关系型数据库的核心内容是 关系 即 二维表
MYSQL的启动和连接
show variables; 【所有的变量】
1服务端启动
查看服务状态
sudo /etc/init.d/mysql status 状态
sudo /etc/init.d/mysql start 开启
sudo /etc/init.d/mysql stop 停止
.... restart 重启
.... reload 生效配置【热】,不是所有都可以生效
2 客户端连接
mysql -h 主机地址 -u 用户名 -p 密码
mysql -hlocalhost -uroot -p
库的命名规则:
1,数字,字母,__,但是不能是纯数字
2, 库名区分字母大小写
3,不能使用特殊字符 和 MYSQL关键字
基本操作
1,查看所有库,所有表
show databases;
show tables;
2. 创建库
create database 库名;
create database 库名 character set utf8; 设置库的字符集类型
如何更改库的默认字符集:
1 更改配置文件: 部分系统不一样 文件名【mysqld.cnf】
1 获取root 权限
2 cd/etc/mysql/mysql.d
3 cp mysqld.cnf mysqld.cnf.bak
4 subl mysqld.cnf
5 在[mysqld]下:
character_set_server=utf8 [更改库的默认字符集]
6 /etc/init.d/mysql restart
3.查看创建库的语句
show create database 库名;
4,查看当前所在位置库
select database();
5. 切换库
use 库名;
6.删除库
drop database 库名;
创建表:
表的基本操作:
1 创建表: 【表名.frm(表结构) 表名.ibd(表数据) 存储引擎innodb】
create table 【if not exist】表名(
字段名 数据类型,
字段名 数据类型,
字段名 数据类型
)character set utf8;


CREATE TABLE `test`.`users` ( `id` int(10) NOT NULL AUTO_INCREMENT, `name` varchar(20) DEFAULT NULL, `age` int(10) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
需要注意的是这个符号不是单引号,而是【`】这个符号
2 查看创建表的语句(字符集,存储引擎)
show create table 表名;
3 查看表结构,(详细信息)
desc 表名;
4 删除表
drop table 表名;
root@tedu:/home/tarena/下载# cd /var/lib/mysql 【查看表的存储路径,下面都是表的存储位置】
root@tedu:/var/lib/mysql# ls
auto.cnf ib_buffer_pool ib_logfile0 ibtmp1 mysql_upgrade_info sys
debian-5.7.flag ibdata1 ib_logfile1 mysql performance_schema text
【表名.frm(表结构) 表名.ibd(表数据) 存储引擎innodb】
断开与数据库连接:exit;|quit;|q;
数据类型
1 数值类型
1 整数 1个字节占8位
1 int 大整型(占用4个字节)32 取值范围:0~(2**32-1) 42亿多
2 tinyint 微小整型(占用1个字节)8 0~2**8-1
有符号(signed默认) :-128~127
无符号(unsigned) : 0~255
age tinyint unsigned;
3 smallint 小整型(2个字节)
4 bigint 极大整型(8个字节)
2 浮点型
1 float (占用4个字节,最多显示7个有效位)
字段名:float(m,n) M->总位数,m的最大为7 n->小数位位数
float(5,2) -999,99~999.99
1 浮点型 插入整数时,自动补全小数位位数
2 小数位如果多于指定位数,对指定位下一位四舍五入
2 double 最多显示15个有效位
字段名 double(m,n)
3 decimal(m,n)
1 存储空间(整数部分,小数部分分开存储)
规则:将9的倍数包装成4个字节
余数 字节
0 0
1-2 1
3-4 2
5-6 3
7-8 4
例:decimal(19,9)
整数部分:10/9=1余1 4字节+1字节 =5
小数部分:9/9=1余0 4字节+0字节 =4
消耗总共:9个字节
2 字符类型
1 char : 定长
char(宽度) 宽度取值范围:1~255 宽度指的是字符的宽度
char(20)
插入一个 'A' 也是占20个字节 ,没有20字节就补空格
2 varchar : 变长
varchar(宽度) 宽度取值范围 : 1~65535
3 text / longtext(4G) / blob / longblob
4 char 和 varchar 的特点为
1 char : 浪费存储空间,性能高
2 varchar : 节省存储空间,性能低
5 字符类型的宽度和数值类型宽度的区别
1 数值类型宽度为显示宽度,只用于select 查询时显示,和占用存储无关,可用zerofill查看效果
id int(3) zerofill,
2 字符类型的宽度超过后无法存储
3 枚举类型
1 单选 enum
sex enum(值1,值2,...)
2 多选 set
hobby set(值1,值2,...)
###插入记录时 'study,python,mysql'
4 日期时间类型
1 date: 'YYYY-MM-DD'
2 datetime: 'YYYY-MM-DD HH:MM:SS' 【不给值,默认返回null】
3 timestamp : 'YYYY-MM-DD HH:MM:SS' 【不给值,默认返回系统当前时间】
4 time : 'HH:MM:SS' 【不常用】
insert into 表(timesstamp) values(now());
【可调用now()函数直接获取当前时间插入】
日期时间函数
1 now() 返回服务器当前时间
2 curdate() 当前日期
3 date("1999-09-09 09:09:09") ---> 【1999-09-09】 提取年月日
4 time('...') 提取 时分秒
5 year('...') 提取 年
where 字段名 运算符(now()-interval 时间间隔单位);
时间间隔单位:
2 day | 3 hour | 1 minute | 2 year | 3 month
示例:
1
查询一天以内的 -----> select * from t2 where cztime>=(now()-interval 1 day)
查询一天之前,三天以内的记录 ----> SELECT * from t1 where cztime>=(now()-INTERVAL 15 day) and cztime<=(now()-INTERVAL 1 day)
表字段操作
1 语法 alter table 表名...
2 添加字段(add)
alter table 表名 add 字段 数据类型; 【默认添加到字段最后】
alter table 表名 add 字段 数据类型 first; 添加到字段首
alter table 表名 add 字段 数据类型 after 字段名; 添加到哪个字段之后
3 删除字段
alter table 表名 drop 字段名;
4 修改字段数据类型(modify)
alter table 表名 modify 字段名 新数据类型;
会受到表中已有数据的限制
5 修改表名(rename)
alter table 表名 rename 新表名;
6 修改字段名(change)
alter table 表名 change 原字段名 新字段名 数据类型;
运算符操作
数值比较&&字符比较&&逻辑比较
数值比较:= != > >= <=
字符比较: = !=
逻辑比较:
and 两个或者多个条件同时成立
or 有一个条件满足即可
...where country='蜀国' or country='魏国'; 列出蜀国和魏国的记录
范围内比较
between 值1 and 值2
in (值1,值2)
not in(值1,值2)
+------+-----------+--------+--------+------+---------+ | id | name | gongji | fangyu | sex | country | +------+-----------+--------+--------+------+---------+ | 1 | 诸葛亮 | 120 | 20 | 男 | 蜀国 | | 2 | 司马懿 | 119 | 25 | 男 | 魏国 | | 3 | 关羽 | 188 | 60 | 男 | 蜀国 | | 5 | 孙权 | 100 | 60 | 男 | 吴国 | +------+-----------+--------+--------+------+---------+ 4 rows in set (0.00 sec) mysql> select * from sanguo where (gongji between 100 and 200)and country='蜀国';
空: is null
非空: is not null
null: 空值,只能用is ,is not null 去匹配
'' :空字符串,只能用 =,!= 去匹配
模糊查询(like)
1 where 字段名 like 表达式
2 表达式
1,_ : 匹配单个字符
2, % : 匹配0到多个字符
select name from sanguo where name like "_%_"; #name中有两个字符以上的 select name from sanguo where name like "%"; #匹配所有,但不包括null select name from sanguo where name like "___"; #匹配名字为3个字符的 select name from sanguo where name like "赵%"; #匹配姓赵的英雄
表记录的管理:插入
插入语句,
insert into 表名 values(id1,'xxx'),(id2,'***')...; 【不用字段名,直接插入】
insert into 表名(字段1,字段2,字段3..) values(值1,值2,值3,...); 【剩下没有指定插入的值,将为成为空值(null)】
INSERT INTO list(soure) VALUES('2018-5-8') INSERT INTO list(soure) VALUES('2018-8-8'),('2019-9-8')
查询语句;
1,select * from 表名 where 条件;
2,select 字段1,字段2 from 表名
distinct : 不显示字段的重复值
1 。语法 select distinct 字段1,字段2 from 表名;
如果字段1的值和字段2的值全部相同,才会去重,
删除表记录(delete)
1 delete from 表名 where 条件; 【不加where条件 全部删除表记录】
更新表记录(update)
update 表名 set 字段1=值1,字段2=值2 where 条件
SQL高级查询
1 总结
3 select ... 聚合函数 from 表名
1 where ...
2 group by ...
4 having ...
5 order by ...
6 limit ...
2 order by... 给查询结果排序
1 order by 字段名 ASC(默认升序) / DESC(降序)
2 按防御值从高到低排序
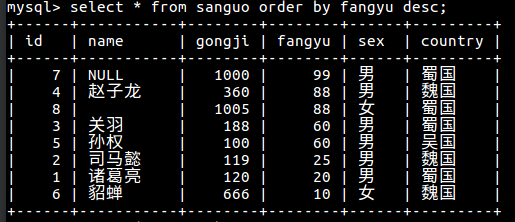
3 将蜀国英雄按攻击值从高到低排序
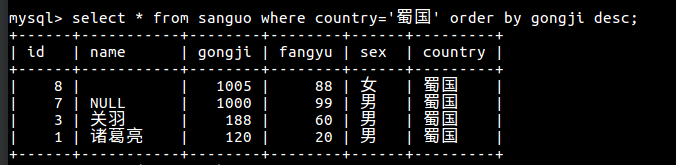
4 将魏蜀两国英雄中名字为3个字符的,按防御值升序排序

3 limit (永远放在SQL命令的的最后写)
1 显示查询记录的条数
2 用法
limit n;--->显示n条记录
limit m,n; -->从第m+1条记录开始,显示 n 条
3 分页
每页显示5条记录,显示第4页的内容
每页显示n条记录,显示第M页的内容
第M页,limit(m-1)*m,n
4 聚合函数
1 分类
avg(字段名):求该字段的平均值
sum(字段名):求和
max(字段名):最大值
min(字段名): 最小值
count(字段名):统计该字段记录的个数
select max(gongji) from sanguo;
select name,max(gongji) as max from sanguo; 引入别名函数 别名[max]
5 group by : 给查询的结果进行分组
1 查询表中都有哪些国家
select country from sanguo group by country;
2 计算每个国家的平均攻击力
先分组,再聚合, 再去重
select country,avg(gongji) from sanguo group by country;
3 select 之后的字段名如果没有在group by 之后出现,则必须要对该字段进行聚合处理(聚合函数)
4 查找所有国家中英雄数量最多的前2名的国家名称和英雄数量
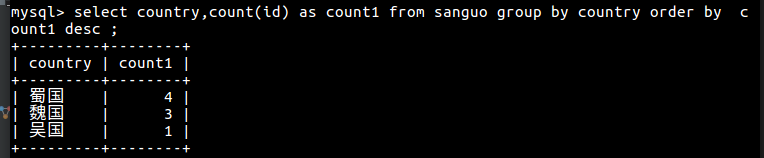
5 having 语句
1 作用 :对查询结果进行进一步的筛选
2 找出平均攻击力大于105的国家的前2名, 显示国家名称和平均攻击力

3
1 having 语句通常和group by 语句联合使用,过滤由 group by 语句返回的记录集
2 where 只能操作表中实际存在字段,having语句可操作由聚合函数生成的显示列
4 查询记录时做数学运算
1 运算符 + - * / %
2 查询时显示所有英雄攻击力翻倍
select id,name,gongji*2 as newgj from sanguo;
2 嵌套查询(子查询)
1 定义: 把内层的查询结果作为外层的查询条件
2 语法
select ... from 表名 where 字段名 运算符 (select ... from 表名 where 条件);
练习 找出每个国家攻击力最高的英雄的名字和攻击值

上面的查询可能会出现一些人BUG,所以为了防止BUG的发生,作出一点修改

多表查询。连表查询
1 SELECT * FROM list_char LEFT JOIN list_name on list_char.pid=list_name.pid
1 两种方式
1 笛卡尔积 : 不加where条件
使用一条记录跟后面的每个表的记录逐一匹配
2 加where 条件
select .. from 表1,表2 where 条件;
4 连接查询
1 内连接(inner join)
1 语法格式
select 字段名列表 from 表1
inner join 表2 on 条件;【可以加个 】

inner join(等值连接) 只返回两个表中联结字段相等的行
2 外连接
1 左连接(left join)
1 以左表为主 显示查询结果
2 select 字段名列表 from 表1
left join 表2 on 条件
left join 表2 on 条件
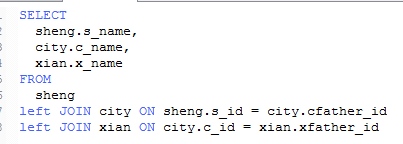
3 练习 ,
显示省,市详细信息,要求省全部显示
2 右连接(right join)
以右表为主显示查询结果,用法同左连接一模一样
left join(左联接) 返回包括左表中的所有记录和右表中联结字段相等的记录
right join(右联接) 返回包括右表中的所有记录和左表中联结字段相等的记录
inner join(等值连接) 只返回两个表中联结字段相等的行
锁
读锁(共享锁)
写锁(互斥锁,排他锁)
2 锁粒度
1 行级锁:Innodb
select : 加读锁,锁1行
update : 加写锁,锁1行
2 表级锁 : MyISAM
select : 加读锁,锁当前整张表
update : 加写锁,锁1张表
6 存储引擎(Engine)
1 查看所有存储引擎
show engines;
2 查看已有表的存储引擎;
show create table 表名;
3 创建表指定存储引擎
新表
create table 表名(...) engine=myisam;
已有表
alter tbale 表名 engine=myisam;
常用存储引擎的特点
1 InnoDB 特点
1,支持事务,外键,行级锁
2 共享表空间
表名.frm : 表结构和索引信息
表名.ibd : 表记录
2 MyISAM特点
1 支持表级锁
2 独享表空间
表名.frm 表结构
表名.myd 表记录 mydata
表名.myi 表索引 myindex
3 MEMORY存储引擎
1 数据存储在内存中,速度快
2 服务器重启,MYSQL服务重启后表记录消失
4 如何决定使用哪个存储引擎
1 执行查询操作多的表使用 MyISAM引擎 【使用 InnoDB节省资源,表加锁比行加锁节省资源】
2 执行写操作多的表使用 InnoDB
约束
1 作用 : 保证数据的一致性,有效性
2 约束分类
1 默认约束 (default)
插入记录时,不给该字段赋值,则使用默认值
sex enum('H','F') default 'S',
2 非空约束(not null)
不允许该字段的值为null
id int not null,
id int not null default 0
create table t1(
id int not null,
name varchar(15) not null,
sex enum('m','f','s') default 's',
course varchar(20) not null default 'python'
)character set utf8;
索引
1 定义 :
对数据库中表的一列或多列的值进行排序的一种结构(bTree)
2 优点
加快数据的检索速度
3 缺点
1 当对表中数据更新时,索引需要动态维护,降低数据的维护速度
2 索引需要占用物理存储空间
4 索引示例
使用 show variables like 'profiling' 查看当前状态
1 开启运行时间检测 : mysql> set profiling=1
2 执行查询语句 select name fromm t1 where name='lucy99999';
3 查看执行时间 show profiles;
4 在name 字段创建索引
create index name on t1(name);
5 再次执行查询语句 select name fromm t1 where name='lucy99999';
5 索引 排序都是bTree,,区别只是约束不一样
1 普通索引(index)
1 使用规则
1,可设置多个字段 ,字段值无约束
2 把经常用来查询的字段设置为索引字段
3 KEY标志 : MUL
2 创建
1 创建表时创建 【create table t1 (id int ,name varchar(15) ,index(name),index(id));】 【创建两个索引】
2 在已有表中创建索引 【create index 索引名 on 表名(字段名);】-->索引名一般写字段名
3 查看索引
1 desc表名;--->KEY标志为 MUL
2 show index from 表名;
4 删除index
drop index 索引名 on 表名;
2 唯一索引(unique)
1 使用规则:
1 可设置多个字段
2 约束:字段的值不允许重复,但可以为NULL
3 KEY标志 : UNI
2 创建
1 创建表时
unique(phnumber),
unique(cardnumber)
2 已有表
create unique index 索引名 on 表名(字段名);
3 查看,删除同普通索引
删除:drop index 索引名 on 表名;
3 主键索引(primary key)&&自增长属性(auto_increment)
1 使用规则
1 只能有一个字段为主键字段
2 约束:字段值不允许重复,也不能为NULL
3 KEY标志:PRI
4 通常设置记录编号字段id,能够唯一锁定一条记录
2 创建
1 创建表时
1 id int primary key auto_increment,
2 id int auto_increment,
name varchar(20) not null
primary key(id,name)) 复合主键
auto_increment=10000,... 【ID从10000开始】
2 已有表
alter table 表名 add primary key(id);
alter table 表名 auto_increment=10000; 【补充】
3 删除主键
1,先删除自增长属性(modify更改数据类型)
alter table 表名 modify id int;
2 删除主键
alter table 表名 drop primary key;
4 外键(foreign key)
***明天讲***
数据导入
1 作用: 把文件系统中的内容导入到数据库中 出现乱码情况往下看
2 语法格式
load data infile '文件名'
into table 表名
fields terminated by '分隔符'
lines terminated by '
'
3 导入数据库中
1 在数据库中创建对应的表
2 执行数据导入
1 查看搜索路径
show variables like 'secure_file_priv';
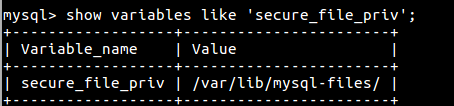
2 拷贝文件到上图路径
3 注意路径和分隔符

乱码情况下,,更改字符编码

4 导出数据
语法格式
select ... from 表名
into outfile '文件名'
fields terminated by '分隔符'
lines terminated by ' ';

导入导出时,特别需要注意文件路径,单词的正确程度
5 查看,更改文件权限
1 【ls -l score.txt】
r : 读
w : 写
x :可执行
表的复制
1 语法
create table 表名 select ... from 表名 where 条件;
2 示例

3
复制下表,且若每页显示2条记录,复制第3页的内容

4 复制表结构
create table 表名 select ... from 表名 where false;

1 外键
1 定义: 让当前表的字段值在另一张表的范围内去选择
2 语法格式
foreign key (参考字段名)
regerances 主表(被参考字段名)
on delete 级联动作
on update 级联动作;
3 使用规则
1 主表,从表字段数据类型要一致
2 主表 : 被参考字段是主键
3 创建主键

4 删除外键
alter table 表名 drop foreign key 外键名;
外键名查看 : show create table 表名; -- >CONSTRAINT `bjtab_ibfk_1` FOREIGN KEY (`stu_id`) REFERENCES `jftab` (`id`)【红字为外键名】
5 已有表创建主键
alter table bjtab add foreign key(stu_id) references jftab(id);
6 级联动作:
1 cascade 数据级联删除,级联更新(参考字段)
2 restrict(默认)
如果从表中有相关联记录,不允许主表操作
3 set null
主表删除,更新,从表相关联记录字段值为null,
MYSQL 用户账户管理
1 开启mysql远程连接(获取root权限 改配置文件)
bind-address
2 用root 用户添加授权用户
1 用root 用户登录mysql
2 授权
mysql> grant 权限列表 on 库名.表名 to "用户名"@"%" identified by "密码" with grant option;
权限列表 : all privileges | select | update
库名.表名 : db4.* | *.*(所有库的所有表)
3 示例
1 添加授权用户tiger,密码123,对所有库的所有表有所有的权限,可从任何IP去连接
数据备份(mysqldump,在linux终端操作)
1 命令格式
msyqldump -u用户名 -p 源库名 > ***.sql
回车输入数据库密码
2 源库名的表示方式
--all-databases 备份所有库
库名 备份一个库
-B 库1 库2 库3 备份备份多个库
库名 表1 表2 表3 备份多张表
数据恢复
1 命令格式(linux终端)
mysql -u用户名 -p 目标库名 < ***.sql
2 从所有库备份all.sql中恢复某一个库
mysql -u 用户名 -p --one-database < all.sql
注意:
1,恢复库时,如果恢复到原库会将表中的数据覆盖,,新增表不会删除
2 恢复库时,如果库不存在,则必须先创建空库
MYSQL 调优
1 创建索引
在select .where .order by常涉及到的字段建立索引
2 选择合适的存储引擎
读操作多 : MyISAM
写操作多 : InnoDB
3 SQL语句优化(避免全表扫描)
1 where 子句尽量不使用 != ,否则放弃索引
2 尽量避免 NULL判断,否则全表扫描
优化前 :
select number from t1 where number is null;
优化后 :
在number 字段设置默认值0,确保number 字段无NULL
select number from t1 where number=0
3 尽量避免用or 连接条件,否则全表扫描
优化前:
select id from t1 where id=10 or id=20
优化后:
select id from t1 where id=10
union all
select id fromm t1 where id=20
4 模糊查询尽量避免使用前置 % ,否则全表扫描
select variable from t1 where name="%secure%";
5 尽量避免使用 in 和 not in,否则全表扫描
优化前
select id from t1 where id in (1,2,3,4);
优化后
select id from t1 where id between 1 and 4;
6 不能使用select * ...
用具体字段代替*,不要返回用不到的任何字段
事务和事务回滚
1 定义 : 一件事从开始发生到结束的整个过程。
2 作用 : 确保数据一致性
3 事务和事务回滚应用
1 SQL命令会 autocommit 到数据库执行
2 事务操作
1 开启事务
mysql> begin; | mysql> start transactions;
mysql> SQL命令...
##此时autocommit 被禁用##
2 终止事务
mysql> commit; | rollback;
1 python交互
1 python3
模块名: pymysql
安装 : sudo pip3 install pymysql
sudo pip3 install pymysql==版本号 【安装指定版本】
离线:pymysql.tar.gz
解压:setup.py
python setup.py install 【必须加上install】
2 python2
模块名 : MySQLdb
安装 : sudo pip install mysql-python
pymysql 使用流程
1 建立数据库连接对象(db=pymysql.connect(...))
2 创建游标对象CUR(cur=db.cur***)
3 游标对象: cur.execute('SQL命令')
4 提交 db.commit
5 关闭游标对象
6 关闭数据库连接对象
connet连接对象
1 db=pymysql.connet(参数列表)
1 host =主机地址
2 user =用户名
3 password =密码
4 database =库名
5 charset =编码方式,推荐utf8
6 port =端口号
2 db (数据库连接对象)的方法
1 db.close()断开连接
2 db.commit()提交到数据库执行
3 db.cursor()游标对象,用来执行sql命令
4 db.rollback()回滚
3 cursor 游标对象的方法
1 erxecute(sql命令) : 执行SQL命令
2 close() : 关闭游标对象
3 fetchone() : 获取查询结果的第1条数据
4 fetchmany(n): 获取N条记录
5 fetchall() :获取所有记录
orm(Object Relation Mapping) 对象关系映射
#查询一个表是否存在 SELECT table_name FROM information_schema.TABLES WHERE table_name ='tablename';