1.参考上一篇博客
https://www.cnblogs.com/StarZhai/p/11926610.html
2.下载yolov3项目工程。
https://github.com/pjreddie/darknet
3.修改Makefile文件(文件就在下载的darknet文件夹内)
GPU=1 #使用GPU训练,其他的没有用,所以没有置为1,可根据自己的需要调整 CUDNN=1 OPENCV=1 OPENMP=0 DEBUG=0
4.在目录下新建VOC2007,并在VOC2007下新建Annotations,ImageSets和JPEGImages三个文件夹。在ImageSets下新建Main文件夹。文件目录如下所示:
然后可以按照labelImg使用方法开始标注图片,生成xml文件或txt文件

5.划分训练集测试集按照上一篇文档
6.将labels中的txt全部复制到JPEGImages文件夹中,做到图片和txt一一对应
一开始是要吧JPEGImages文件中的图片放到darknet-master/data/images目录下,现在直接把yolo的标签文件txt即labels中的内容复制到JPEGImages文件夹中就可以了。
7.局部修改
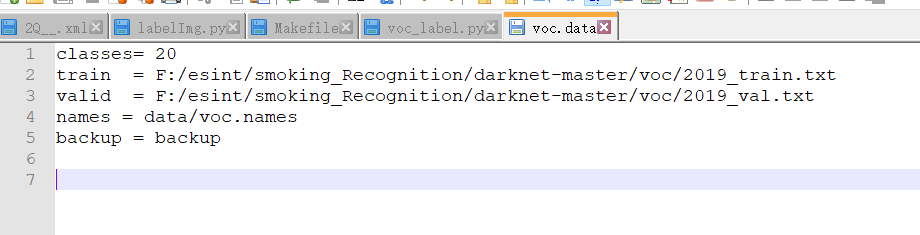
①根据自己的路径修改cfg/voc.data
②修改data/voc.names和coco.names

③修改参数文件cfg/yolov3-voc.cfg
ctrl+f搜 yolo, 总共会搜出3个含有yolo的地方。
每个地方都必须要改2处, filters:3*(5+len(classes));
其中:classes: len(classes) = 1,这里以单个类dog为例
filters = 18
classes = 1
可修改:random = 1:原来是1,显存小改为0。(是否要多尺度输出。)
8.开始训练
①在darknet-master终端运行如下代码进行训练
wget https://pjreddie.com/media/files/darknet53.conv.74
#不保留训练日志的训练执行命令 ./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
#保存训练日志的训练执行命令
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74 | tee train_yolov3-voc.log
#日志位于项目的根目录下
②训练默认的是前1000轮每100轮保存一次模型,1000轮后每10000轮保存一次模型。可以修改examples/detector.c文件的138行。修改完重新编译一下,在darknet目录下执行make。
make

9.训练日志参数说明

Region xx:cfg文件中yolo-layer的索引;
Avg IOU: 当前迭代中,预测的box与标注的box的平均交并比,越大越好,期望数值为1;
Class:标注物体的分类准确率,越大越好,期望数值为1;
obj:越大越好,期望数值为1;
No obj:越小越好;
.5R:以IOU=0.5为阈值时候的recall; recall = 检出的正样本/实际的正样本
0.75R:以IOU=0.75为阈值时候的recall;
count:正样本数目
20277: 指示当前训练的迭代次数
0.38915: 是总体的Loss(损失)
0.42692 avg: 是平均Loss,这个数值应该越低越好,一般来说,一旦这个数值低于0.060730 avg就可以终止训练了。
0.000100 rate: 代表当前的学习率,是在.cfg文件中定义的。
0.302128 seconds: 表示当前批次训练花费的总时间。
162216 images: 这一行最后的这个数值表示到目前为止,参与训练的图片的总量。
10.调参中遇到的问题
在Region 82 Avg IOU、Region 94 Avg IOU、Region 106 Avg IOU中出现很多nan
前提说明:在训练过程中,nan的屏幕占比30%是正常的,如果太大,全是nan,则就是训练出了问题
解决方法一:在显存允许的情况下,可以适当增加batch(darknet-master/yolov3-voc.cfg中的batch)的大小(要视自己数据集 的大小情况来调整batch和subdivisions batch指的是单词识别图片个数,subdivisions是将batch划分的组数:例如batch=64 subdivisions=16 64/16=4所以单次训练变成16次循环,每次循环同事训练4张图片。我的电脑GTX1050 8G做深度学习略低,只允许同时训练一张图片。因此通过同时扩大二者可以增大循环训练次数。我用1000张灭火器图片另bath和subdivisions都为8最终效果还不错),这样能够一定程度减少nan的出现。
解决方法二:增加数据集的规模。若是对于10类以内的图片,500张以内的训练集未必是太少了,因此可以增加数据集,实在不 行的话就进行数据增强,把数据集扩展到原来的几倍到几十倍不等。
CUDA Error: out of memory darknet: ./src/cuda.c:36: check_error: Assertio `0' failed.
解决方法:显存不够,调小batch,关闭多尺度训练:random=0.(*************亲测有用**************)
random所在(darknet-master/cfg/yolov3-voc.cfg):
11.训练结果
在训练20000步以后可以看到在backup生成如下训练过程中的权重文件

保存的训练日志文件
12.在avg低于0.06以后,如何停止训练
ubuntu系统下,在训练终端处,使用ctrl+c终止训练
13.如何接着上一步停止处的训练状态继续训练
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc.backup
14.将训练好的权重放到yolov3项目中convert.py的同级目录下边(yolov项目项目的根目录)执行训练语句
python convert.py yolov3_voc.cfg yolov3.weights model_data/yolo.h5
TypeError: buffer is too small for requested array
解决方法:把cfg文件对应好,用上文改好的yolov3-voc.cfg(与其他的cfg类个数不同)
15.训练日志的可视化
visualization_train_yolov3-voc_log.py
# -*- coding: utf-8 -*- # @Func :yolov3 训练日志可视化,把该脚本和日志文件放在同一目录下运行。 import pandas as pd import matplotlib.pyplot as plt import os # ==================可能需要修改的地方=====================================# g_log_path = "train_yolov3-voc.log" # 此处修改为你的训练日志文件名 # ==========================================================================# def extract_log(log_file, new_log_file, key_word): ''' :param log_file:日志文件 :param new_log_file:挑选出可用信息的日志文件 :param key_word:根据关键词提取日志信息 :return: ''' with open(log_file, "r") as f: with open(new_log_file, "w") as train_log: for line in f: # 去除多gpu的同步log if "Syncing" in line: continue # 去除nan log if "nan" in line: continue if key_word in line: train_log.write(line) f.close() train_log.close() def drawAvgLoss(loss_log_path): ''' :param loss_log_path: 提取到的loss日志信息文件 :return: 画loss曲线图 ''' line_cnt = 0 for count, line in enumerate(open(loss_log_path, "rU")): line_cnt += 1 result = pd.read_csv(loss_log_path, skiprows=[iter_num for iter_num in range(line_cnt) if ((iter_num < 500))], error_bad_lines=False, names=["loss", "avg", "rate", "seconds", "images"]) result["avg"] = result["avg"].str.split(" ").str.get(1) result["avg"] = pd.to_numeric(result["avg"]) fig = plt.figure(1, figsize=(6, 4)) ax = fig.add_subplot(1, 1, 1) ax.plot(result["avg"].values, label="Avg Loss", color="#ff7043") ax.legend(loc="best") ax.set_title("Avg Loss Curve") ax.set_xlabel("Batches") ax.set_ylabel("Avg Loss") def drawIOU(iou_log_path): ''' :param iou_log_path: 提取到的iou日志信息文件 :return: 画iou曲线图 ''' line_cnt = 0 for count, line in enumerate(open(iou_log_path, "rU")): line_cnt += 1 result = pd.read_csv(iou_log_path, skiprows=[x for x in range(line_cnt) if (x % 39 != 0 | (x < 5000))], error_bad_lines=False, names=["Region Avg IOU", "Class", "Obj", "No Obj", "Avg Recall", "count"]) result["Region Avg IOU"] = result["Region Avg IOU"].str.split(": ").str.get(1) result["Region Avg IOU"] = pd.to_numeric(result["Region Avg IOU"]) result_iou = result["Region Avg IOU"].values # 平滑iou曲线 for i in range(len(result_iou) - 1): iou = result_iou[i] iou_next = result_iou[i + 1] if abs(iou - iou_next) > 0.2: result_iou[i] = (iou + iou_next) / 2 fig = plt.figure(2, figsize=(6, 4)) ax = fig.add_subplot(1, 1, 1) ax.plot(result_iou, label="Region Avg IOU", color="#ff7043") ax.legend(loc="best") ax.set_title("Avg IOU Curve") ax.set_xlabel("Batches") ax.set_ylabel("Avg IOU") if __name__ == "__main__": loss_log_path = "train_log_loss.txt" iou_log_path = "train_log_iou.txt" if os.path.exists(g_log_path) is False: exit(-1) if os.path.exists(loss_log_path) is False: extract_log(g_log_path, loss_log_path, "images") if os.path.exists(iou_log_path) is False: extract_log(g_log_path, iou_log_path, "IOU") drawAvgLoss(loss_log_path) drawIOU(iou_log_path) plt.show()
(2) 将上述python脚本文件和训练日志放在同一目录下,打开此目录下的终端,运行上述.py文件可以得到loss变化曲线和Avg IOU变化曲线。同时,在当前目录下生成了train_log_iou.txt和train_log_loss.txt文件。
loss变化曲线和Avg IOU变化曲线(仅供参考)


.测试结果


误判的0.1那个通过设置yolo.py中的阈值解决
参考文档:
①超详细教程:YOLO_V3(yolov3)训练自己的数据
https://blog.csdn.net/qq_21578849/article/details/84980298
②字儿超级多的ubuntu训练自定义目标识别
https://blog.csdn.net/gaoyu1253401563/article/details/89642932
③小白手册
https://blog.csdn.net/weixin_42731241/article/details/81352013