如果把推荐系统比作一辆汽车,那推荐引擎可以看做是传动系统,把发送机、变速箱及底盘三大件串起来,为整车提供正常运行。本坑主要介绍推荐系统的中场核心推荐引擎,在推荐系统中的地位如图。
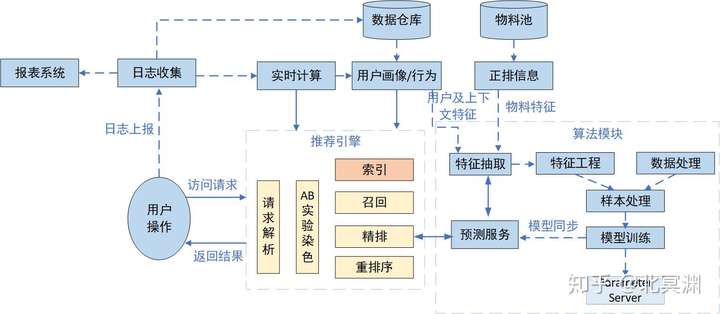 图1 推荐引擎是推荐系统的中场核心
图1 推荐引擎是推荐系统的中场核心
推荐引擎能够实时给用户提供推荐服务,用来解析用户请求,将物料数据与画像数据打通,匹配符合用户兴趣的物料,同时调用算法召回,控制整体候选集多样性。通过排序预测服务为候选集打分排序给出用户可能感兴趣的结果,并根据业务和体验规则对推荐结果进行重排序,呈现给用户最终结果。同时推荐引擎还承担着线上AB实验精准分桶的功能,保证实验流量的科学分配,提升实验效果的置信度。因此涉及推荐引擎核心功能的主要有用户请求解析、实验分桶染色、召回、排序、重排等模块。索引部分在上一篇文章有过概述,可根据系统规模评估是否纳入到整体推荐引擎中。
实验染色
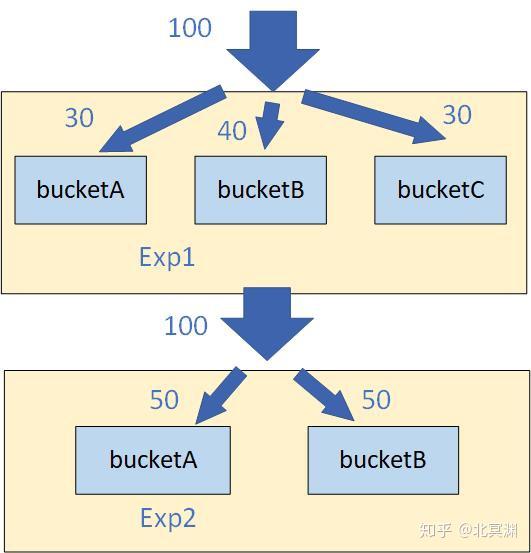
AB实验已成为绝大多数互联网公司面向用户展示不同策略的通用做法,尤其推荐系统千人千面,线上系统会有各种策略、算法需要快速迭代验证效果,科学准确的实验分桶策略能够均匀分配实验组对照组流量,同时互斥的实验需要互不干扰,例如在召回阶段做的实验A和B需要互斥,而和重排序阶段的实验C互不影响,在切分流量时需要考虑分层机制,同一层实验要求互斥,流量互不影响;不同层之间的实验并不相干,流量可以打通。目前基本思想都是参考Google的论文:《Overlapping Experiment Infrastructure: More, Better, Faster Experimentation》,具体可根据公司业务特点进行实现。
 分层实验框架原理
分层实验框架原理
一般实验配置通过一个管理平台,底层通过mysql数据库管理各实验增删改查,用户侧则根据用户id(cookie、设备id等)用于hash分桶标识,这里展示一个简单的分桶逻辑。
# 遍历所有实验,exp_list是从实验平台获取的有效实验列表
for exp in range exp_list:
# exp_name为唯一实验名,主要用于分层,配合用户deviceid,保证本层hash是唯一的
hashvalue = deviceid + '-' + exp.exp_name
# 将字符串哈希成int值并模100,这里看做每个实验为100%流量,同层互斥实验从这100%中切分流量桶
# 例如:{bucketA:20, bucketB:40}
hashint = hash(hashvalue)%100
# 存储当前用户走哪些实验桶
exp_map = {}
# 遍历该实验下所有分桶, 找到符合流量分配的桶后记录在exp_map中
for bucket_id, bucket_value range exp.buckets
: if hashint < bucket_value:
: exp_map[bucket_id] = True
break
else:
: hashint -= bucket_value
return exp_map 后续线上做实验时,只需在代码中判断若exp_map[bucketA]==True,则用户需要走bucketA实验桶控制的实验逻辑。
召回
物料池中的物料千千万,最终曝光给用户展示的只有几十甚至十几条,如果直接对所有物料计算排序无疑成本非常高,需要对物料进行初筛也就是召回用户可能感兴趣的一批候选集,一般是几百到一千条左右。召回的方式主要分为基于兴趣内容类,协同过滤类及算法类,最终候选集的呈现可以是这些召回的组合。
 召回框架
召回框架
兴趣内容召回
这时上篇内容介绍的用户画像和索引就该出场了,基于用户兴趣画像,匹配不同维度物料,用户喜欢体育类的,那就从体育类内容中选取最新/最热内容召回,非常直观且可解释性强。根据不同维度组成一级或多级索引可以组成多路兴趣召回,因为用户画像中各维度兴趣点都有权重,那召回对应物料的数量可根据权重自适应调整。有这些基础召回作为候选集,推荐系统就可以向后进行排序、重排序等工作,基础通路就可打通。
协同过滤召回
协同过滤Collaborative Filtering可分为基于用户的和基于物料的,基于用户的原则可理解为“将跟你看过相同物料的用户,他们看过的物料推荐给你”,即User Collaborative Filtering——UCF ,基于物料的原则可以理解为“将你看过物料的相似物料推荐给你”,即Item Collaborative Filtering——ICF,所以根本在于找到相似用户或相似物料的过程。
计算用户相似有Jaccard相似度、余弦相似度、皮尔逊相似度等。以较直观的Jaccard相似度作为基础版本的UCF,例如有用户A、B,两用户的相似度可以用sim(A,B) = |ra ∩ rb| / |ra ∪ rb|,ra、rb分别为两个用户产生行为的物料集,得分越高代表用户越相似,则基于UCF的召回流程如下,其他得分类相似度计算都可共用流程。
离线部分
1、拿到所有用户对应操作行为的物料,及user: item1,item2,item3...
2、对全量用户计算两两用户间相似度得分
3、对每个用户获取到得分排序最高的topN用户
4、获取topN用户的历史行为item并与目标用户的item做去重
5、将去重后的item存入以目标用户为key的redis中,userid:"item1,item2,item3...."
在线部分
1、获取用户id,读取redis拿到物料召回
基于ICF召回需要计算物料间的相似度,直观可以理解为文本、音频、图像、视频等物料类别中,通过NLP、图像理解、视频理解等方式综合计算出物料的向量表达embedding,通过embedding聚类出各物料最近似的物料,从而计算得到目标物料的相似物料。
另一种应用最多的还是基于向量做内积来计算相似度,所以问题又转化为如何得到用户和物料的向量embedding,这类方法就很多了,从MF矩阵分解到item2vec从用户直观行为计算用户和物料embedding。利用神经网络如yutube dnn及最新火热的图卷积网络GCN通过用户对物料行为的隐式特征表达构建更为丰富的embedding信息,此类模型训练计算更为复杂但在大数据量学习用户行为更加准确。通过高效的faiss服务快速计算embedding间的相似度,从而拿到用户可能感兴趣的物料。这类方法在使用时可以归纳为如下流程:
离线部分
1、拿到所有用户对应操作行为的物料,及user: item1,item2,item3...
2、搭建模型训练出各用户和物料的embedding向量
3、可以通过faiss找到目标用户的相似用户(群),获取相似用户的物料(同传统UCF)存入redis
在线部分
直接通过redis获取目标用户的物料候选集(同传统UCF)
或者
拿到目标用户近期操作的物料id,通过faiss服务获取这些物料embedding距离最近的物料候选集(传统ICF)
或者
通过目标用户id,直接从faiss服务中获取同用户embedding距离最近的物料候选集
可以看到,通过计算用户及物料的embedding,使用时更为灵活,从效果上通过向量可以将用户和物料的高维稀疏特征转化为稠密特征,同时也可表示出用户和物料的隐含关系。
算法类召回
严格来说协同过滤和各类embedding也是算法,但这里算法类召回主要聚焦于通过特征和模型来对所有物料进行排序,筛选出topN物料进入候选集,也就是常说的粗排。因为要在线对万到千万级别的物料进行排序,对计算性能有严格要求,因此这类算法需要模型较为简单,特征较少,主要使用线性模型例如LR、FM、GBDT等。
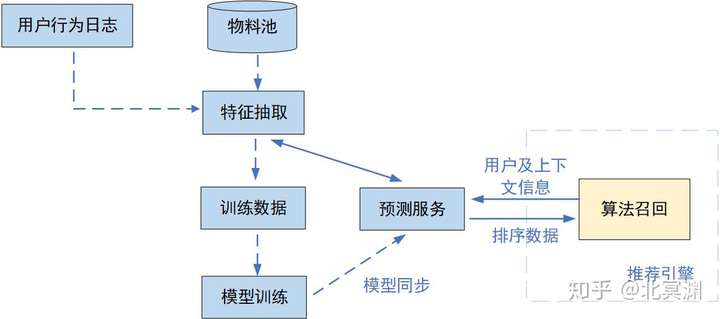
离线通过记录的用户、上下文及物料特征及样本数据训练好模型并同步给预测服务,线上获取到用户id及用户上下文,传入预测服务生成用户特征、上下文特征,结合物料特征及模型计算各物料的打分,排序后取topN作为召回集传回推荐引擎,流程如图。
 算法召回流程
算法召回流程
上述三类召回可以组合使用,一般为多路召回共同构成候选集,在召回过程中需要根据业务规则对用户曝光、点击或负反馈等数据进行过滤,同时召回层面也需要兼顾用户兴趣与多样性探索,否则用户可能陷入到细化看的内容越来越多,后面精排的操作空间较小,用户未知偏好的内容推不出来。因此需要在召回阶段让候选集类别更多样,协同过滤的原理能够产生一定多样性但也是在相似的圈子里打转,可以通过对更多类别或相似类别进行探索召回。另外多路召回会带来的问题就是各路召回的数量不好控制,如果是统一参数值设定多少才合适?如果要个性化参数就需要按用户实际召回的偏好来制定规则甚至一个小模型来计算,这里也是后续要优化的点。
在召回阶段还需要重要一环即新用户和新物料冷启动。新用户可以在进入应用时产品层面给出一些偏好选项来做基础画像兴趣,同时根据用户地域、设备信息、访问时段等信息协同出一些热门内容,加上各类别的热门内容,综合出候选集逐渐探索出用户兴趣及行为。新资源冷启是当物料新入物料池时,没有曝光点击等效果信息,虽然可以通过计算质量分等方式判断,但真正效果还需通过上线检验。可以将曝光量小于一定量(例如500)的物料单独建一个池子,通过ICF或embedding或用户兴趣单独进行冷启动召回,通过比较线上效果就可以判定物料的真实情况,结合质量分,效果差的资源就可以打入冷宫,不用进正式物料池给用户推荐了。
排序
也称精排阶段,针对召回出的候选集进行排序得到用户最可能感兴趣的内容,需要打分的物料只有几百上千条,因此可以使用更多维度的特征和复杂模型进行线上预测,这块流程同算法召回类似,统一调用排序预测服务即可,具体细节会放到本系列算法篇详述。初始搭建可以使用LR或GBDT等线性模型快速实现上线,作为baseline效果,后续通过不断迭代特征工程及模型调参,在线实验对比效果进行更新。
重排序
到这个阶段所有候选物料已经是按用户最可能点击的顺序排好,但这里需要重排来优化用户体验,例如同类内容的控量或打散,当然也需要根据用户行为进行策略上的调整,根据用户连续几刷点或不点来决定下一刷控量打散的度量等。同时还需要调整内容多样性来进行兴趣探索,特别是对于画像及行为不够丰富的用户。同时对于运营业务也需要在这里调整排序,比如时政内容的置顶、热点内容的加权、运营内容的提权或降权等。经过重排序后的所有物料,就整装待发,根据前端调用所需返回结果数量进行topN截断,展示给用户。
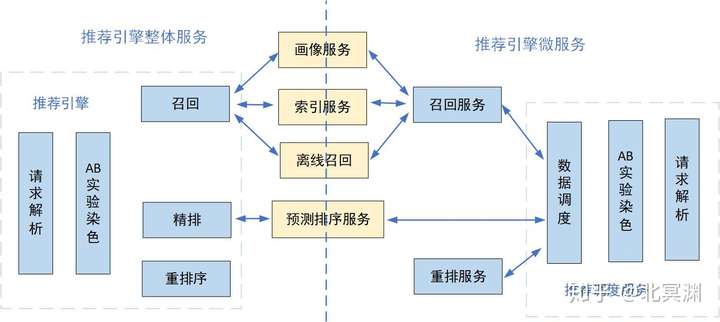
推荐引擎的本质是将各种功能模块串接起来,既保证各模块功能各自独立解耦,又将其有序统一,使数据流顺利流动起来。如果业务越做越大,在召回、排序及重排的逻辑越来越复杂,那可能需要用微服务架构将召回、排序(也可直接看做预测服务)、重排等模块分别抽离成单独服务,便于独立的团队维护独立的服务模块,同时也要尽可能优化网络接口减少网络开销。
作为服务端引擎,还需要有通用的监控信息监控各接口性能、模块性能、系统整体性能以及各阶段功能,这里就不展开说了。
