宽度优先(用队列和HashSet):
用来记录某个点到没到过,可以使用HashSet来将到达的点注册(防止已经进入队列的结点再次进入)
使用Queue来记录遍历的点,然后先进先出,加入它的next数组,且在加入队列和set中时,要判断,是否已经在set中了,若已存在,则忽略

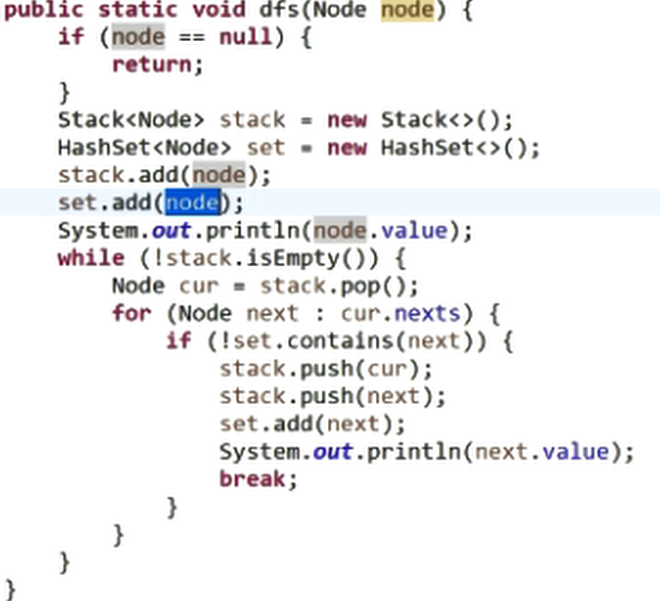
深度优先(用栈和HashSet):
用来记录某个点到没到过,可以使用HashSet来将到达的点注册(防止已经进入队列的结点再次进入)
使用Stack来记录遍历的点,然后先进后出,加入它的next数组,且在加入栈和set中时,要判断,是否已经在set中了,若已存在,则忽略
把每个结点走到头,才返回
PS:遍历当前结点的next数组时,要注意如果发现当前结点存在一个下一个结点,就暂时不继续向下寻找,而是按照当前结点,当前结点的next结点的顺序将它们两个添加进stack中,同时,将当前结点的next结点在set中注册。
宽度优先遍历
1, 利用队列实现
2, 从源节点开始依次按照宽度进队列, 然后弹出
3, 每弹出一个点, 把该节点所有没有进过队列的邻接点放入队列
4, 直到队列变空
深度优先遍历
1, 利用栈实现
2, 从源节点开始把节点按照深度放入栈,然后弹出
3, 每弹出一个点, 把该节点下一个没有进过栈的邻接点放入栈
4, 直到栈变空