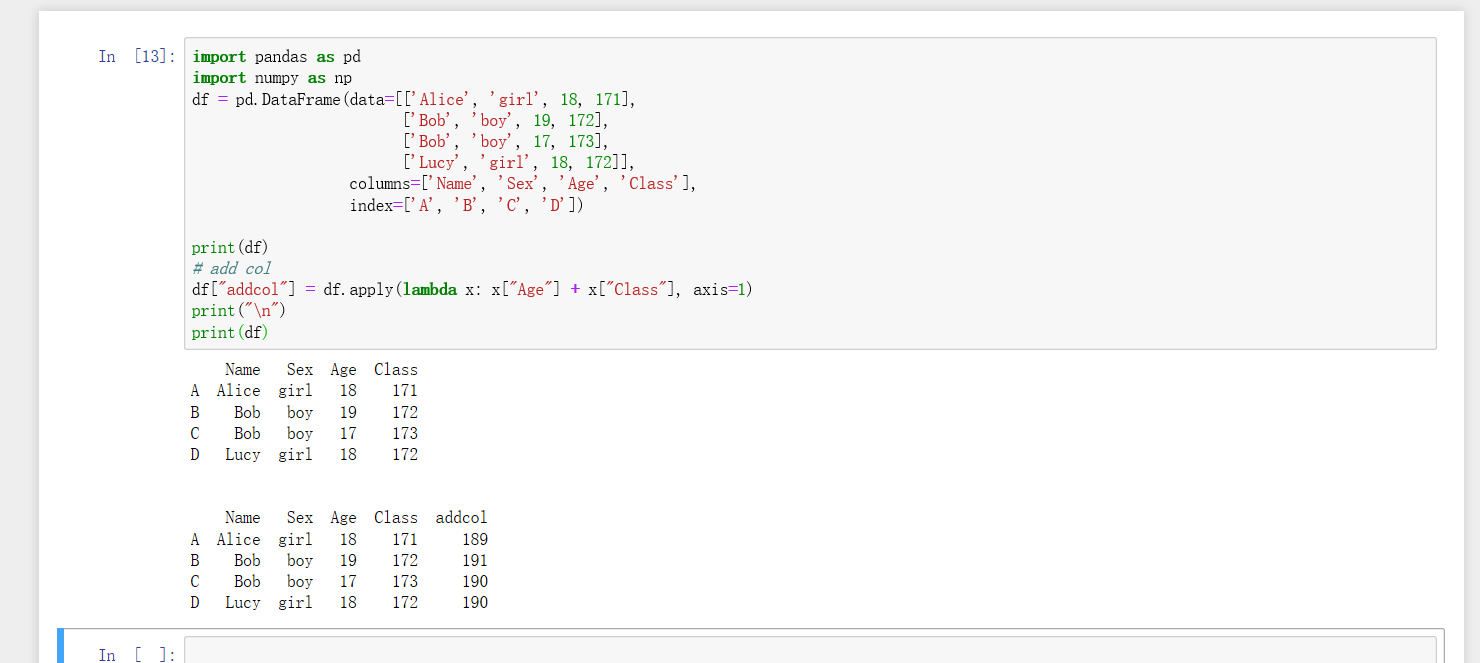
###add row :
df.loc[rowname]==series

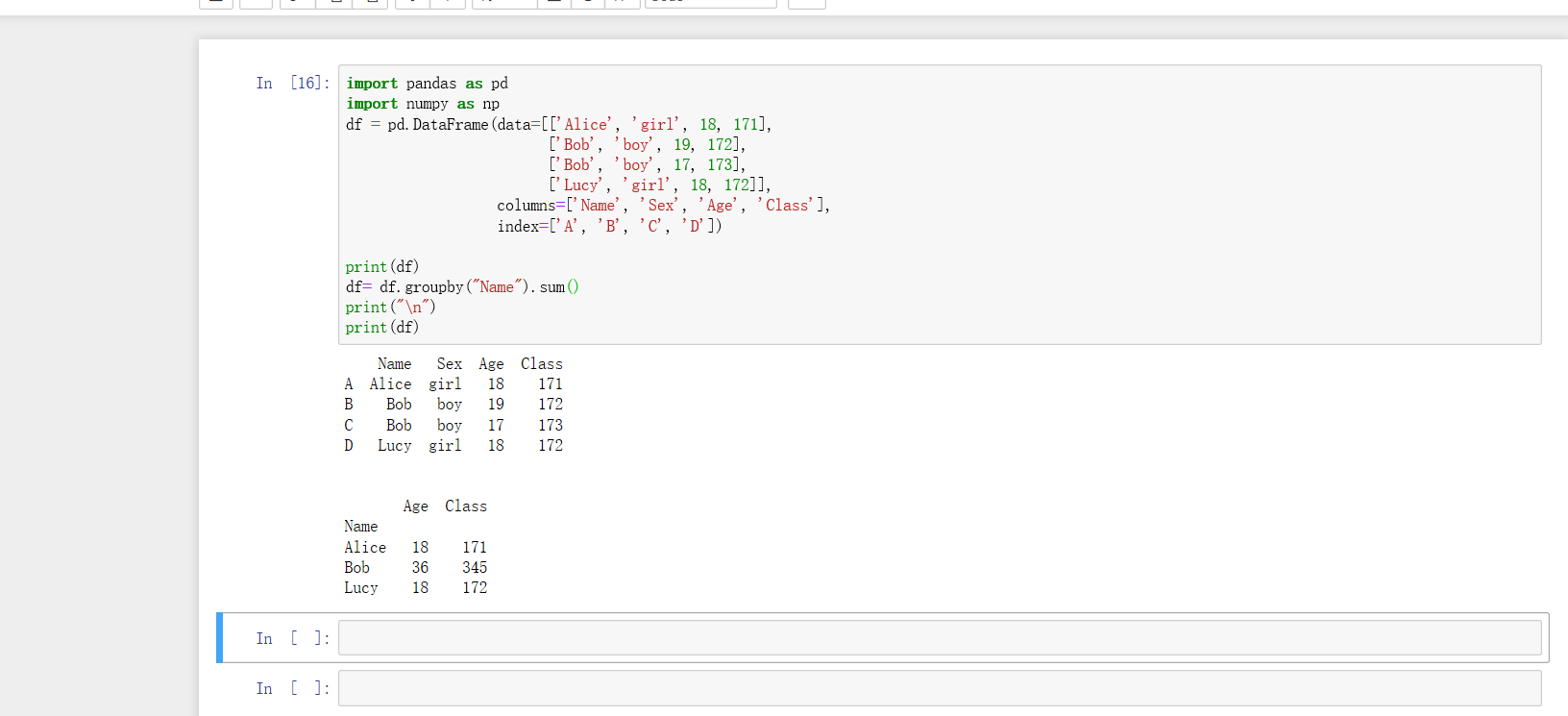
###分组求和
df.groupby():可以指定某列进行求和df.groupby("姓名")
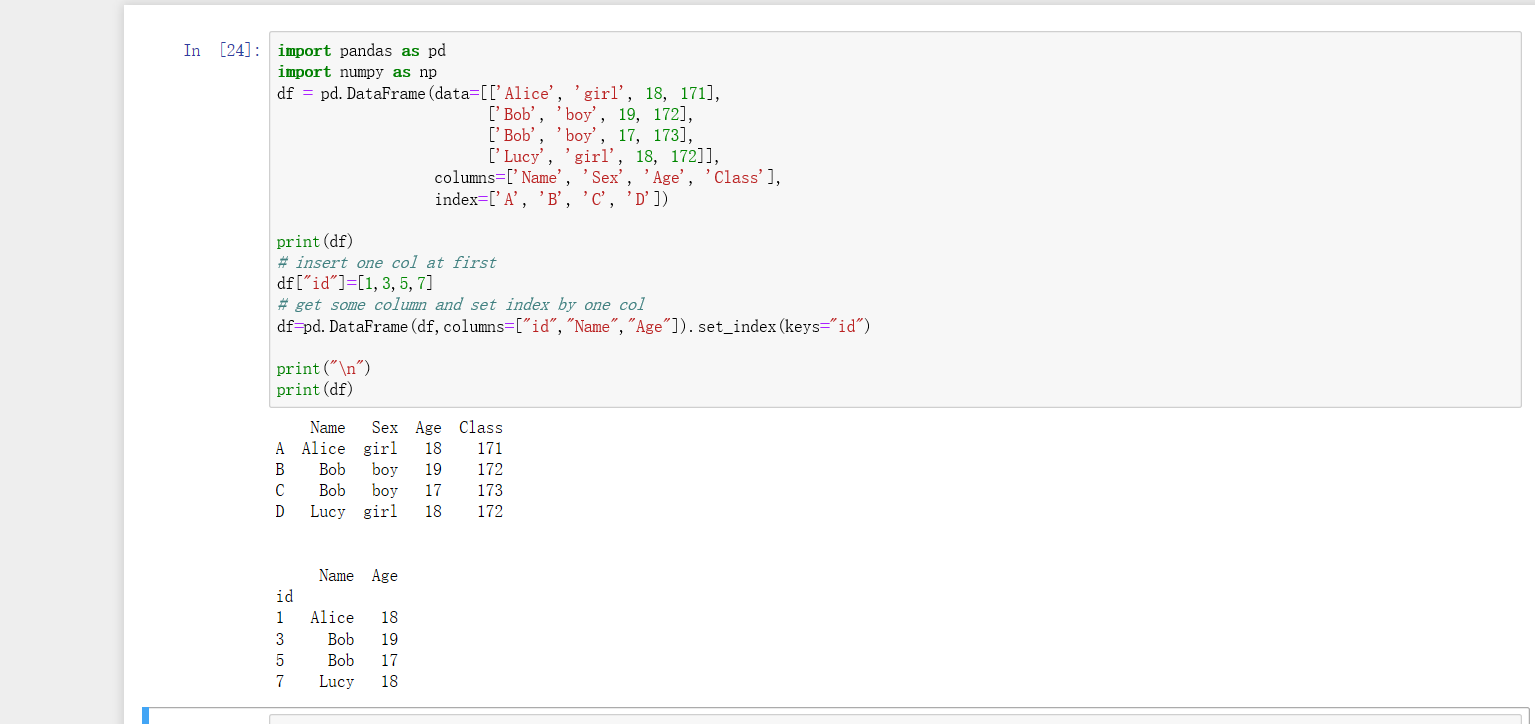
df插入一列在指定索引:
方法一:df.insert(0,colname,value)
# insert one col at first
df.insert(0,"id",value=[1,3,5,7])
方法二:
直接重排序列表,不推荐

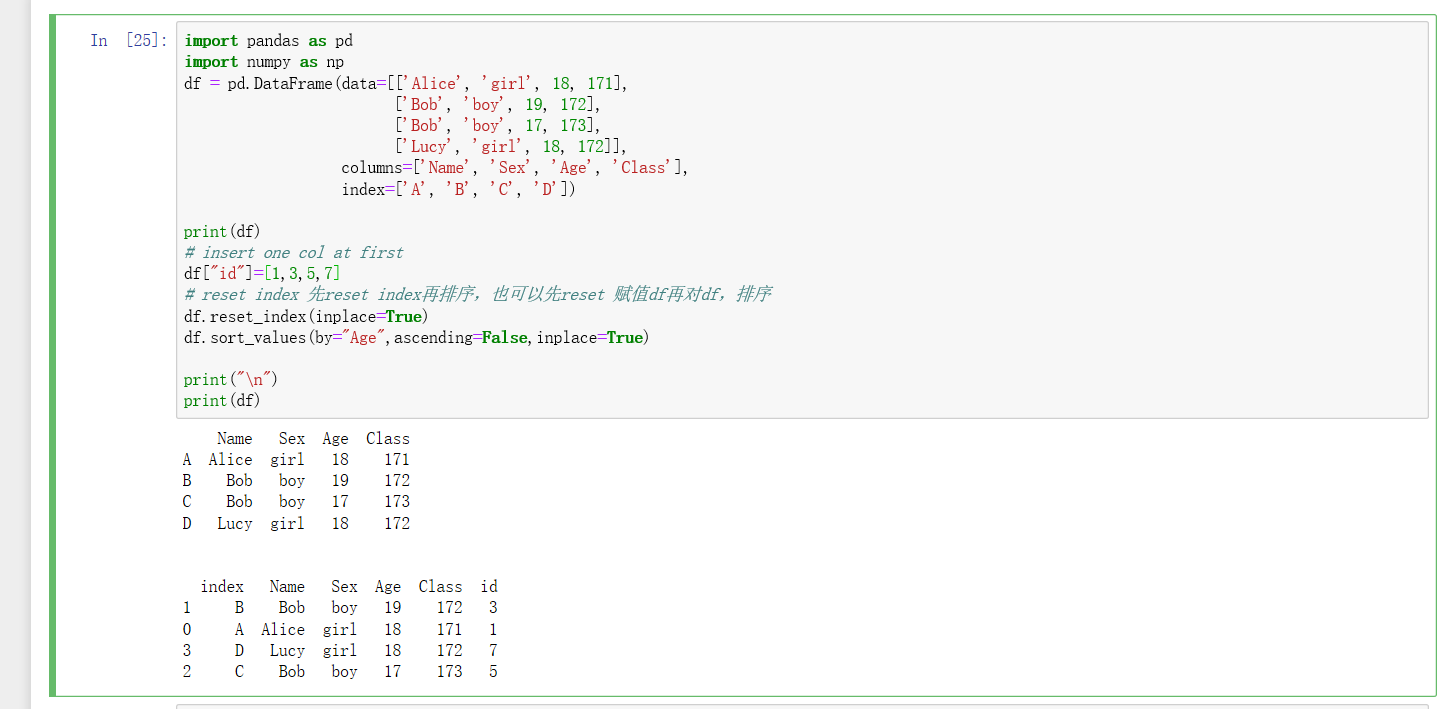
列转索引:
索引转列:
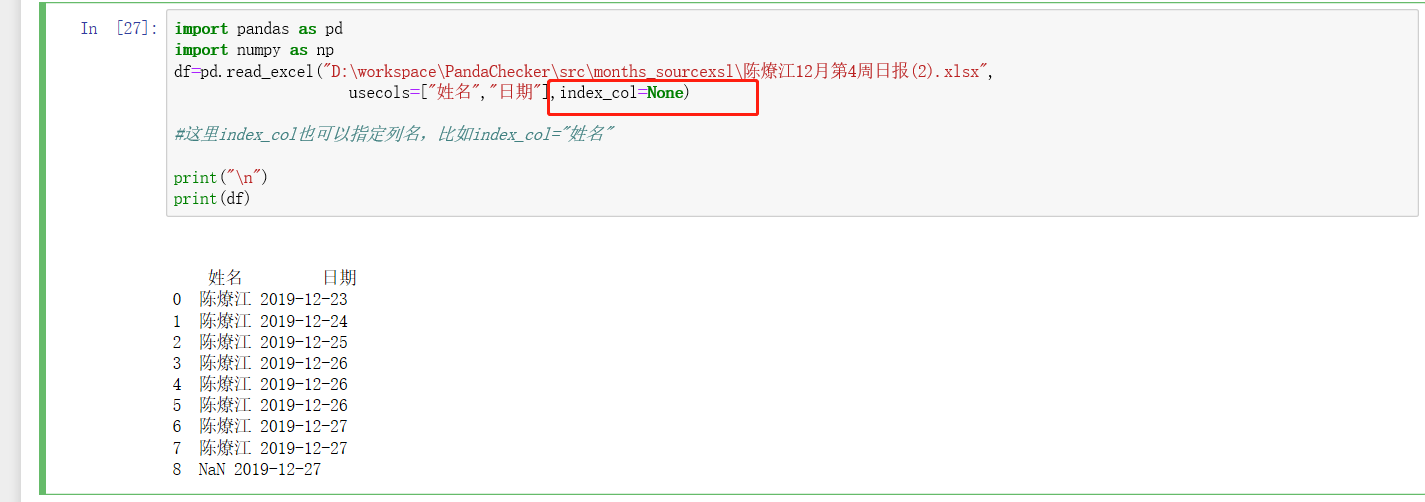
读取excel or csv,并指定索引:
index_col=0

index_col=None
日期列转换:
## 日期转换
df["日期"]=df.astype(np.datetime64)
####设置某列数据类型
pd.dataframe(dtype={"Name":str})

判断某几列是否存在符合条件的值:
df.姓名.isin([0, "0.0", "0", "", np.NAN, " "])
或判断
name_checker =df[
(df.姓名.isin([0, "0.0", "0", "", np.NAN, " "])) | (df.工作性质.isin([0, "0.0", "0", "", np.NAN, " "])) | (
df.项目组.isin([0, "0.0", "0", "", np.NAN, " "])) | (df.工作内容.isin([0, "0.0", "0", "", np.NAN, " "]))]
if not name_checker.empty:
logger.error(f"error description: {promote}, 捕获缺失格式错误{name_checker},")
dropna()剔除缺失行row:
###至少不为nan的阈值为5,否者直接剔除此行axis=1代表列
dropna(axis=0,thresh=5)
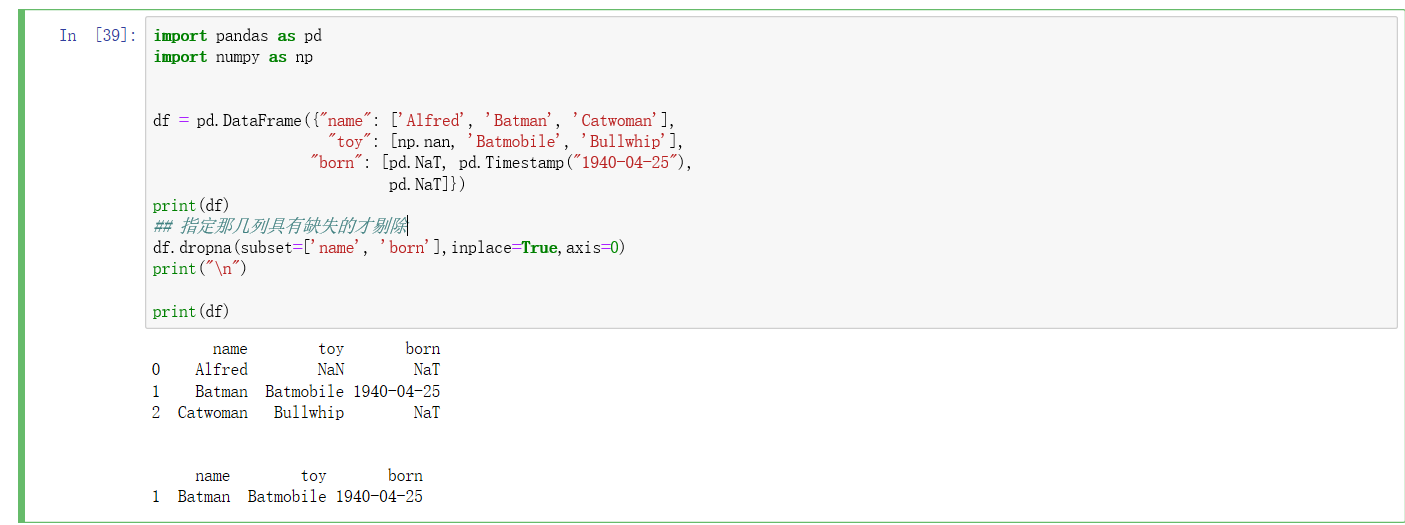
剔除指定列含有缺失的行:
import pandas as pd
import numpy as np
df = pd.DataFrame({"name": ['Alfred', 'Batman', 'Catwoman'],
"toy": [np.nan, 'Batmobile', 'Bullwhip'],
"born": [pd.NaT, pd.Timestamp("1940-04-25"),
pd.NaT]})
print(df)
## 指定那几列具有缺失的才剔除
df.dropna(subset=['name', 'born'],inplace=True,axis=0)
print("
")
print(df)
dropna how