Java序列化的目的主要有两个:
1.网络传输
2.对象持久化
当选行远程跨迸程服务调用时,需要把被传输的Java对象编码为字节数组或者ByteBuffer对象。而当远程服务读取到ByteBuffer对象或者字节数组时,需要将其解码为发送时的Java 对象。这被称为Java对象编解码技术。
Java序列化仅仅是Java编解码技术的一种,由于它的种种缺陷,衍生出了多种编解码技术和框架
Java序列化的缺点
Java序列化从JDK1.1版本就已经提供,它不需要添加额外的类库,只需实现java.io.Serializable并生成序列ID即可,因此,它从诞生之初就得到了广泛的应用。
但是在远程服务调用(RPC)时,很少直接使用Java序列化进行消息的编解码和传输,这又是什么原因呢?下面通过分析.Tava序列化的缺点来找出答案。
1 无法跨语言
对于跨进程的服务调用,服务提供者可能会使用C十+或者其他语言开发,当我们需要和异构语言进程交互时Java序列化就难以胜任。由于Java序列化技术是Java语言内部的私有协议,其他语言并不支持,对于用户来说它完全是黑盒。对于Java序列化后的字节数组,别的语言无法进行反序列化,这就严重阻碍了它的应用。
2 序列化后的码流太大
通过一个实例看下Java序列化后的字节数组大小。
3序列化性能太低
无论是序列化后的码流大小,还是序列化的性能,JDK默认的序列化机制表现得都很差。因此,我们边常不会选择Java序列化作为远程跨节点调用的编解码框架。
序列化 – 内置和第三方的MessagePack实战
内置
Netty内置了对JBoss Marshalling和Protocol Buffers的支持
集成第三方MessagePack实战(LengthFieldBasedFrame详解)
LengthFieldBasedFrame详解
maxFrameLength:表示的是包的最大长度,
lengthFieldOffset:指的是长度域的偏移量,表示跳过指定个数字节之后的才是长度域;
lengthFieldLength:记录该帧数据长度的字段,也就是长度域本身的长度;
lengthAdjustment:长度的一个修正值,可正可负;
initialBytesToStrip:从数据帧中跳过的字节数,表示得到一个完整的数据包之后,忽略多少字节,开始读取实际我要的数据
failFast:如果为true,则表示读取到长度域,TA的值的超过maxFrameLength,就抛出一个 TooLongFrameException,而为false表示只有当真正读取完长度域的值表示的字节之后,才会抛出 TooLongFrameException,默认情况下设置为true,建议不要修改,否则可能会造成内存溢出。
数据包大小: 14B = 长度域2B + "HELLO, WORLD"(单词HELLO+一个逗号+一个空格+单词WORLD)
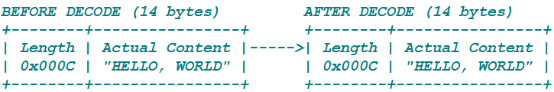
长度域的值为12B(0x000c)。希望解码后保持一样,根据上面的公式,参数应该为:
1. lengthFieldOffset = 0
2. lengthFieldLength = 2
3. lengthAdjustment 无需调整
4. initialBytesToStrip = 0 - 解码过程中,没有丢弃任何数据
数据包大小: 14B = 长度域2B + "HELLO, WORLD"

长度域的值为12B(0x000c)。解码后,希望丢弃长度域2B字段,所以,只要initialBytesToStrip = 2即可。
1. lengthFieldOffset = 0
2. lengthFieldLength = 2
3. lengthAdjustment 无需调整
4. initialBytesToStrip = 2 解码过程中,丢弃2个字节的数据
数据包大小: 14B = 长度域2B + "HELLO, WORLD"。长度域的值为14(0x000E)

长度域的值为14(0x000E),包含了长度域本身的长度。希望解码后保持一样,根据上面的公式,参数应该为:
1. lengthFieldOffset = 0
2. lengthFieldLength = 2
3. lengthAdjustment = -2 因为长度域为14,而报文内容为12,为了防止读取报文超出报文本体,和将长度字段一起读取进来,需要告诉netty,实际读取的报文长度比长度域中的要少2(12-14=-2)
4. initialBytesToStrip = 0 - 解码过程中,没有丢弃任何数据
在长度域前添加2个字节的Header。长度域的值(0x00000C) = 12。总数据包长度: 17=Header(2B) + 长度域(3B) + "HELLO, WORLD"

长度域的值为12B(0x000c)。编码解码后,长度保持一致,所以initialBytesToStrip = 0。参数应该为:
1. lengthFieldOffset = 2
2. lengthFieldLength = 3
3. lengthAdjustment = 0无需调整
4. initialBytesToStrip = 0 - 解码过程中,没有丢弃任何数据
Header与长度域的位置换了。总数据包长度: 17=长度域(3B) + Header(2B) + "HELLO, WORLD"
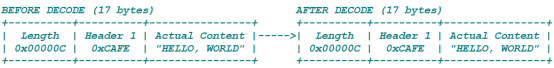
长度域的值为12B(0x000c)。编码解码后,长度保持一致,所以initialBytesToStrip = 0。参数应该为:
1. lengthFieldOffset = 0
2. lengthFieldLength = 3
3. lengthAdjustment = 2 因为长度域为12,而报文内容为12,但是我们需要把Header的值一起读取进来,需要告诉netty,实际读取的报文内容长度比长度域中的要多2(12+2=14)
4. initialBytesToStrip = 0 - 解码过程中,没有丢弃任何数据
带有两个header。HDR1 丢弃,长度域丢弃,只剩下第二个header和有效包体,这种协议中,一般HDR1可以表示magicNumber,表示应用只接受以该magicNumber开头的二进制数据,rpc里面用的比较多。总数据包长度: 16=HDR1(1B)+长度域(2B) +HDR2(1B) + "HELLO, WORLD"

长度域的值为12B(0x000c)
1. lengthFieldOffset = 1 (HDR1的长度)
2. lengthFieldLength = 2
3. lengthAdjustment =1 因为长度域为12,而报文内容为12,但是我们需要把HDR2的值一起读取进来,需要告诉netty,实际读取的报文内容长度比长度域中的要多1(12+1=13)
4. initialBytesToStrip = 3 丢弃了HDR1和长度字段
带有两个header,HDR1 丢弃,长度域丢弃,只剩下第二个header和有效包体。总数据包长度: 16=HDR1(1B)+长度域(2B) +HDR2(1B) + "HELLO, WORLD"

长度域的值为16B(0x0010),长度为2,HDR1的长度为1,HDR2的长度为1,包体的长度为12,1+1+2+12=16。
1. lengthFieldOffset = 1
2. lengthFieldLength = 2
3. lengthAdjustment = -3因为长度域为16,需要告诉netty,实际读取的报文内容长度比长度域中的要 少3(13-16= -3)
4. initialBytesToStrip = 3丢弃了HDR1和长度字段
MessagePack集成