数据库分类
层次型数据库 Hierarchical Database HDB
将数据通过层次结构(树形结构)存储,层次型数据库现在很少使用。
关系型数据库 Relational Database RDB
和Excel一样,使用行列二维表的结构管理数据,使用专门的SQL(Structured Query Language数据化查询语言)语言对数据进行操作。
RDB使用的DBMS(Database Managment System)称为RDBMS(Relational Database Management Language),常用的如下:
-Oracle Database
-SQL Server
-DB2
-PostgreSQL
-MySQL
面向对象数据库(Object Oriented Database OODB)
将数据以及数据的操作抽象为对象进行管理
XML数据库(XML Database XMLDB)
使用xml形式存储,可以对大量数据进行高速处理
键值存储系统(Key-Value Store KVS)
使用键值对存储数据,可以理解为关联数组或者散列hash
SQL语句和种类
标准化SQL和特定SQL
ISO制定了SQL标准,不同的SQL厂家(Oracle,DB2,MySQL)会添加特定的SQL。
DDL Data Definition Language 数据定义语言 用于创建或者删除存储数据用的数据库或者数据库中的表
CREATE 创建数据库和表
DROP 删除数据库和表
ALTER 修改数据库和表
创建数据库
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name
[create_specification] ...
create_specification:
[DEFAULT] CHARACTER SET [=] charset_name
| [DEFAULT] COLLATE [=] collation_name
创建表
参考 https://dev.mysql.com/doc/refman/5.7/en/create-table.html
修改数据库
ALTER {DATABASE | SCHEMA} [db_name]
alter_specification ...
ALTER {DATABASE | SCHEMA} db_name
UPGRADE DATA DIRECTORY NAME
alter_specification:
[DEFAULT] CHARACTER SET [=] charset_name
| [DEFAULT] COLLATE [=] collation_name
可以修改数据库编码,排序以及数据库名称。
ALTER DATABASE #mysql50#.miya1102 UPGRADE DATA DIRECTORY NAME;修改库名
修改数据库表
参考 ttps://dev.mysql.com/doc/refman/5.7/en/alter-table.html
删除数据库
DROP {DATABASE | SCHEMA} [IF EXISTS] db_name
数据库删除后会同时删除所有的表信息(数据恢复可以设置binlog防止误删除)。
删除数据库表
DROP [TEMPORARY] TABLE [IF EXISTS]
tbl_name [, tbl_name] ...
[RESTRICT | CASCADE]
清空表
TRUNCATE [TABLE] tbl_name
DML Data Manipulation Language 数据操作语言 查询或者表更表中的记录
SELECT 查询表中数据
INSERT 向表中插入数据
UPDATE 更新表中数据
DELETE 删除表中数据
插入数据
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
[PARTITION (partition_name [, partition_name] ...)]
[(col_name [, col_name] ...)]
{VALUES | VALUE} (value_list) [, (value_list)] ...
[ON DUPLICATE KEY UPDATE assignment_list]
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
[PARTITION (partition_name [, partition_name] ...)]
SET assignment_list
[ON DUPLICATE KEY UPDATE assignment_list]
INSERT ... SELECT(从现有表查询数据并插入目标表)
INSERT INTO tbl_temp2 (fld_id)
SELECT tbl_temp1.fld_order_id
FROM tbl_temp1 WHERE tbl_temp1.fld_order_id > 100;
INSERT ... ON DUPLICATE KEY UPDATE (KEY值重复时进行更新操作,否则进行插入操作)
INSERT INTO t1 (a,b,c) VALUES (1,2,3)
ON DUPLICATE KEY UPDATE c=c+1;
如果存在c=3的数据,执行完成后c变成4.
INSERT [LOW_PRIORITY | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
[PARTITION (partition_name [, partition_name] ...)]
[(col_name [, col_name] ...)]
SELECT ...
[ON DUPLICATE KEY UPDATE assignment_list]
value:
{expr | DEFAULT}
value_list:
value [, value] ...
assignment:
col_name = value
assignment_list:
assignment [, assignment] ...
可以使用REPLACE来替换旧有的值,相当于INSERT IGNORE。
查找数据
mysql可以从一个或者多个表查询数据,并且支持子查询。
UNION(联合查询)
SELECT ...
UNION [ALL | DISTINCT] SELECT ...
[UNION [ALL | DISTINCT] SELECT ...]
第一张表的列名作为结果的列名,使用ALL不会删除重复行,DISTINCT为默认值,删除重复结果。
如果需要使用ORDER BY,就要将查询子句使用括号括起来。如果需要对最终结果使用ORDER BY,也需要将每个子句括起来。
subquery(子查询)
SELECT * FROM t1 WHERE column1 = (SELECT column1 FROM t2);
SELECT * FROM t1称为外查询,SELECT column1 FROM t2称为子查询。
子查询可以用于查询比较结果,比如
SELECT * FROM t1
WHERE column1 = (SELECT MAX(column1) FROM t1);
子查询可以使用ANY, IN或者SOME(SOME和ANY是一样的)
格式为 select .. comparison_operator ANY | IN | SOME (subquery)
comparison_operator:= > < >= <= <> !=
ANY 满足任一子查询条件即可
ALL 满足子查询的所有查询
SELECT s1 FROM t1 WHERE s1 = ANY (SELECT s1 FROM t2);
SELECT s1 FROM t1 WHERE s1 IN (SELECT s1 FROM t2);
ROW子查询(可以匹配多个子查询的结果字段,操作符 = > < >= <= <> != <=>(安全比较符号,可以比较NULL))
SELECT * FROM t1
WHERE (col1,col2) = (SELECT col3, col4 FROM t2 WHERE id = 10);
SELECT * FROM t1
WHERE ROW(col1,col2) = (SELECT col3, col4 FROM t2 WHERE id = 10);
子查询使用EXISTS和NOT EXISTS(将子查询作为判断条件,有结果则执行父查询)
SELECT DISTINCT store_type FROM stores s1
WHERE NOT EXISTS (
SELECT * FROM cities WHERE NOT EXISTS (
SELECT * FROM cities_stores
WHERE cities_stores.city = cities.city
AND cities_stores.store_type = stores.store_type));
子查询使用AVG(),SUM(),MAX(),MIN(),COUNT()这样的聚合函数,只会返回一个查询结果称为标量子查询(Scalar subquery)。标量子查询可以查询出符合条件的值,但是需要注意的是标量子查询只能返回一个查询结果,返回多个结果会发生错误。
关联子查询
当标量子查询需要进行分组时(返回多个结果),可以使用关联子查询(即将最外层查询的结果与子查询结果使用where进行比较(=等等)。
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[HIGH_PRIORITY]
[STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT]
[SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
select_expr [, select_expr ...]
[FROM table_references
[PARTITION partition_list]
[WHERE where_condition]
[GROUP BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[PROCEDURE procedure_name(argument_list)]
[INTO OUTFILE 'file_name'
[CHARACTER SET charset_name]
export_options
| INTO DUMPFILE 'file_name'
| INTO var_name [, var_name]]
[FOR UPDATE | LOCK IN SHARE MODE]]
更新表数据
UPDATE [LOW_PRIORITY] [IGNORE] table_reference
SET assignment_list
[WHERE where_condition]
[ORDER BY ...]
[LIMIT row_count]
value:
{expr | DEFAULT}
assignment:
col_name = value
assignment_list:
assignment [, assignment] ...
DCL Data Controller Language 数据控制语言 用来确认或者取消对数据库中数据的表更,以及对数据库操作权限进行设置
COMMIT 确认对数据库数据进行表更
ROLLBACK 取消对数据库数据进行变更
GRANT 赋予用户操作权限
REVOKE 取消用户操作权限
建表语句
CREATE TABLE 表名
( 列名1,数据类型,列所需约束,
列名2,数据类型,列所需约束,
...,
表约束1,表约束2...);
CREATE TABLE Shohin
(shohin_id CAHR(4) NOT NULL,
shohin_mei VARCHAR(100) NOT NULL,
shohin_bunrui INTEGER ,
hanbai_tanka INTEGER ,
torokubi DATE ,
PRIMARY KEY (shohin_id));
MySQL数据类型
Numeric 数字类型
INTEGER | INT
默认创建的都是有符号整型数据(signed)
| Type | Storage (Bytes) | Minimum Value Signed | Minimum Value Unsigned | Maximum Value Signed | Maximum Value Unsigned |
|---|---|---|---|---|---|
| TINYINT | 1 | -128(2^7) | 0 | 127(2^7-1) | 255(2^8) |
| SMALLINT | 2 | -32768 | 0 | 32767 | 65535 |
| MEDIUMINT | 3 | -8388608 | 0 | 8388607 | 16777215 |
| INT | 4 | -2147483648 | 0 | 2147483647 | 4294967295 |
| BIGINT | 8 | -2^63 | 0 | 2^63-1 | 2^64-1 |
MySQL中TINYINT(1)和TINYINT(2)的区别(只有使用了zerofill并且设置为unsigned才有区别)
CREATE TABLE test (
id int(11) NOT NULL AUTO_INCREMENT,
str varchar(255) NOT NULL,
state tinyint(1) unsigned zerofill DEFAULT NULL,
state2 tinyint(2) unsigned zerofill DEFAULT NULL,
state3 tinyint(3) unsigned zerofill DEFAULT NULL,
state4 tinyint(4) unsigned zerofill DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=MyISAM AUTO_INCREMENT=6 DEFAULT CHARSET=utf8
insert into test (str,state,state2,state3,state4) values('csdn',4,4,4,4);
select * from test;
结果:
id str state state2 state3 state4
1 csdn 4 04 004 0004
NUMERIC和DECIMAL
MYSQL中DECIMAL就是NUMERIC的实现,所以他们的作用是一样的。
用来表示精确的数字比如货币是一般使用DECIMAL,根据国际会计规定,需要保留四位小数。
使用方法
column_name DECIMAL(P,D);
在上面的语法中:
- P是表示有效数字数的精度。 P范围为1〜65。
- D是表示小数点后的位数。 D的范围是0~30。MySQL要求D小于或等于(<=)P。
浮点型数据
MYSQL使用FLOAT和DOUBLE两种浮点型数据。
可以使用FLOAT(M,D)或者FLOAT以及DOUBLE(M,D) M表示数字精度,D表示小数点后位数,DOUBLE PRECISION(M,D)。
float的范围为-2^128 ~ +2128,也即-3.40E+38(-3.40*1038) ~ +3.40E+38;double的范围为-2^1024 ~ +2^1024,也即-1.79E+308 ~ +1.79E+308。
比特类型数据
使用BIT存储比特类型数据,BIT(M) enables storage of M-bit values. M can range from 1 to 64.
字符串类型数据
CHAR和VARCHAR用来存储字符串数据,两者的区别就是最大数据范围。
CHAR(M)和VARCHAR(M)M表示可以存储的最大长度,CHAR的数据长度范围为0到255,VARCHAR的数据长度范围为0到65535。
BINARY和VARBINARY两种类型和CHAR和VARCHAR两种类型高度一致,唯一的区别就是其存储的是二进制的字符串数据。
大数据量类型
BLOB和TEXT可以存储大数据量的字符串类型。BLOB可以存储照片(其存储的是二进制数据),而TEXT只能保存文本信息。
一般情况下避免使用BLOB和TEXT,因为对其进行的删除操作会导致数据库留下空洞,依然会占用数据库内存,解决的方法是使用OPTIMEIZE TABLE回收资源。
查询BLOB和TEXT数据的时候,尽量使用合成索引(对于BLOB或者TEXT数据进行散列MD5()函数),可以提升查询速度。
TEXT值被建立索引后,mySQL在其末尾填充空格,则如果不同的TEXT值具有相同的前缀,会发生键值重复错误,BLOB不存在这样的问题。
BLOB和TEXT列不能具有DEFAULT值。
BLOB和TEXT排序时使用的是前max_sort_length个字符,如果需要可以修改:SET max_sort_length = 2000;
BLOB和TEXT的最大大小可以进行设置。
枚举类型
ENUM和SET可以放在一起看,ENUM的使用方法是定义列为ENUM('a','b','c'),那么列的值只能为其中之一。SET定义列为SET('one', 'two'),那么其值可以是'','one','two','one,two'。
stackoverflow上面有个高分答案是ENUM可以理解为单选字段(radio fields),SET可以理解为多选字段(checkbox fields)。
ENUM的元素数量理论限制是65535,实际是不超过3000.
日期和时间类型
DATE, DATETIME, TIMESTAMP
DATE用来表示纯日期格式,形如'YYYY-MM-DD' ,区间为 '1000-01-01' 到 '9999-12-31'.
DATETIME用来表示日期和时间,形如'YYYY-MM-DD HH:MM:SS',区间为'1000-01-01 00:00:00' 到 '9999-12-31 23:59:59'.
TIMESTAMP用来表示日期和时间,形如'YYYY-MM-DD HH:MM:SS',区间为 '1970-01-01 00:00:01' UTC到 '2038-01-19 03:14:07' UTC.
DATETIME和TIMESTAMP可以设置默认值及自动更新为当前时间,具体可以参考https://dev.mysql.com/doc/refman/5.7/en/timestamp-initialization.html。
CREATE TABLE t1 (
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
dt DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
TIME
TIME的格式是'HH:MM:SS',区间为'-838:59:59' to '838:59:59'(大时间使用'HHH:MM:SS',可能表示两个时间之间的间隔)。
YEAR
YEAR的格式是YYYY,区间为1901到2155,空值为0000.
空间数据类型
涉及较少,有需要再做相应的了解(https://dev.mysql.com/doc/refman/5.7/en/spatial-types.html)。
聚合查询
聚合查询用于处理一组数据
| Name | Description |
|---|---|
| AVG() | 返回平均值 |
| COUNT() | 计算表中记录数 |
| SUM() | 计算总值 |
| MAX() | 返回最大值 |
| MIN() | 返回最小值 |
聚合函数会忽略NULL值。
聚合函数一般搭配 GROUP BY使用,如果不使用GROUP BY即相当于将每一行数据单独分组。
只有Select和Having子句可以使用聚合函数
select t1 from s1 where sum(t1) > 2; //函数sum()使用错误,只有select和having子句可以使用
Having
制定特定条件用来分组
select 列名1,列名2...
from 表名
group by 列名1,列名2,列名3
having 分组条件
事务
事务是需要在同一处理但愿中执行的一系列更新操作的集合
创建事务
MYSQL使用自动提交,DML语句会自动被执行,而使用START TRANSACTION会关闭自动提交,直到调用COMMIT才会提交DML,ROLLBACK会回退事务所有DML。
START TRANSACTION(BEGIN);
DML1;
DML2;
...
COMMIT(ROLLBACK);
ROLLBACK对于DDL(数据库定义语句)不起作用。
事务隔离级别 Transaction Isolation Levels
事务隔离级别分类
REPEATABLE READ 可重复读取
InnoDB的默认事务级别。同一事物内第一次读取MYSQL会创建快照,以后的读取结果都是这个快照。(可能会有幻读情况,即并发事务修改了数据,事务完成后再次查询出现不一样的结果)
READ COMMITTED 读已提交
同一事务内,每次读取获取的都是独立的快照结果,可能会有不可重复读的问题(并发事务可能导致无法预料的错误)。
READ UNCOMMITTED 读未提交
事务所作的修改在未提交前,其他并发事务是可以读到修改后的值,可能会出现脏读问题。
SERIALIZABLE 可串行化
解决了幻读的问题,但是性能比较低。
设置事务隔离级别
SET [GLOBAL | SESSION] TRANSACTION
transaction_characteristic [, transaction_characteristic] ...
transaction_characteristic: {
ISOLATION LEVEL level
| access_mode
}
level: {
REPEATABLE READ
| READ COMMITTED
| READ UNCOMMITTED
| SERIALIZABLE
}
access_mode: {
READ WRITE
| READ ONLY
}
复杂查询
视图可以理解为存储SQL语句的容器,其本身没有存储数据。(从SQL的角度来看,表和视图没有区别)
视图语法
创建视图
CREATE | REPLACE //CREATE创建视图,REPLACE替换或者创建视图
[ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}] //MYSQL优化视图的算法
[DEFINER = { user | CURRENT_USER }] //视图的创建者
[SQL SECURITY { DEFINER | INVOKER }] //指定视图查询数据时的安全验证方式
VIEW view_name [(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION] //可更新视图的限制条件
[ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]
对于MERGE,引用视图和视图定义的语句的文本被合并,以便视图定义的部分替换语句的相应部分。
对于TEMPTABLE,来自视图的结果被检索到一个临时表中,然后该临时表用于执行语句。
对于UNDEFINED,MySQL选择使用哪个算法。如果可能的话,它更喜欢MERGE而不是TEMPTABLE,因为MERGE通常效率更高,并且因为如果使用临时表,视图是不可更新的。
创建视图
CREATE VIEW shohinSum(shohin_bunrui,cnt_shohin)
AS
SELECT shohin_bunrui,COUNT(*)
FROM shohin
GROUP BY shohin_bunrui;
SELECT shohin_bunrui,cnt_shohin
FROM shohinSUM;
视图的限制
视图中不能使用ORDER BY。
以下视图不能更新:
- 视图中使用了聚合函数(SUM(), MIN(), MAX(), COUNT()等等)
- 视图中使用了DISTINCT
- 视图中使用了GROUP BY
- 视图中使用了HAVING
- 视图中使用了 UNION 或者 UNION ALL
- 视图算法设置ALGORITHM = TEMPTABLE
MYSQL的视图是否可以更新或者插入可以通过查询对应的标识位查询(https://dev.mysql.com/doc/refman/5.7/en/views-table.html)。
函数,谓词,CASE表达式
函数分类
- 算术函数 进行数值计算 https://dev.mysql.com/doc/refman/5.7/en/numeric-functions.html
- 字符串函数 https://dev.mysql.com/doc/refman/5.7/en/string-functions.html
- 日期时间函数 https://dev.mysql.com/doc/refman/5.7/en/date-and-time-functions.html
- 类型转换函数 https://dev.mysql.com/doc/refman/5.7/en/type-conversion.html
- 运算符 https://dev.mysql.com/doc/refman/5.7/en/non-typed-operators.html
- 聚合函数 https://dev.mysql.com/doc/refman/5.7/en/group-by-functions-and-modifiers.html
表联结运算
UNION(联合查询)
SELECT ...
UNION [ALL | DISTINCT] SELECT ... //ALL选项会包含重复的结果,DISTINCT是默认值,会去除重复值
[UNION [ALL | DISTINCT] SELECT ...]
第一张表的列名作为结果的列名,使用ALL不会删除重复行,DISTINCT为默认值,删除重复结果。
如果需要对单个使用ORDER BY,就要将查询子句使用括号括起来。如果需要对最终结果使用ORDER BY,也需要将每个子句括起来。(网上有些博客说UNION查询中ORDER BY只能对最终结果使用,这种说法是错误的,可以参考官方文档 https://dev.mysql.com/doc/refman/5.7/en/union.html)
(SELECT a FROM t1 WHERE a=10 AND B=1 ORDER BY a LIMIT 10)
UNION
(SELECT a FROM t2 WHERE a=11 AND B=2 ORDER BY a LIMIT 10);
(SELECT a FROM t1 WHERE a=10 AND B=1)
UNION
(SELECT a FROM t2 WHERE a=11 AND B=2)
ORDER BY a LIMIT 10;
INTERSECT 交集查询
MYSQL不支持INTERCSECT,可以使用INNER JOIN实现查询表记录的交集。
EXCEPT 表记录的减法
MYSQL不支持EXCEPT,可以使用NOT IN实现查询两表差异化的记录。
查询结果为表记录共有的部分。
联结查询(以列为单位对表进行联结)
使用联结可以实现从多张表查询记录,使用列记录进行关联。
内联结 INNER JOIN
内联结可以理解为:以表A中列作为桥梁,将表B中满足条件的列汇集到同一结果中。
基本的内联结语句:
SELECT t1.name, t2.salary
FROM employee AS t1 INNER JOIN info AS t2 ON t1.name = t2.name;
内联结和where联合使用语句(只查询符合要求的数据):
SELECT t1.name, t2.salary
FROM employee AS t1 INNER JOIN info AS t2 ON t1.name = t2.name
WHERE t1.id < 100;
外联结 OUTER JOIN
外联结即查询出主表所有符合条件的记录,不管副表中是否存在记录,副表不存在的记录列使用NULL表示。
LEFT (OUTER) JOIN和RIGHT (OUTER) JOIN中的LEFT和RIGHT表示左边或者右边的表是主表。
窗口函数
MYSQL从8.0版本开始支持窗口函数,窗口函数可以和GROUP BY分组函数进行比较以方便理解。
比如有一个分组函数:
SELECT
fiscal_year,
SUM(sale)
FROM
sales
GROUP BY
fiscal_year;
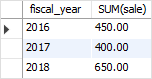
类似的窗口函数:
SELECT
fiscal_year,
sales_employee,
sale,
SUM(sale) OVER (PARTITION BY fiscal_year) total_sales
FROM
sales;
数据划分(PARTITION)
可以将一张表划分为不同的部分,比如按照DATE, TIME, 或者 DATETIME对表数据进行划分,一般用在数据量比较大的表中。
MySQL分区不能与MERGE、CSV或FEDERATED存储引擎一起使用。
PARTITION TYPE
- RANGE partitioning 基于给定的rank范围对数据进行分组
RANGE定义分组时每组值不能相接只能相邻,并且要使用LESS THAN(),最后的分区设置为MAXVALUE。
使用实例
使用整数值的列对表记录进行划分
CREATE TABLE members (
firstname VARCHAR(25) NOT NULL,
lastname VARCHAR(25) NOT NULL,
username VARCHAR(16) NOT NULL,
email VARCHAR(35),
joined DATE NOT NULL
)
PARTITION BY RANGE( YEAR(joined) ) (
PARTITION p0 VALUES LESS THAN (1960),
PARTITION p1 VALUES LESS THAN (1970),
PARTITION p2 VALUES LESS THAN (1980),
PARTITION p3 VALUES LESS THAN (1990),
PARTITION p4 VALUES LESS THAN MAXVALUE
);
使用 TIMESTAMP 类型的列对表记录进行划分
CREATE TABLE quarterly_report_status (
report_id INT NOT NULL,
report_status VARCHAR(20) NOT NULL,
report_updated TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
)
PARTITION BY RANGE ( UNIX_TIMESTAMP(report_updated) ) (
PARTITION p0 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-01-01 00:00:00') ),
PARTITION p1 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-04-01 00:00:00') ),
PARTITION p2 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-07-01 00:00:00') ),
PARTITION p3 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-10-01 00:00:00') ),
PARTITION p4 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-01-01 00:00:00') ),
PARTITION p5 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-04-01 00:00:00') ),
PARTITION p6 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-07-01 00:00:00') ),
PARTITION p7 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-10-01 00:00:00') ),
PARTITION p8 VALUES LESS THAN ( UNIX_TIMESTAMP('2010-01-01 00:00:00') ),
PARTITION p9 VALUES LESS THAN (MAXVALUE)
);
- LIST partitioning
LIST分区和TRANGE分区很相似,它们最大的区别是LIST分区是用一组值对数据进行划分,这样的划分方式更为灵活。
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY LIST(store_id) (
PARTITION pNorth VALUES IN (3,5,6,9,17),
PARTITION pEast VALUES IN (1,2,10,11,19,20),
PARTITION pWest VALUES IN (4,12,13,14,18),
PARTITION pCentral VALUES IN (7,8,15,16)
);
可以使用ALTER TABLE employees TRUNCATE PARTIT.pWest删除pWest分组中的所有数据。
LIST分区不存在RANKE分区类似的MAXVALUE,因此分组时需要将所有可能值豆包括进去,不然插入未包含数据时会报错。
- RANGE COLUMNS partitioning
RANGE partitioning的变体,支持使用多列进行分区,但是不能使用表达式。(可以使用的列包括 integer,string, DATE和DATETIME列)
CREATE TABLE table_name
PARTITIONED BY RANGE COLUMNS(column_list) (
PARTITION partition_name VALUES LESS THAN (value_list)[,
PARTITION partition_name VALUES LESS THAN (value_list)][,
...]
)
CREATE TABLE rcx (
a INT,
b INT,
c CHAR(3),
d INT
)
PARTITION BY RANGE COLUMNS(a,d,c) (
PARTITION p0 VALUES LESS THAN (5,10,'ggg'),
PARTITION p1 VALUES LESS THAN (10,20,'mmm'),
PARTITION p2 VALUES LESS THAN (15,30,'sss'),
PARTITION p3 VALUES LESS THAN (MAXVALUE,MAXVALUE,MAXVALUE)
);
比较RANGE区间的值大小可以使用sql语句
SELECT (0,25,50) < (20,20,100), (20,20,100) < (10,30,50);
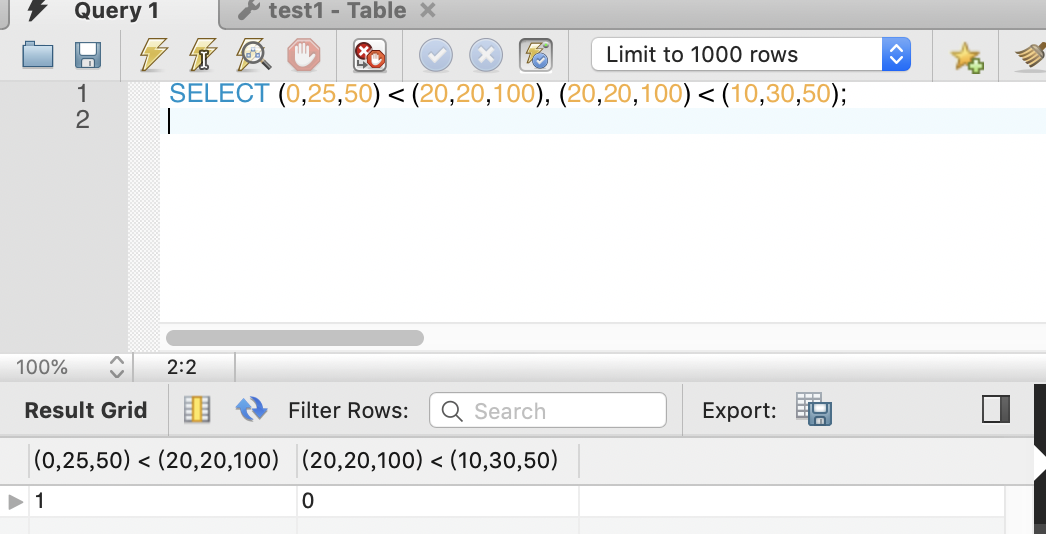
RANGE COLUMNS partitioning可以对字符串列进行分组,并且MAXVALUE值可以生效
CREATE TABLE employees_by_lname (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE COLUMNS (lname) (
PARTITION p0 VALUES LESS THAN ('g'),
PARTITION p1 VALUES LESS THAN ('m'),
PARTITION p2 VALUES LESS THAN ('t'),
PARTITION p3 VALUES LESS THAN (MAXVALUE)
);
- LIST COLUMNS partitioning
LIST partitioning的变体,支持使用多个列作为分区健,并且在integer类型之外,还支持包括string,DATE,DATETIME类型的列。
- KEY partitioning
KEY partitioning和HASH partitioning很像,不同的是由MYSQL决定使用什么算法来获得分区值:
CREATE TABLE k1 (
id INT NOT NULL PRIMARY KEY,
name VARCHAR(20)
)
PARTITION BY KEY()
PARTITIONS 2;
MYSQL优先使用主键或者联合主键作为分区的key,如果没有主键的话就使用UNIQUE KEY,但是UNIQUE KEY你许定义为NOT NULL。
- HASH partitioning
HASH分区主要用来保证数据在指定的分区内均匀分布。
使用HASH partitioning的话需要在创建表的时候进行定义,如:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY HASH( YEAR(hired) )
PARTITIONS 4;
MYSQL使用取模的方法决定数据存放在哪个分区,比如以上定义的分区中,如果hired为'2005-01-01',则分区为MOD(YEAR('2005-01-01'),4)=MOD(2005,40)=1.
LINEAR HASH Partitioning
MYSQL还支持线性哈希分区,其与HASH partitioning语句的唯一区别是添加了LINEAR关键字:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY LINEAR HASH( YEAR(hired) )
PARTITIONS 4;
线性分区使用的时候,添加,删除,合并和分割的时候速度更快,处理TB级别的数据时更加有优势,但是不能保证数据平均分布在各个分区(由分区公式决定,可参考:https://dev.mysql.com/doc/refman/5.7/en/partitioning-linear-hash.html)
- Subpartitioning
子分区或者称为混合分区(composite),是将分区表后的每一个分区继续划分。
对于使用RANGE或者LIST进行分区的表,可以再用HASH或者KEY进行分区。
以下表使用了RANGE( YEAR(purchased) )进行分区,然后定义了子分区HASH( TO_DAYS(purchased) ),分区逻辑为先根据RANGE( YEAR(purchased) )分为了三个分区,每个分区中的数据再根据HASH( TO_DAYS(purchased) )分为两个子分区(即3 * 2=6个分区)。
CREATE TABLE ts (id INT, purchased DATE)
PARTITION BY RANGE( YEAR(purchased) )
SUBPARTITION BY HASH( TO_DAYS(purchased) )
SUBPARTITIONS 2 (
PARTITION p0 VALUES LESS THAN (1990),
PARTITION p1 VALUES LESS THAN (2000),
PARTITION p2 VALUES LESS THAN MAXVALUE
);
CREATE TABLE ts (id INT, purchased DATE)
PARTITION BY RANGE(YEAR(purchased))
SUBPARTITION BY HASH(TO_DAYS(purchased))
(
PARTITION p0 VALUES LESS THAN (1990)
(SUBPARTITION s0,
SUBPARTITION s1 ),
PARTITION p1 VALUES LESS THAN (2000)
(SUBPARTITION s2,
SUBPARTITION s3 ),
PARTITION p2 VALUES LESS THAN MAXVALUE
(SUBPARTITION s4,
SUBPARTITION s5)
);
管理 PARTITION
RANGE和LIST分区
使用DROP可以直接删除旧的PARTITION(RANGE和LIST):
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY LIST(store_id) (
PARTITION pNorth VALUES IN (3,5,6,9,17),
PARTITION pEast VALUES IN (1,2,10,11,19,20),
PARTITION pWest VALUES IN (4,12,13,14,18),
PARTITION pCentral VALUES IN (7,8,15,16)
);
ALTER TABLE employees DROP PARTITION pNorth;
当删除分区的时候,分区中的数据也被删除。
删除LIST 分区后,将无法插入LIST分区中包含的列的值。
使用ALTER TABLE ... ADD PARTITION可以添加新的分区定义到RANGE和LIST分区的表中:
CREATE TABLE members (
id INT,
fname VARCHAR(25),
lname VARCHAR(25),
dob DATE
)
PARTITION BY RANGE( YEAR(dob) ) (
PARTITION p0 VALUES LESS THAN (1980),
PARTITION p1 VALUES LESS THAN (1990),
PARTITION p2 VALUES LESS THAN (2000)
);
ALTER TABLE members ADD PARTITION (PARTITION p3 VALUES LESS THAN (2010));
添加到RANGE分区的表中时,只能添加分区值大于原有值的分区。
比如以上表使用以下语句会报错:
ALTER TABLE members ADD PARTITION (PARTITION n VALUES LESS THAN (1970));
想要实现以上需求的话可以使用以下语句重构第一个分区:
ALTER TABLE members
REORGANIZE PARTITION p0 INTO (
PARTITION n0 VALUES LESS THAN (1970),
PARTITION n1 VALUES LESS THAN (1980)
);
添加新的LIST分区时,使用任何已经被使用的分区值都会报错。
HASH和KEY分区
使用ALTER TABLE ... DROP PARTITION...可以删除HASH和KEY分区,区别于RANGE和LIST分区的是可以使用ALTER TABLE ... COALESCE PARTITION将分区进行合并:
CREATE TABLE clients (
id INT,
fname VARCHAR(30),
lname VARCHAR(30),
signed DATE
)
PARTITION BY HASH( MONTH(signed) )
PARTITIONS 12;
ALTER TABLE clients COALESCE PARTITION 4; //将12个分区合并为4个