11.2译码和纠错(Decoding and Error Correction)
译码函数(d:B^n -> B^m)被叫做与编码函数e相关联的译码函数,意思是(d o e = 1_{B^m})
1.显然,译码函数必须是个满射函数,这样才能保证每个码字都能解码
2.译码函数不能保证每个码字都正确译中
例如:如果d是译奇偶校验码的
d(10010) = 1001 and d(11001) = 1100(不一定译正确)
再例如:e是三倍编码函数,那么其相应的译码是如此定义的:

最大似然技术(Maximum likelihood technique)
让接收的码字用与其海明距离最小的正确码字来近似(不一定是一定正确的)
定理1:
和运输错误为k的最小距离至少为k+1相比,(e, d)能纠错为至多k的最小距离要求为2k+1(显然)
构建最大似然译码函数
定理2:
设G的子有限群K,K的任何左(右)陪集的元素个数和K的元素个数相等
构造并证明一个从K -> aK双射的函数即可


令e是从(e^m -> e^n)的群编码,那么(N = { e(B^m)}) = ({ x^{(1)},x^{(2)},...,x^{(2^m)}})是(B^n)的子群,这为我们构造陪集头创造了条件
陪集头(Coset leader)
知道这个方法,你最好先知道以下知识:
- 一个子群的所有左陪集要么相等,要么相交为∅
- 所有左陪集的元素个数是相等的(下面会证明)
- 所有属于xH里面的元素(如a),其左陪集 = xH
- 我们希望求出得到的和码字(x_t)的海明距离最近的代码字
- ⊕运算有这样的性质: a ⊕ b = c ==> a ⊕ c = b, b ⊕ c = a
假设传输的代码字x = e(b),而我们接受到的码字是(x_t)
N对于(x_t)的左陪集:
- (x_t ⊕ N = {ε_1, ε_2, ... , ε_{2^m}}),其中(ε_i = x_t ⊕ x^{(i)})
如果(ε_j)是权最小的陪集元素(Coset member),那么我们就说相应的(x_j)是最接近(x_t)的(这个(x_j)也就是我们要求的),我们称(ε_j)为陪集头(Coset leader)
于是,我们有了以下通过陪集头的译码步骤:
- 利用子群(N = e(B^m))求(B^n)中所有码字的左陪集
- 对于每个陪集求最小权值的陪集头((ε_j))
- 对于接收到的码字(x_t),先找到其所属的陪集和对应的陪集头
- 通过(3)中找到的陪集头ε,我们用ε ⊕ (x_t)来得到最接近的代码字x(运用知识点5)

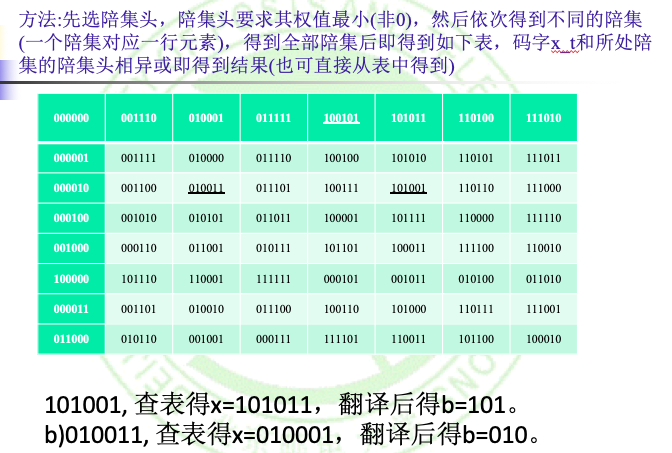
简化译码技术(Simplified decoding technique)
特征值法<待补充>