parse_url
先看介绍:
举例:
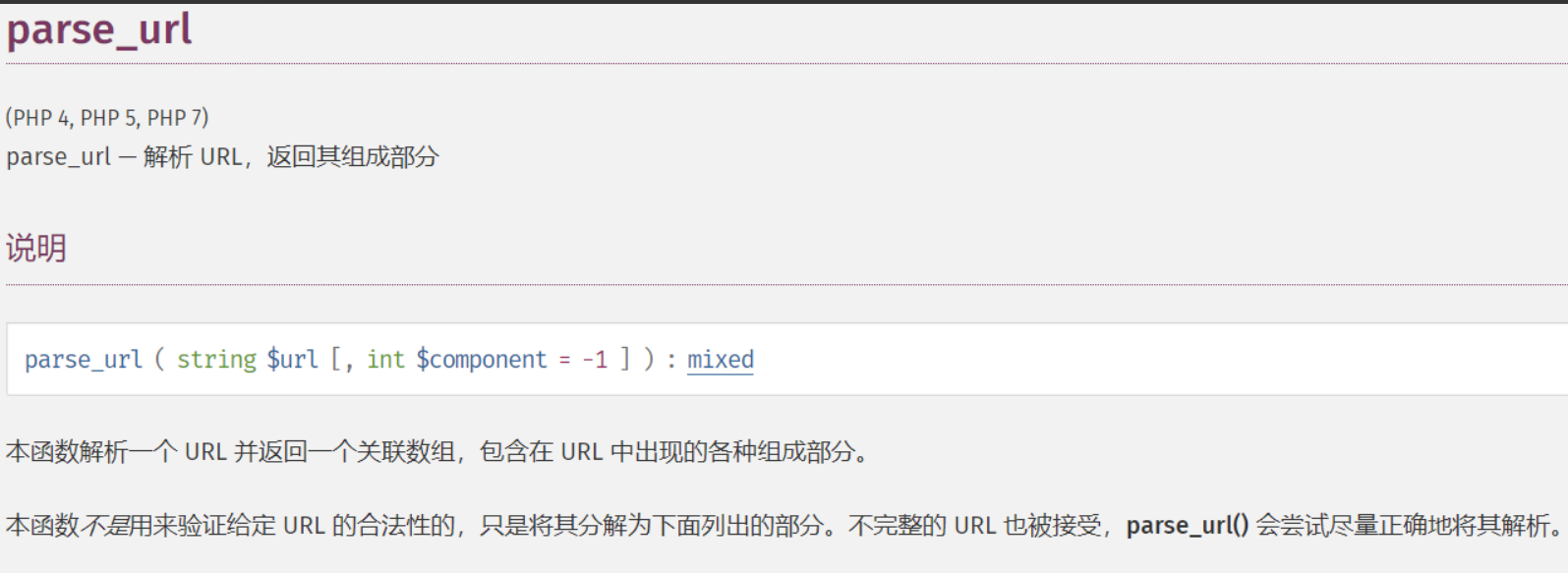
<?php $url = "https://www.example.com/haha.php?id=1"; print_r(parse_url($url));
结果:
Array ( [scheme] => https [host] => www.example.com [path] => /haha.php [query] => id=1 )
多试试几个例子,根据规律猜测函数是基于/,:,?,#这些特殊符号进行匹配切割的。若$url不符合URL规则时将返回False。所以仔细分析的话,若代码是以parse_url($url)[host]这样的形式对每个URL部分进行过滤分析的话,我们可以写入一些特殊的URL来绕过验证。
另外各种环境对URL的解析有差异,也可被我们综合利用。
示例1

分析:不会被`parse_url()`识别为路径分割符,但浏览器会自动统一URL路径中的,因此 http://www.baidu.com/index.php 与 www.baidu.comindex.php 在浏览器中打开是完全一致的。在部分场景中,可以被利用来绕过检测,如上图所示,题目本意是不允许访问flag.php,但变形后的URL通过parse_url()提取出来的path是空的,因此绕过了正则验证。
另一种相似的绕过手法:
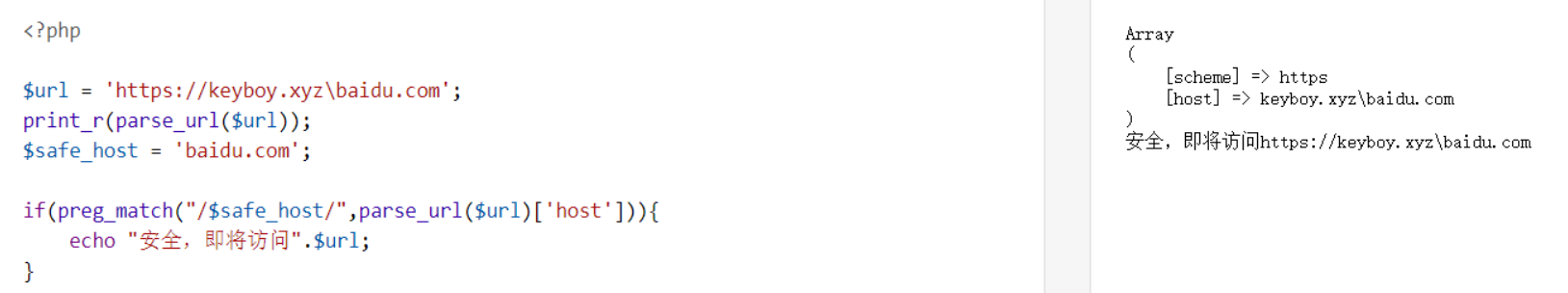
示例二
parse_url()[‘port’]解析漏洞

对于带端口的URL:https://www.domain.com:{port}{path}
port的合理取值范围为1-65535
但我测试后发现,此处的长度不能超过5,类型需要为整型。但我们知道PHP会自动为参数转型,所以我们可以尝试在此处填写满足[0-9][^0-9]{1,4}规则的字符,这样就可以把后面的非整型数值给抹去了。若是端口号后面还需要附带它参数,则必须以/,?,#来划清界限,不然会被归入parse_url()['port']的范围内,造成长度报错,返回False(对于整个parse_url()数组均为空)。在示例中,可见我们填塞进去的flag在转型过程中被“吞了”,从而绕过了正则验证。
tips:
如果访问url:http://127.0.0.1///info/parseurl.php?sql=select
这时将不能正常返回url中的参数值,遇到这样格式的连接,parse_url函数将会返回False,这种情况下可能会绕过某些waf的过滤
这个函数常常被用在如下代码中
<?php $url=parse_url($_SERVER['REQUEST_URI']); parse_str($url['query'],$query); var_dump($query); ?>
其中
REQUEST_URI 是path+query部分(不包含fragment) QUERY_STRING: 主要是key=value部分 HTTP_HOST 是 netloc+port 部分。