转载:https://www.cnblogs.com/xiaobeibei26/p/6484849.html
Python多进程之multiprocessing模块和进程池的实现
1、利用multiprocessing可以在主进程中创建子进程,提升效率,下面是multiprocessing创建进程的简单例子,和多线程的使用非常相似
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
'''代码是由主进程里面的主线程从上到下执行的,我们在主线程里面又创建了两个子进程,子进程里面也是子线程在干活,这个子进程在主进程里面'''import multiprocessingimport timedef f0(a1): time.sleep(3) print(a1)if __name__ == '__main__':#windows下必须加这句 t = multiprocessing.Process(target=f0,args=(12,)) t.daemon=True#将daemon设置为True,则主线程不比等待子进程,主线程结束则所有结束 t.start() t2 = multiprocessing.Process(target=f0, args=(13,)) t2.daemon = True t2.start() print('end')#默认情况下等待所有子进程结束,主进程才结束 |
这里的结果是直接打印出end就结束了,因为添加了t.daemon=True,join方法在进程里面也可以用,跟线程的用法非常相似
2、进程之间默认是不能共用内存的
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
li = []def f1(i): li.append(i) print('你好',li)if __name__ =='__main__':#进程不能共用内存 for i in range(10): p = Process(target=f1,args=(i,)) p.start()'''每个进程都创建一个列表,然后添加一个因素进去, 每个进程之间的数据是不能共享的 |
结果如图
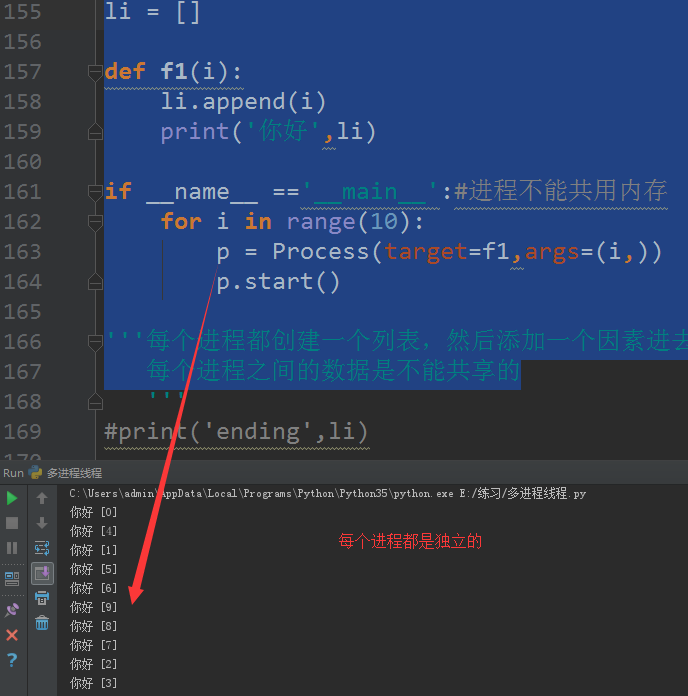
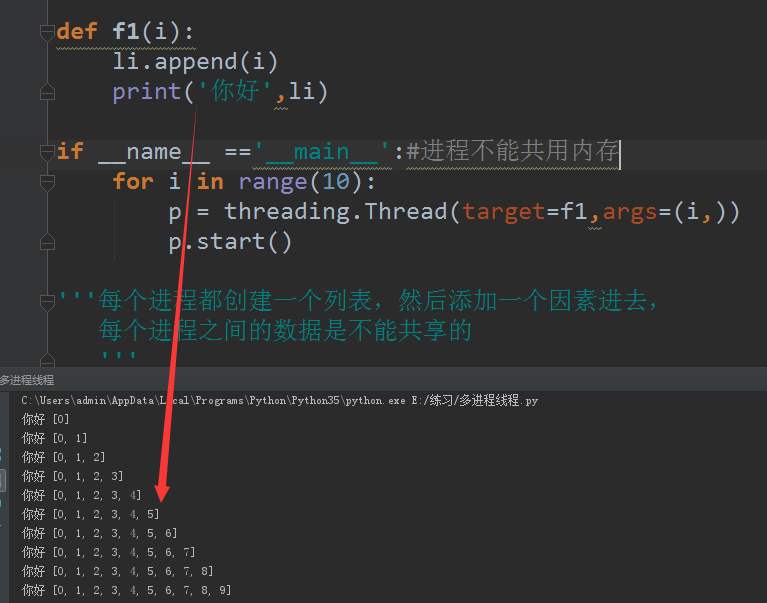
如果将代码改成threading,由于线程共用内存,所以结果是不一样的,线程操作列表li之前,拿到的是前一个线程操作过的li列表,如图
3、如果要进程之间处理同一个数据,可以运用数组以及进程里面的manager方法,下面代码介绍的是manager方法
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
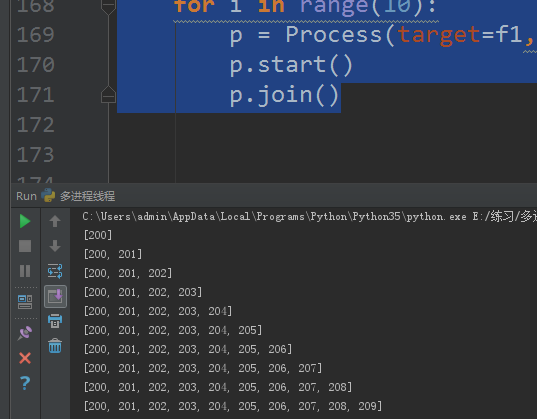
from multiprocessing import Processfrom multiprocessing import Managerdef f1(i,dic): dic[i] = 200+i print(dic.values())if __name__ =='__main__':#进程间默认不能共用内存 manager = Manager() dic = manager.dict()#这是一个特殊的字典 for i in range(10): p = Process(target=f1,args=(i,dic)) p.start() p.join() |
这里输出如图,表示每个进程都是操作这个字典,最后的输出是有10个元素
如果是普通的字典,输出如图
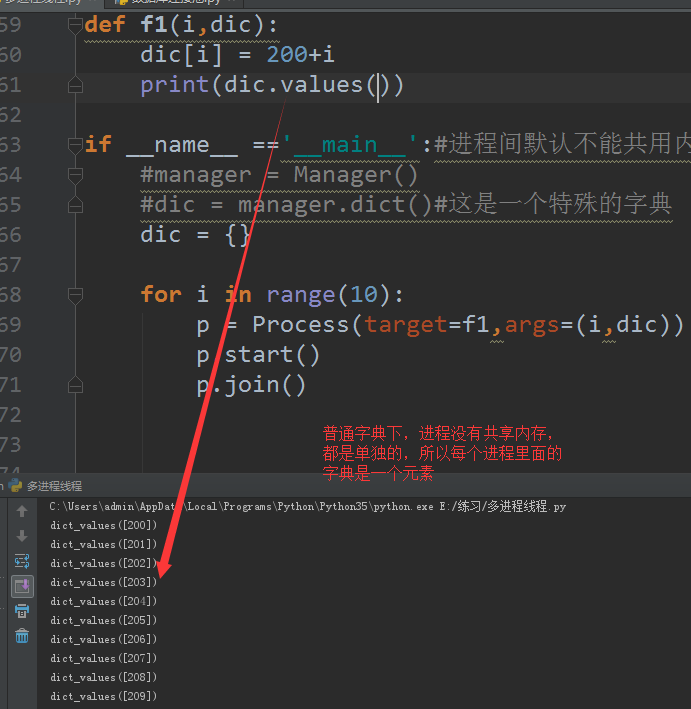
4、multiprocessing模块里面的进程池Pool的使用
(1)apply模块的使用,每个任务是排队执行的
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
from multiprocessing import Process,Poolfrom multiprocessing import Managerimport timedef f1(a): time.sleep(2) print(a)if __name__ =='__main__': pool =Pool(5) for i in range(5):#每次使用的时候会去进程池里面申请一个进程 pool.apply(func=f1,args=(i,)) print('你好')#apply里面是每个进程执行完毕了才执行下一个进程 pool.close()#执行完close后不会有新的进程加入到pool,join函数等待所有子进程结束 pool.join()#等待进程运行完毕,先调用close函数,否则会出错 |
运行结果如图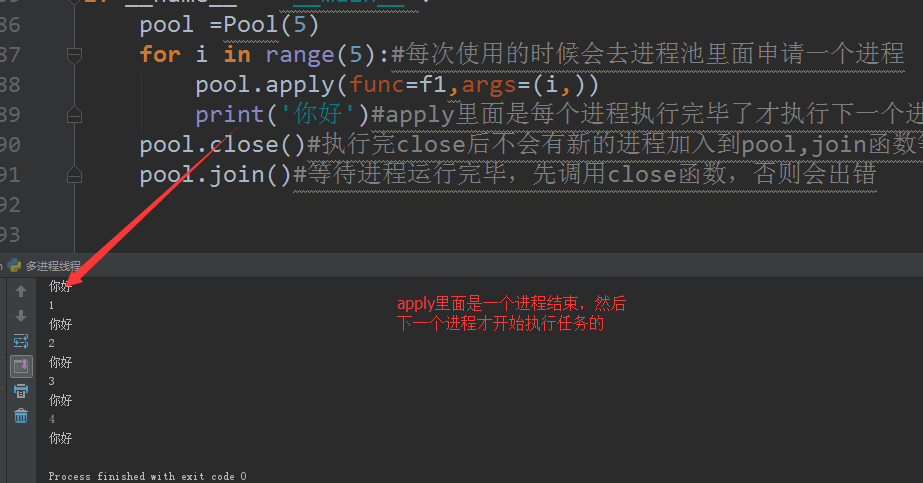
(2)apply_async模块,会比apply模块多个回调函数,同时是异步的
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
from multiprocessing import Process,Poolfrom multiprocessing import Managerimport timedef Foo(i): time.sleep(1) return i+50def Bar(arg): print(arg)if __name__ =='__main__': pool = Pool(5) for i in range(10): '''apply是去简单的去执行,而apply_async是执行完毕之后可以执行一 个回调函数,起提示作用''' pool.apply_async(func=Foo,args=(i,),callback=Bar)#是异步的 print('你好') pool.close()#不执行close会报错,因为join的源码里面有个断言会检验是否执行了该方法 pool.join()#等待所有子进程运行完毕,否则的话由于apply_async里面daemon是设置为True的,主进程不会等子进程,所欲函数可能会来不及执行完毕就结束了'''apply_async里面,等函数Foo执行完毕,它的返回结果会被当做参数 传给Bar''' |
结果如图
这两个方法的主要区别如图
