原文作者为 Luk Perkins,来自 Splunk 团队。
文章翻译已获得原作者授权。
消息队列是大多数大规模数据架构的主要组件。如果必须对数据进行实时处理,那么使用消息队列是很好的选择。
数据处理管道会发生各种故障,数据 consumer 可能会受到延迟或完全不能工作,网络分区可能会暂时切断整个 consumer 组与数据管道的连接等。
有些情况必须使用消息队列,例如:
- 开发拼车应用程序,不考虑高峰时段的使用峰值,需要确保每个乘车请求最终只匹配到一位司机
- 金融级事务交易管道需要同步请求处理,以防止数据丢失
- 搭建基于微服务的处理管道,前端为具有多个写入端点的 REST API(每秒进行数千次运算),需要确保即使后端微服务出现故障,所有的工作对象都保留在系统中
消息队列如何工作
下图为消息队列常见****的工作方式(并对故障做出响应)的示意图:
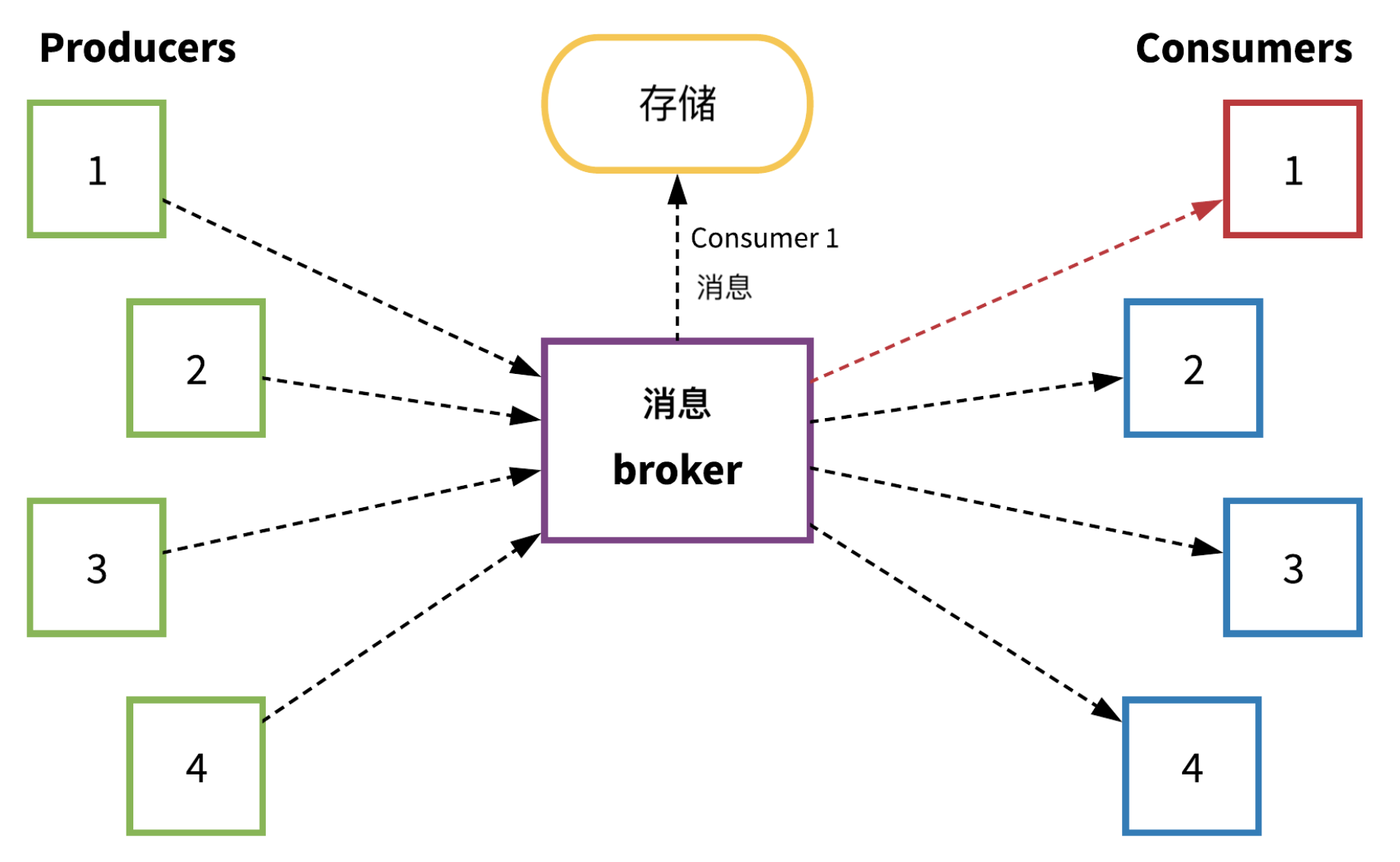
在上图中,producer 1、2、3 和 4 通过消息 broker 将消息发送到管道,而 consumer 1、2、3 和 4 处理(然后确认)这些消息。在本示例中,当 consumer 1 出现故障时,会出现非常严重的问题。Producer 会继续将数据传送到系统中,但 consumer 1 不能继续处理消息。Broker 应该****开始存储所有原本将会用于 consumer 1 的消息数据,直到 consumer 1 能够继续处理消息。
从这个示例可以看出,对于堆栈中任何重要的消息队列而言,稳定的存储组件都必不可少。幸运的是,消息队列与支持消息队列的存储系统一样性能良好。如果存储组件易发故障、受到损坏,或运行缓慢,因而即便仅有一个组件出现故障,也不能很好地应对,那么强烈建议大家更换存储部件。
引入 Apache Pulsar
一般而言,由不同的系统处理订阅-发布消息和消息队列。例如,典型的技术栈可能使用 Apache Kafka 处理发布-订阅消息,使用 RabbitMQ 处理消息队列。在这种情况下,虽然系统工作良好,但是你需要同时部署、管理多个消息系统。
我最喜欢 Apache Pulsar 的一点就是,它可以轻松连接订阅-发布消息和消息队列。Pulsar 是第一个为了同时处理订阅-发布消息和消息队列而开源的消息系统。
因为使用 Apache BookKeeper 分布式日志存储数据库作为存储组件,Pulsar 可以轻松地同时支持订阅-发布消息和消息队列。BookKeeper 作为日志存储系统,基于消息 topic 数据结构而构建,支持水平扩展(增加 “bookie” 数量即可扩展容量),且运行迅速。
Pulsar 支持两种基本的 topic 类型:持久 topic 与非持久 topic。用户可以根据名称辨别 topic 类型,因为类型即为 topic 名称的“schema”(类似于 https 是 URL https://google.com 的 schema)。
持久 topic 的名称格式为:persistent://public/default/some-topic,而非持久 topic 的名称格式为:non-persistent://public/default/some-topic。
用户使用持久 topic 时,Pulsar 将所有未确认消息(即未处理消息)存储在 BookKeeper 中的多个“bookie”服务器上。
Pulsar 的确支持非持久 topic,但是我们建议用户只在可以接受丢失消息的用例中,使用非持久消息。对于具有消息队列功能的 topic,绝不应该使用非持久 topic。与将消息数据存储在内存中相比,这种存储方式具有很多优势。
如何将 Apache Pulsar 用作消息队列
Pulsar 无需特殊配置或调整,即可支持两种用例,因此在使用方面具有一定的优势。重点在于如何使用 Pulsar,如下图所示:
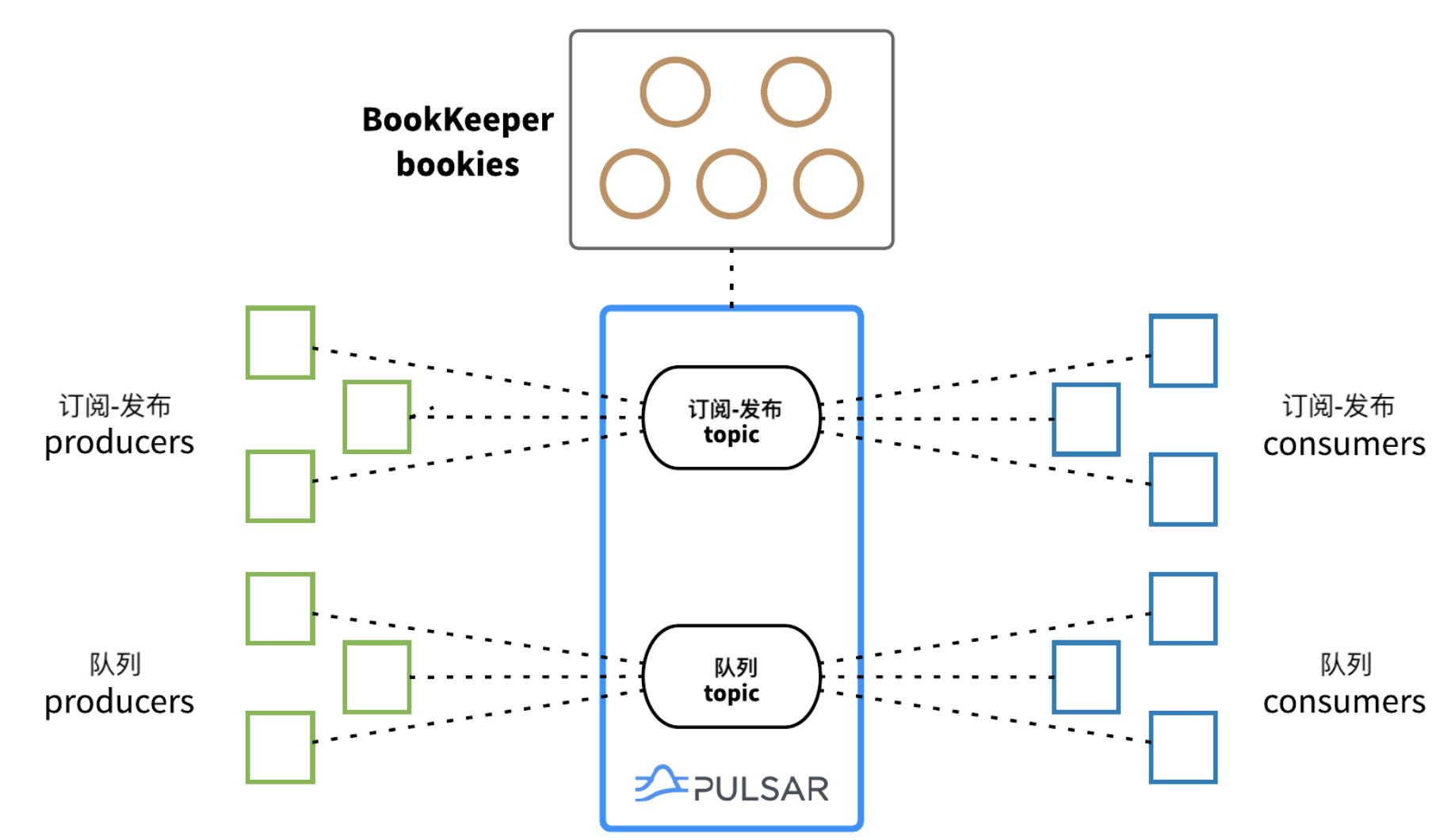
发布-订阅 producer 和 consumer 通过发布-订阅 topic 进行通信,而队列 producer 和 consumer 通过队列 topic 进行通信。不需要“标记”topic,也不需要预先指定 topic 为实时 topic 或队列 topic。
消息队列 topic 需要 consumer 使用共享订阅,而不能是独占订阅(exclusive)或灾备订阅(failover)。另外,所有 consumer 必须使用相同的订阅名称,否则就不是同一订阅。当 consumer 在 topic 上创建共享订阅后,Pulsar 会自动在接收消息的 consumer 之间进行负载平衡,对于消息队列来说,这是最理想的状态。
以下代码展示了五个 Java consumer 使用共享订阅监听同一 topic 的场景:
String PULSAR_SERVICE_URL = "pulsar://localhost:6650";
String MQ_TOPIC = "persistent://public/default/message-queue-topic";
String SUBSCRIPTION = "sub-1";
// Pulsar client
PulsarClient client = PulsarClient.builder()
.serviceUrl(PULSAR_SERVICE_URL)
.build();
// Base consumer builder for instantiating multiple consumers
ConsumerBuilder<byte[]> consumerBuilder = client.newConsumer()
.topic(MQ_TOPIC)
.subscriptionName(SUBSCRIPTION)
.subscriptionType(SubscriptionType.Shared)
.messageListener(messageCallback);
// Create five consumers (mq-consumer-0, mq-consumer-1, etc.)
IntStream.range(0, 4).forEach(i -> {
String name = String.format("mq-consumer-%d", i);
consumerBuilder
.consumerName(name)
.subscribe();
});
控制消息调度
吞吐量在消息队列中尤为重要。如果消息队列没有足够的吞吐量来处理周围数据管道所需要的内容,那么消息队列可能不仅性能不够好,甚至会产生一些负面影响。如果使用 Pulsar 作为消息队列,则可以通过调整 consumer 的配置来微调处理吞吐量。
默认情况下,Apache Pulsar consumer 有一个接收队列,用于一次处理多条消息。用户可以自行配置单个 consumer 接收队列的大小(默认值为 1000 条消息)。
理想情况下,应该根据 consumer 处理消息的速度来设置接收队列的大小。如果可以非常快速地处理消息(只需几毫秒),那么建议将接收队列的大小设置为较大的值,因为这样有助于最大化 consumer 的处理吞吐量。
但是如果处理消息需要较长时间,最好将接收队列的大小设置为较小的值。如果 consumer 正在执行的任务属于 CPU 密集型,也就是说任务处理需要几秒钟甚至更久,则建议将接收队列的大小设置为个位数或 1,这样负载平衡器能够在 consumer 之间合理地分发消息。
在下面这段代码中,consumer 接收队列比较小(Java):
Consumer<byte[]> consumer = client.newConsumer()
.topic("slow-processing-topic")
.subscriptionType(SubscriptionType.Shared)
.subscriptionName("sub-1")
.receiverQueueSize(5)
.messageListener(messageCallback)
.subscribe();
接收队列的默认值适用于很多用例。但是建议用户稍微留意一下接收队列,以免在后续工作中需要进行调优。
一个消息平台,两种用例场景
如果想在不同用例场景中同时运行多个消息平台,大家可以考虑使用 Pulsar。Pulsar 同时支持两种主要的消息用例——发布-订阅消息(尤其是持久消息)和消息队列,并且运行速度快、可扩展,还可以减轻运维管理负担。