词频统计
简单英语词频统计
# 词频:单词出现的次数
f = open(r'D:上海Python11期视频预科班hamlet.txt','r',encoding='utf8')
data = f.read().lower()
# print(data)
data_split = data.split(' ')
# print(data_split)
count_dict = {}
for word in data_split:
if word not in count_dict:
count_dict[word] = 1
else:
count_dict[word] += 1
# print(count_dict)
def func(i):
return i[1]
lt = list(count_dict.items())
lt.sort(key=func)
lt.reverse()
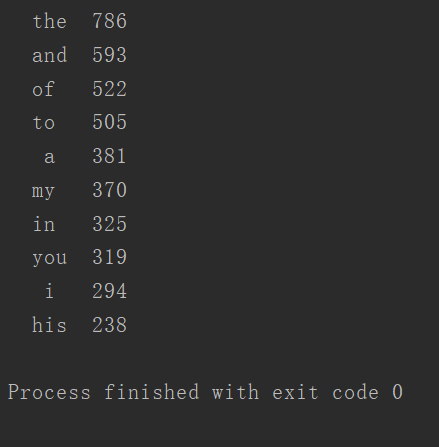
for i in lt[0:10]:
print(f'{i[0]:^7}{i[1]^5}')
简单中文词频统计
import jieba
f = open(r'F:pythonxm7.19day06 hreekingdoms.txt','r',encoding='utf8')
data = f.read()
data_jieba = jieba.lcut(data)
count_dict = {}
for word in data_jieba :
if len(word) == 1 :
continue
if word in {"次日","引兵","军马","左右","将军", "却说", "荆州", "二人","如何","军士","不可", "不能", "如此", "商议"}:
continue
if '曰' in word :
word = word.replace('曰','')
if word == '玄德' :
word = '刘备'
# if word == '孔明曰':
# word = '孔明'
# elif word == '玄德曰':
# word = '玄德'
if word in count_dict :
count_dict[word] += 1
else:
count_dict[word] = 1
def func(i):
return i[1]
data_list = list(count_dict.items())
data_list.sort(key=func)
data_list.reverse()
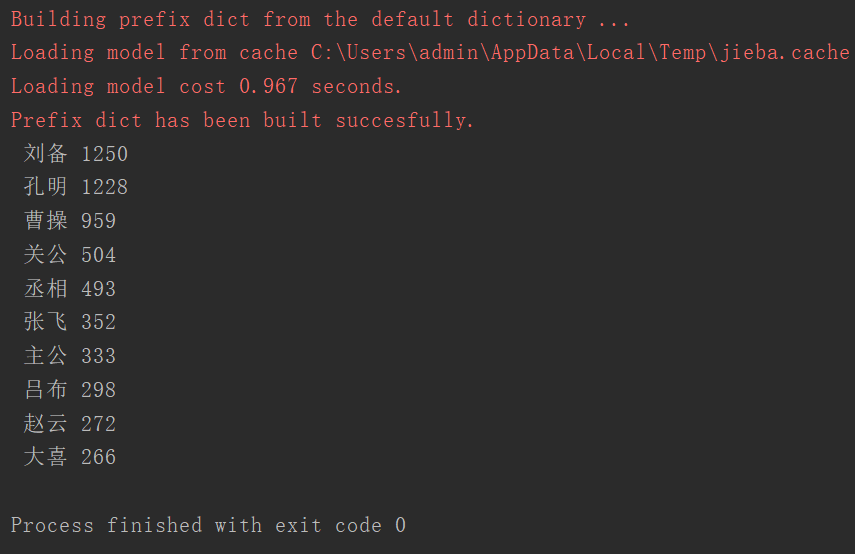
for i in data_list[0:10] :
print(f'{i[0]:^4}{i[1] ^ 6}')
作 者:豆瓣酱瓣豆
出 处:https://www.cnblogs.com/chenziqing/
查看其它博文请点击:https://www.cnblogs.com/chenziqing/
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
微信:
