在介绍了最简单的查询后,接下来的查询可能会复杂很多,个人感觉有时间的查询的语句虽然很长,但是逻辑拆分开看的话,并不复杂。
在mysql中增删改查(一)中,已经介绍了条件查询,在介绍了条件查询之后,我们还可以对显示出来的结果进行设置,使它能够按照我们的意思显示出来,比如我感觉成绩太乱了,我希望结果是从高到低显示的,我感觉数据太多了,我只想看前五条等等。mysql的语句中带有排序和部分显示的方法,部分显示的方法我们通常称之为分页查询,
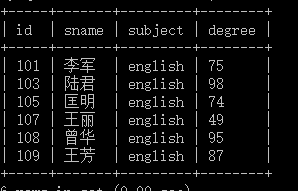
假设我们对一张成绩表进行操作,数据如下,表名为Score
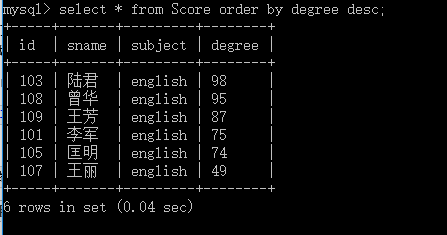
如果我们希望degree能够从高到低显示,
select * from Score order by degree desc;
如果我只想看到分数最高的三名
select * from Score order by degree desc limit 3;

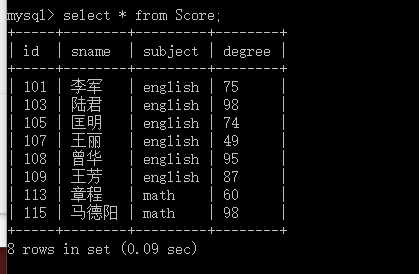
现在我们再加入两条数据
insert into Score values ("113","章程","math","60"), ("115","马德阳","math","98");
这样我们查询一下表中的信息, select * from Score;
现在我们可以看到subect有english和math两种 这样我们就可以学习分组的查询 分组查询使用group by后接分组的条件 having 后接分出来的组显示需要的条件 例如group by subjet就是以subject中的数据来分组,结果就是分成两个组, 如果这个时候我们使用 select * from Score group by subject; 由于这时数据已经被分为了两个组,所有只能显示每组的第一条数据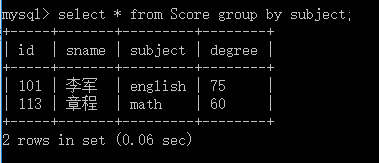
分组我们通常与聚合函数一起使用,统计每个组的条数,平均分等等 例如 select subject,count(*) from Score group by subject;
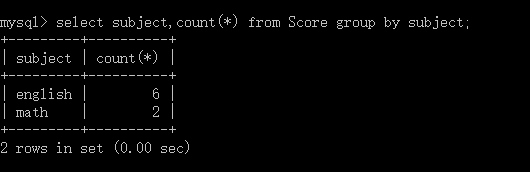
这样我们就可以看到english和math组的各自的数据条数。
有的时候我们可能会忘记我们要查的条件的具体情况比如我只记得某个是姓是曾的,具体名字忘记了,我想知道所有姓曾的,这个人时候就需要模糊查询,所谓的模糊查询,就是比如查询姓名开头为曾,或者在名字中含有曾字这样查询,我们不能使用sanme=“曾”来查询,模糊查询关键词 like。like有相似,相仿的意思,sanme like "曾%"意思就是sanme开头为曾,sanme like "%曾%"意思就是sanme字段值含有曾,与%一样居然替代功能的还有_, _符号能够确切的表示一个位置,比如“曾_”,就代表的曾某,“曾 _ _”,就代表着曾某某。
select * from Student where sname like "曾%";
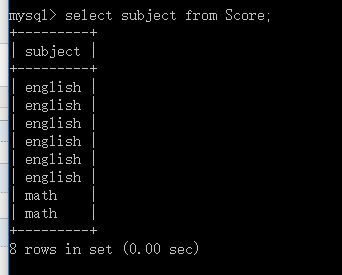
有的时候我们可能在查询的时候会查询到的返回数据中有相同信息的数据,而我们只想要不重复的显示。例如
select subject from Score;
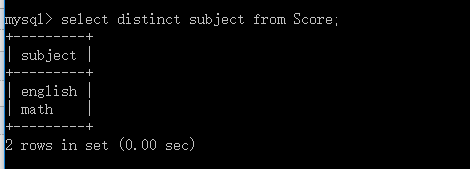
而我们有的时候不能分组,这个时候我们想要得到不重复的返回数据,在查询字段前加distinct就可以进行去重。 select distinct subject from Score;
关于单表涉及到的查询所需能想到的就这么多了,有些需要多种表的数据整合查询的属于多表查询,这里不做深入。