Checkpoint 源码流程:
Flink CheckpointCoordinator 启动流程
开局一张图,其他全靠吹,来一张官网 Flink 集群解析图:

官网地址:https://ci.apache.org/projects/flink/flink-docs-release-1.11/concepts/flink-architecture.html#anatomy-of-a-flink-cluster
关于 CheckpointCoordinator,引用一段代码的注释:
```txt
The checkpoint coordinator coordinates the distributed snapshots of operators and state. It triggers the checkpoint by sending the messages to the relevant tasks and collects the checkpoint acknowledgements. It also collects and maintains the overview of the state handles reported by the tasks that acknowledge the checkpoint.
checkpoint 协调器协调 operators 和 state 的分布式快照。 它通过将消息发送到相关任务来触发 checkpoint,并收集 checkpoint 确认。 它还收集并维护由确认 checkpoint 的任务报告的状态句柄的概述。
```
在 CheckpointCoordinator 的构造方法处添加断点,启动任务可以看到如下调用栈
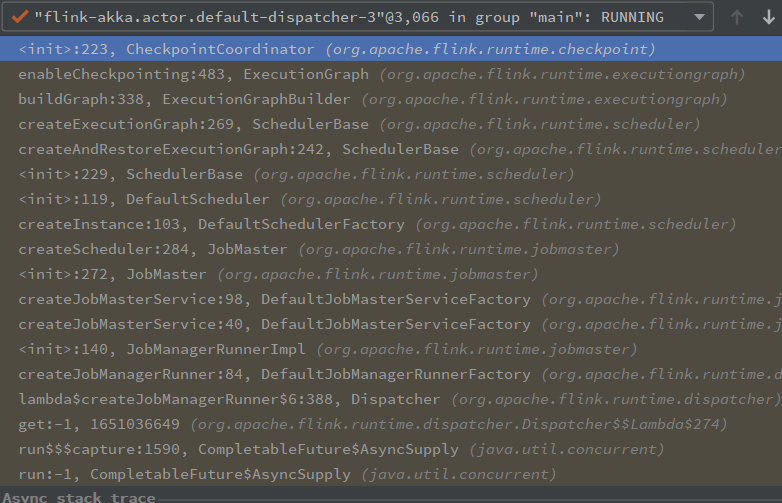
先在 Dispatcher 中 new 了一个 JobManagerRunnerImpl
JobManagerRunnerImpl 构造方法调用了
private CompletableFuture<JobManagerRunner> createJobManagerRunner(JobGraph jobGraph) { final RpcService rpcService = getRpcService(); // Dispatcher 线程 return CompletableFuture.supplyAsync( () -> { try { // 下面是单独的线程在执行,异步调用, 创建 JobManagerRunner return jobManagerRunnerFactory.createJobManagerRunner( jobGraph, configuration, rpcService, highAvailabilityServices, heartbeatServices, jobManagerSharedServices, new DefaultJobManagerJobMetricGroupFactory(jobManagerMetricGroup), fatalErrorHandler); } catch (Exception e) { throw new CompletionException(new JobExecutionException(jobGraph.getJobID(), "Could not instantiate JobManager.", e)); } }, rpcService.getExecutor()); }
createJobMasterService 中 new 了个 JobMaster,JobMaster 的构造方法中调用了 createScheduler(jobManagerJobMetricGroup)
private SchedulerNG createScheduler(final JobManagerJobMetricGroup jobManagerJobMetricGroup) throws Exception { return schedulerNGFactory.createInstance( log, jobGraph, backPressureStatsTracker, scheduledExecutorService, jobMasterConfiguration.getConfiguration(), scheduler, scheduledExecutorService, userCodeLoader, highAvailabilityServices.getCheckpointRecoveryFactory(), rpcTimeout, blobWriter, jobManagerJobMetricGroup, jobMasterConfiguration.getSlotRequestTimeout(), shuffleMaster, partitionTracker); }
createScheduler 中调用了 schedulerNGFactory.createInstance 方法,实际上会调用到 DefaultSchedulerFactory.createInstance 方法上
DefaultSchedulerFactory.createInstance 方法调用了 new DefaultScheduler,在这个方法中还会使用 jobGraph 和 restartStrategy 生成 restartBackoffTimeStrategy
用于生成 DefaultScheduler。
DefaultScheduler 的构造方法中直接调用了父类的构造方法
super( log, jobGraph, backPressureStatsTracker, ioExecutor, jobMasterConfiguration, new ThrowingSlotProvider(), // this is not used any more in the new scheduler futureExecutor, userCodeLoader, checkpointRecoveryFactory, rpcTimeout, new ThrowingRestartStrategy.ThrowingRestartStrategyFactory(), blobWriter, jobManagerJobMetricGroup, Time.seconds(0), // this is not used any more in the new scheduler shuffleMaster, partitionTracker, executionVertexVersioner, false);
DefaultScheduler 的构造方法中还将 restartBackoffTimeStrategy 生成了 ExecutionFailureHandler,(DefaultScheduler 中有 handleTaskFailure/handleGlobalFailure 目测是任务失败的时候调用的 )
this.executionFailureHandler = new ExecutionFailureHandler( getSchedulingTopology(), failoverStrategy, restartBackoffTimeStrategy) @Override public void handleGlobalFailure(final Throwable error) { setGlobalFailureCause(error); log.info("Trying to recover from a global failure.", error); final FailureHandlingResult failureHandlingResult = executionFailureHandler.getGlobalFailureHandlingResult(error); maybeRestartTasks(failureHandlingResult); } private void maybeRestartTasks(final FailureHandlingResult failureHandlingResult) { if (failureHandlingResult.canRestart()) { restartTasksWithDelay(failureHandlingResult); } else { failJob(failureHandlingResult.getError()); } }
回到主流程 DefaultScheduler 调用父类 SchedulerBase 的构造方法
SchedulerBase 的构造方法中会调用 createAndRestoreExecutionGraph, createAndRestoreExecutionGraph 中就会生成 ExecutionGraph 了
this.executionGraph = createAndRestoreExecutionGraph(jobManagerJobMetricGroup, checkNotNull(shuffleMaster), checkNotNull(partitionTracker)); private ExecutionGraph createAndRestoreExecutionGraph( JobManagerJobMetricGroup currentJobManagerJobMetricGroup, ShuffleMaster<?> shuffleMaster, JobMasterPartitionTracker partitionTracker) throws Exception { ExecutionGraph newExecutionGraph = createExecutionGraph(currentJobManagerJobMetricGroup, shuffleMaster, partitionTracker); final CheckpointCoordinator checkpointCoordinator = newExecutionGraph.getCheckpointCoordinator(); if (checkpointCoordinator != null) { // check whether we find a valid checkpoint if (!checkpointCoordinator.restoreLatestCheckpointedStateToAll( new HashSet<>(newExecutionGraph.getAllVertices().values()), false)) { // check whether we can restore from a savepoint tryRestoreExecutionGraphFromSavepoint(newExecutionGraph, jobGraph.getSavepointRestoreSettings()); } } return newExecutionGraph; }
createAndRestoreExecutionGraph 方法中调用了 ExecutionGraphBuilder.buildGraph 生成 ExecutionGraph (到这里三层的抽象图结构就都生成好了)
private ExecutionGraph createExecutionGraph( JobManagerJobMetricGroup currentJobManagerJobMetricGroup, ShuffleMaster<?> shuffleMaster, final JobMasterPartitionTracker partitionTracker) throws JobExecutionException, JobException { final FailoverStrategy.Factory failoverStrategy = legacyScheduling ? FailoverStrategyLoader.loadFailoverStrategy(jobMasterConfiguration, log) : new NoOpFailoverStrategy.Factory(); return ExecutionGraphBuilder.buildGraph( null, jobGraph, jobMasterConfiguration, futureExecutor, ioExecutor, slotProvider, userCodeLoader, checkpointRecoveryFactory, rpcTimeout, restartStrategy, currentJobManagerJobMetricGroup, blobWriter, slotRequestTimeout, log, shuffleMaster, partitionTracker, failoverStrategy); }
在 buildGraph 方法中会生成 ExecutionGra
final ExecutionGraph executionGraph; try { executionGraph = (prior != null) ? prior : new ExecutionGraph( jobInformation, futureExecutor, ioExecutor, rpcTimeout, restartStrategy, maxPriorAttemptsHistoryLength, failoverStrategyFactory, slotProvider, classLoader, blobWriter, allocationTimeout, partitionReleaseStrategyFactory, shuffleMaster, partitionTracker, jobGraph.getScheduleMode()); } catch (IOException e) { throw new JobException("Could not create the ExecutionGraph.", e); }
同时,如果 checkpoint 配置不是 null ,就会调用 executionGraph.enableCheckpointing 方法
if (snapshotSettings != null) { executionGraph.enableCheckpointing( chkConfig, triggerVertices, ackVertices, confirmVertices, hooks, checkpointIdCounter, completedCheckpoints, rootBackend, checkpointStatsTracker) }
new 出 一个 CheckpointCoordinator
checkpointCoordinator = new CheckpointCoordinator( jobInformation.getJobId(), chkConfig, tasksToTrigger, tasksToWaitFor, tasksToCommitTo, operatorCoordinators, checkpointIDCounter, checkpointStore, checkpointStateBackend, ioExecutor, new ScheduledExecutorServiceAdapter(checkpointCoordinatorTimer), SharedStateRegistry.DEFAULT_FACTORY, failureManager);
到这里就开始创建 CheckpointCoordinator 了
以上的调用栈,都是 JobManager 内 JobMaster 的内容,而 JobManager 包含:ResourceManager、Dispatcher、JobMaster 三个组件(以上调用栈最前面就是 Dispatcher )
简化下内容就是这样的了:
Dispatcher.createJobManagerRunner DefaultJobManagerRunnerFactory.createJobManagerRunner new JobManagerRunnerImpl JobManagerRunnerImpl.JobManagerRunnerImpl 构造方法 DefaultJobMasterServiceFactory.createJobMasterService new JobMaster JobMaster.JobMaster 构造方法 ----> createScheduler JobMaster.createScheduler ----> schedulerNGFactory.createInstance DefaultSchedulerFactory.createInstance ---------> FailoverStrategyFactoryLoader.loadFailoverStrategyFactory(jobMasterConfiguration) DefaultScheduler.DefaultScheduler ---------> super() SchedulerBase.SchedulerBase 构造方法 ------> createAndRestoreExecutionGraph(jobManagerJobMetricGroup, checkNotNull(shuffleMaster), checkNotNull(partitionTracker)); SchedulerBase.createAndRestoreExecutionGraph -------> createExecutionGraph(currentJobManagerJobMetricGroup, shuffleMaster, partitionTracker); SchedulerBase.createExecutionGraph ----> ExecutionGraphBuilder.buildGraph ExecutionGraph.buildGraph ----> executionGraph.enableCheckpointing ExecutionGraph.enableCheckpointing --------> new CheckpointCoordinator 至此,checkpointCoordinator 启动
列下上游的调用栈,结合上一篇:Flink MiniCluster 启动流程
从 MiniCluster.start() 开始:
PerJobMiniClusterFactor.submitJob ----> miniCluster.start(); miniCluster.submitJob(jobGraph) PerJobMiniClusterFactor.submitJob -----> 多线程调用 dispatcherGateway.submitJob(jobGraph, rpcTimeout)) (进到里面就是另一个线程了) Dispatcher.submitJob ----> internalSubmitJob Dispatcher.internalSubmitJob ------> waitForTerminatingJobManager(jobGraph.getJobID(), jobGraph, this::persistAndRunJob) 调用 persistAndRunJob Dispatcher.persistAndRunJob ----> runJob Dispatcher.runJob -----> createJobManagerRunner Dispatcher.createJobManagerRunner --------> 多线程调用 jobManagerRunnerFactory.createJobManagerRunner 跟最开头就接上了
这样就都接上了
欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文
