一、手动创建scrapy项目
----------------
安装scrapy:
pip install -i https://pypi.douban.com/simple/ scrapy
1、创建项目
(article_spider) E:PyCharmWorkspace>scrapy startproject ArticleSpider(项目名称)
此时只是利用现有模板创建了scrapy项目,但是没有spider
2、pycharm导入项目
1、open
2、配置解释器
file->setting->project interpreater-选择你创建的虚拟环境下script-python.exe
3、创建spider
1)进入项目目录下
(article_spider) E:PyCharmWorkspace>cd ArticleSpider
2)创建spider
(article_spider)E:PyCharmWorkspaceArticleSpider>scrapy genspider jobbole(spider的名字) blog.jobbole.com(域名)
idea中spider目录下就会出现对应的py文件
4、为了可以调试scrapy,创建main文件
以后想debug的时候,直接debug该main文件即可。原理是在scrapy中调用spider(命令是scrapy crawl jobbole)
from scrapy.cmdline import execute import sys import os #os.path.abspath(__file__)获取当前py文件的路径 #os.path.dirname(),获得参数文件所在文件夹的路径,即父目录 #__file__指当前py文件 print (os.path.abspath(__file__)) #在工程目录os.path.dirname(os.path.abspath(__file__))下执行命令行才有效 sys.path.append(os.path.dirname(os.path.abspath(__file__))) #scrapy中启动spider项目:在命令行用scrapy crawl jobbole命令 execute(["scrapy","crawl","jobbole"])
5】、cmd执行spider命令
命令:scrapy crawl jobbole
错误:ImportError: No module named 'win32api'
解决:pip install -i https://pypi.douban.com/simple pypiwin32
6、修改seeting.py(必须改)
ROBOTSTXT_OBEY = False 将true改为false
若为true会自动过滤掉不符合ROBOTS规则的url
7】、
在jobbole.py中:
执行完spider(scrapy crawl jobbole)后会有如下操作:
下载start_urls = ['http://blog.jobbole.com/']该url的页面,返回一个response
def parse(self, response):
二、基础知识
----------
0、
scrapy获得的是右击页面->查看页面源代码
右击页面->检查,的代码是运行完js之后的,并不是scrapy要爬取的
1、css选择器
----------
* 选择所有节点 #container 选择id为container的节点 .container 选择所有class包含container的节点 li a 选取所有li下的所有a节点 ul + p 选择ul后面的第一个p元素(互为兄弟节点) div#container > ul 选取id为container的div的第一个ul子元素
2、技巧
--------
1)如何快速得到css地址
chrome 右击你要定位的元素,选择copy->copy selector 即可
2)
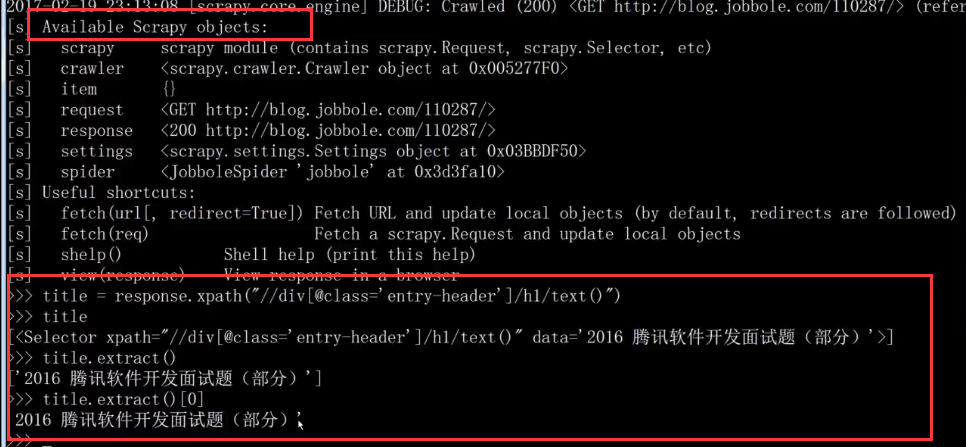
每次启动scrapy都比较慢,每调试一次都需要启动scrapy. shell脚本调试
在虚拟环境下,cmd命令,执行scrapy shell http://blog.jobbole.com/112569/(对这个url进行调试),response可以调用:
3)
.strip():去除左右两边的空字符