Kafka
概述
Kafka是由LinkedIn开发的一个分布式的消息系统,最初是用作LinkedIn的活动流(Activity Stream)和运营数据处理的基础。
活动流数据包括页面访问量(Page View)、被查看内容方面的信息以及搜索情况等内容。这种数据通常的处理方式是先把各种活动以日志的形式写入某种文件,然后周期性地对这些文件进行统计分析。
运营数据指的是服务器的性能数据(CPU、IO使用率、请求时间、服务日志等等数据)。运营数据的统计方法种类繁多。
Kafka使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源分布式处理系统如Cloudera、Apache Storm、Spark都支持与Kafka集成。
总结Kafka是一种分布式的,基于发布/订阅的消息系统,能够高效并实时的吞吐数据,以及通过分布式集群及数据复制冗余机制(副本冗余机制)实现数据的安全
常用Message Queue对比
RabbitMQ
RabbitMQ是使用Erlang编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP, SMTP, STOMP,也正因如此,它非常重量级,更适合于企业级的开发
同时实现了Broker构架,这意味着消息在发送给客户端时先在中心队列排队。对路由,负载均衡或者数据持久化都有很好的支持。
Redis
Redis是一个基于Key-Value对的NoSQL数据库,开发维护很活跃。虽然它是一个Key-Value数据库存储系统,但它本身支持MQ功能,所以完全可以当做一个轻量级的队列服务来使用
ZeroMQ
ZeroMQ号称最快的消息队列系统,尤其针对大吞吐量的需求场景
ZeroMQ能够实现RabbitMQ不擅长的高级/复杂的队列,但是开发人员需要自己组合多种技术框架,技术上的复杂度是对这MQ能够应用成功的挑战
ZeroMQ仅提供非持久性的队列,也就是说如果宕机,数据将会丢失。
ActiveMQ
ActiveMQ是Apache下的一个子项目。 类似于ZeroMQ,它能够以代理人和点对点的技术实现队列。
同时类似于RabbitMQ,它少量代码就可以高效地实现高级应用场景。
适用场景
Messaging
对于一些常规的消息系统,kafka是个不错的选择;partitons/replication和容错,可以使kafka具有良好的扩展性和性能优势
Website activity tracking
kafka可以作为"网站活性跟踪"的最佳工具;可以将网页/用户操作等信息发送到kafka中.并实时监控,或者离线统计分析等
Metric
Kafka通常被用于可操作的监控数据。这包括从分布式应用程序来的聚合统计用来生产集中的运营数据提要。
Log Aggregatio
kafka的特性决定它非常适合作为"日志收集中心";application可以将操作日志"批量""异步"的发送到kafka集群中,而不是保存在本地或者DB中;kafka可以批量提交消息/压缩消息等
这对producer端而言,几乎感觉不到性能的开支.此时consumer端可以使hadoop等其他系统化的存储和分析系统
Kafka架构
拓扑图
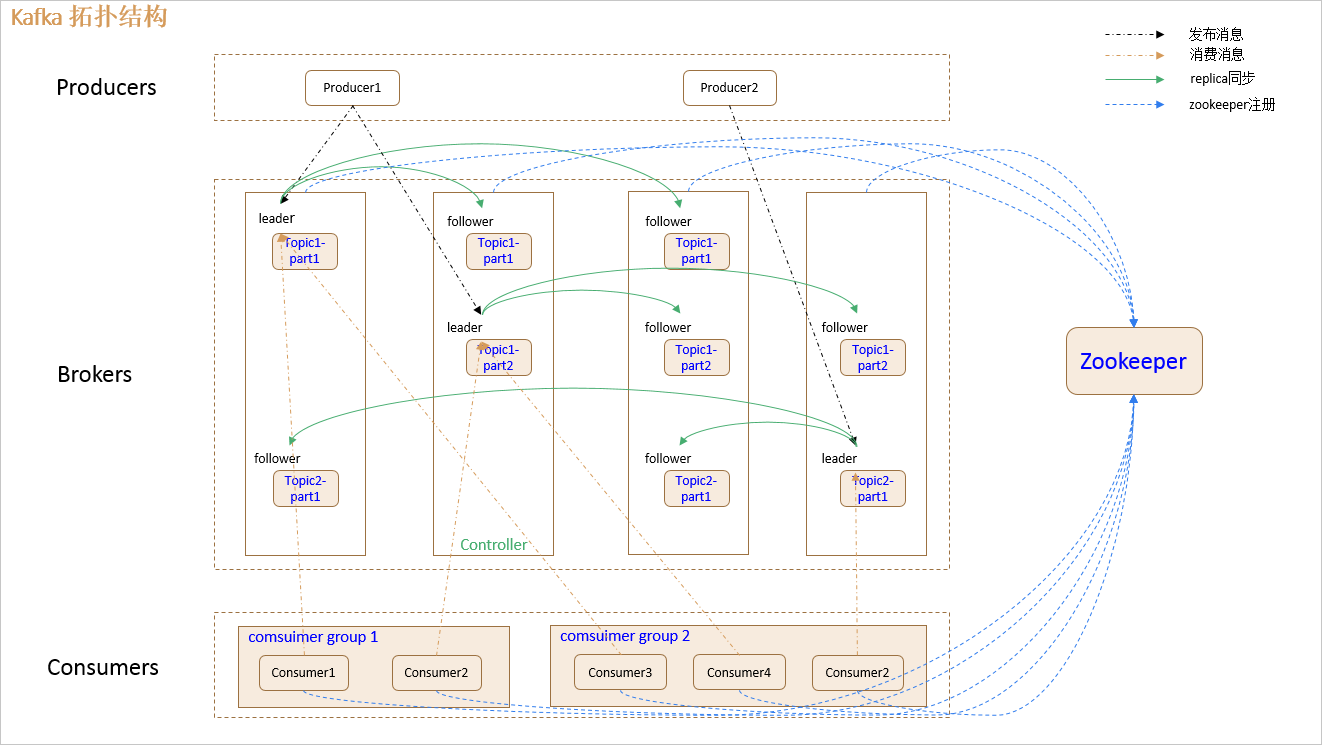
1.producer:
消息生产者,发布消息到 kafka 集群的终端或服务。
2.broker:
kafka 集群中包含的服务器。broker (经纪人,消费转发服务)
3.topic:
每条发布到 kafka 集群的消息属于的类别,即 kafka 是面向 topic 的。
4.partition:
partition 是物理上的概念,每个 topic 包含一个或多个 partition。kafka 分配的单位是 partition。
5.consumer:
从 kafka 集群中消费消息的终端或服务。
6.Consumer group:
high-level consumer API 中,每个 consumer 都属于一个 consumer group,每条消息只能被 consumer group 中的一个 Consumer 消费,但可以被多个 consumer group 消费。
即组间数据是共享的,组内数据是竞争的。
7.replica:
partition 的副本,保障 partition 的高可用。
8.leader:
replica 中的一个角色, producer 和 consumer 只跟 leader 交互。
9.follower:
replica 中的一个角色,从 leader 中复制数据。
10.controller:
kafka 集群中的其中一个服务器,用来进行 leader election 以及 各种 failover。
11.zookeeper:
kafka 通过 zookeeper 来存储集群的 meta 信息。
Kafka使用
1.创建自定义的topic
在bin目录下执行:
sh kafka-topics.sh --create --zookeeper hadoop01:2181 --replication-factor 1 --partitions 1 --topic enbook
注:副本数量要小于等于节点数量
2.查看所有的topic
执行:sh kafka-topics.sh --list --zookeeper hadoop01:2181
3.启动producer
执行:sh kafka-console-producer.sh --broker-list hadoop01:9092 --topic enbook
4.启动consumer
执行:[root@hadoop01 bin]# sh kafka-console-consumer.sh --zookeeper hadoop01:2181 --topic enbook --from-beginning
5.可以通过producer和consumer模拟消息的发送和接收
进入bin目录,执行:sh kafka-topics.sh --delete --zookeeper hadoop01:2181 --topic enbook
6.删除topic指令:
Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic(主题)。
Topic在逻辑上可以被认为是一个queue,每条消息都必须指定它的Topic,可以简单理解为必须指明把这条消息放进哪个queue里。
Partition
Parition是物理上的概念,每个Topic包含一个或多个Partition.
为了使得Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个Partition,
每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件
因为每条消息都被append到该Partition中,属于顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证)。
对于传统的message queue而言,一般会删除已经被消费的消息,而Kafka集群会保留所有的消息,无论其被消费与否
因为磁盘限制,不可能永久保留所有数据(实际上也没必要),因此Kafka提供两种策略删除旧数据。一是基于时间,二是基于Partition文件大小
Kafka消息流处理
1. producer 先从 zookeeper 的 "/brokers/.../state" 节点找到该 partition 的 leader
2. producer 将消息发送给该 leader
3. leader 将消息写入本地 log
4. followers 从 leader pull 消息,写入本地 log 后 leader 发送 ACK
5. leader 收到所有 ISR 中的 replica 的 ACK 后,增加 HW(high watermark,最后 commit 的 offset) 并向 producer 发送 ACK。
ISR
比如有三个副本 ,编号是① ② ③ ,其中② 是Leader ① ③是Follower。假设在数据同步过程中,①跟上Leader,但是③出现故障或没有及时同步,则① ②是一个ISR,而③不是ISR成员。后期在Leader选举时,会用到ISR机制。会优先从ISR中选择Leader
kafka HA
概述
同一个 partition 可能会有多个 replication
没有 replica 的情况下,一旦 broker 宕机,其上所有 patition 的数据都不可被消费,同时 producer 也不能再将数据存于其上的 patition。
引入replication 之后,同一个 partition 可能会有多个 replica,而这时需要在这些 replica 之间选出一个 leader,producer 和 consumer 只与这个 leader 交互,其它 replica 作为 follower 从 leader 中复制数据。
leader failover
当 partition 对应的 leader 宕机时,需要从 follower 中选举出新 leader。在选举新leader时,一个基本的原则是,新的 leader 必须拥有旧 leader commit 过的所有消息
对于 f+1 个 replica,一个 partition 可以在容忍 f 个 replica 失效的情况下保证消息不丢失。
当所有 replica 都不工作时,有两种可行的方案:
1. 等待 ISR 中的任一个 replica 活过来,并选它作为 leader。可保障数据不丢失,但时间可能相对较长。
2. 选择第一个活过来的 replica(不一定是 ISR 成员)作为 leader。无法保障数据不丢失,但相对不可用时间较短。
kafka 0.8.* 使用第二种方式。此外, kafka 通过 Controller 来选举 leader。
Kafka offset机制
分区数据的Offset存储机制
一个分区在文件系统里存储为一个文件夹。文件夹里包含日志文件和索引文件。其文件名是其包含的offset的最小的条目的offset
实际上offset的存储采用了稀疏索引,这样对于稠密索引来说节省了存储空间,但代价是查找费点时间。
Consumer消费者的offset存储机制
Consumer在从broker读取消息后,可以选择commit,该操作会在Kakfa中保存该Consumer在该Partition中读取的消息的offset。该Consumer下一次再读该Partition时会从下一条开始读取。
通过这一特性可以保证同一消费者从Kafka中不会重复消费数据。
Kafka会使用下面公式计算该消费者group位移保存在__consumer_offsets的哪个目录上:
Math.abs(groupID.hashCode()) % numPartitions
信息检索技术
概念介绍
全文检索是一种将文件中所有文本与检索项匹配的文字资料检索方法。全文检索系统是按照全文检索理论建立起来的用于提供全文检索服务的软件系统。
全文检索主要对非结构化数据的数据检索。
结构化数据和非结构化数据
结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
非结构化数据:指不定长或无固定格式的数据,如邮件,word文档,网页等。
半结构化数据,如XML,HTML等,当根据需要可按结构化数据来处理,也可抽取出纯文本按非结构化数据来处理。
非结构化数据另外一种叫法叫:全文数据。
数据搜索
对结构化数据的搜索:如对数据库的搜索,用SQL语句。再如对元数据的搜索,如利用windows搜索对文件名,类型,修改时间进行搜索等。
对非结构化数据的搜索:如利用windows的搜索也可以搜索文件内容,Linux下的grep命令,再如用Google和百度可以搜索大量内容数据。
顺序扫描法
所谓顺序扫描,比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件。
索引与全文检索
比如字典,对每一个字的解释是非结构化的,如果字典没有音节表和部首检字表,在茫茫辞海中找一个字只能顺序扫描。
这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
全文检索原理
全文检索大体分两个过程,创建索引(Indexing)和搜索索引(Search)。
索引创建:将现实世界中所有的结构化和非结构化数据提取信息,创建索引的过程。
搜索索引:就是得到用户的查询请求,搜索创建的索引,然后返回结果的过程。
这也是全文搜索相对于顺序扫描的优势之一:一次索引,多次使用。
正向索引
已知文件,欲检索数据,这是建立:文件——数据的映射,称为正向索引,
反向索引
这是已知数据,欲检索文件,这是建立:数据——文件的映射,称为反向索引,又称倒排索引。

左边保存的是一系列字符数据,称为词典。每个字符串都指向包含此字符串的文档(Document)链表,此文档链表称为倒排表(Posting List)。
全文检索的确加快了搜索的速度,但是多了索引的过程,两者加起来不一定比顺序扫描快多少。尤其是在数据量小的时候更是如此。并且对一个很大量的数据创建索引也是一个很慢的过程。
如何创建索引
1.第一步:一些要索引的原文档(Document)。
2.第二步:将原文档传给分词组件(Tokenizer)。
经过分词(Tokenizer)后得到的结果称为词元(Token)。
3第三步:将得到的词元(Token)传给语言处理组件(Linguistic Processor)。
补充:语言处理组件(linguistic processor)的结果称为词(Term)。
4第四步:将得到的词(Term)传给索引组件(Indexer)。
Document Frequency 即文档频次,表示总共有多少文件包含此词(Term)。
Frequency 即词频率,表示此文件中包含了几个此词(Term)。
向量空间模型算法(Vector Space Model)
概念介绍
VSM概念简单,把对文本内容的处理简化为向量空间中的向量运算,并且它以空间上的相似度表达语义的相似度,直观易懂。当文档被表示为文档空间的向量,就可以通过计算向量之间的相似性来度量文档间的相似性。文本处理中最常用的相似性度量方式是余弦距离。
向量空间模型 (或词组向量模型) 是一个应用于信息过滤,信息撷取,索引以及评估相关性的代数模型。
算法原理
1. 计算权重(Term weight)的过程。
Term Frequency (tf):即此Term在此文档中出现了多少次。tf 越大说明越重要。
Document Frequency (df):即有多少文档包含次Term。df 越大说明越不重要。
2. 判断Term之间的关系从而得到文档相关性的过程,也即向量空间模型的算法(VSM)。