定义
存储过程:就是为以后的使用而保存的一条或多条 MySQL语句的集合。可将其视为批文件,虽然它们的作用不仅限于批处理。
个人使用存储过程的原因就是因为 存储过程比使用单独的SQL语句要快
有如下表(名为 a)
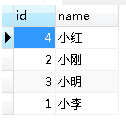
其下,所有都可以用一条sql解决,但是我为了熟悉 存储过程,而采用函数式来进行书写
简单案例 1 : 创建函数 name
, 需要传入 id值,返回 name值:
# 创建一个名为 name的存储过程
DELIMITER // create procedure name ( in _id int ) BEGIN select name from a where id=_id; END // DELIMITER;
其中, DELIMITER //告诉命令行实用程序使用 //作为新的语句结束分隔符,
可以看到标志存储过程结束的 END定义为END//而不是END; 。
这样,存储过程体内的 ;仍然保持不动,并且正确地传递给数据库引擎。
最后,为恢复为原来的语句分隔符,可使用 DELIMITER ;。
除符号外,任何字符都可以用作语句分隔符。如果你使用的是 mysql命令行实用程序,在阅读本章时请记住这里的内容。
在运行此存储函数之后,得到 如下图
简单案例2 创建函数 name_1
要求传入id值,返回id对应的name字段,保存到变量 @temp中传入的变量需要加@符号,否则会报错
[Procedure execution failed 1414 - OUT or INOUT argument 2 for routine test.name_1 is not a variable or NEW pseudo-variable in BEFORE trigger]
DELIMITER // create procedure name_1 ( in _id int, out name_ varchar(255) ) BEGIN select name into name_ from a where id=_id; END // DELIMITER;
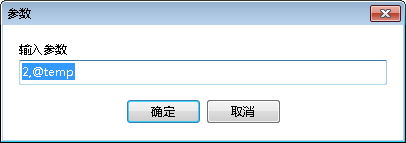
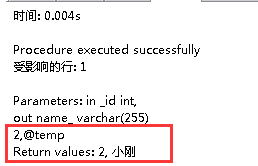
需要注意的是,在运行的时候,需要传入id值,和变量名,如下图(使用navicat),得出结果为小刚
简单案例3 创建函数 name_2
需要传入id值,对id值+1之后,返回name值
DELIMITER // create procedure name_2 ( in _id int, out name_ varchar(255) ) BEGIN DECLARE id_add int; ##声明变量 id_add select id into id_add from a where id=(_id+1); select name into name_ from a where id=id_add; END // DELIMITER;
讲解: 拿到 +1之后的id 放入id_add