JVM | 内存溢出和解决方案
1. 导致内存溢出的原因
通常在三个地方会发生内存溢出:
metaspace空间内存溢出
栈内存溢出
堆内存溢出
1-1. metaspace空间内存溢出
- metaspace默认大小为
-XX:MetaspaceSize=512M
-XX:MaxMetaspaceSize=512M
1-1-1. metaspace内存溢出的原因
metaspace空间太小
没有设置metaspace参数,使用了默认的值,而默认值只有动态代理生成的类太多了,而没有正确的释放掉这些类
1-1-2. 代码模拟metaspace内存溢出
import net.sf.cglib.proxy.Enhancer;
import net.sf.cglib.proxy.MethodInterceptor;
public class MetaspaceOOMTest {
// 运行时设置jvm参数:
// -XX:MetaspaceSize=10m
// -XX:MaxMetaspaceSize = 10m
public static void main(String[] args) {
long counter = 0;
while (true) {
System.out.println("已经创建了" + ++counter + "个子类");
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(Car.class);
enhancer.setUseCache(false);
enhancer.setCallback((MethodInterceptor) (o, method, objects, methodProxy) -> {
if (method.getName().equals("run")) {
System.out.println("before car run...");
}
return methodProxy.invokeSuper(o, objects);
});
Car car = (Car) enhancer.create();
car.run();
}
}
static class Car{
public void run(){
System.out.println("car run....");
}
}
}异常信息:
可以看到Caused by: java.lang.OutOfMemoryError: Metaspace
- 使用jhat分析dump:
jhat -port 7401 -J-Xmx4G dump.hprof就可以在localhost:7401上看到了 - 使用
MAT分析dump文件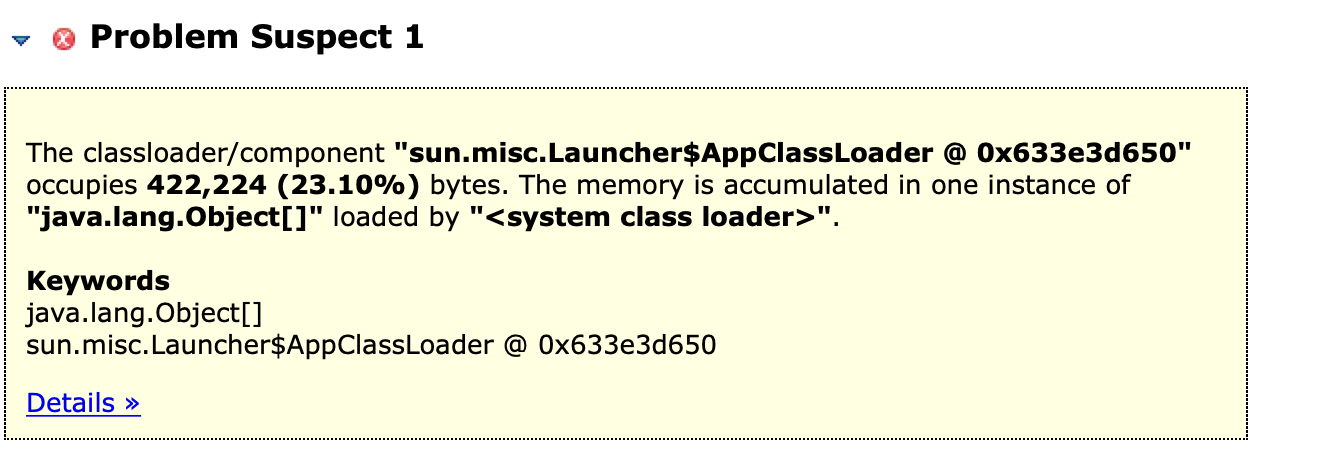

1-2. 栈内存溢出
1-2-1. 栈内存大小分配
Metaspace通常设置512M,堆内存一般分配机器内存的一半,考虑一个最基本的线上机器配置,4核8G,其中512给了metaspace,4G给了堆内存,剩余只有3G内存了,考虑到操作系统自己也会用掉一些内存,那么可以认为有一两个G的内存留给栈内存好了.通常每个线程的栈内存是1M,比如tomcat应用的话,它内部运行几百个线程是比较合理的,也就占用几百M的内存.所以JVM对机器上的内存资源的消耗为:Metaspace + 堆内存 + 几百个线程的栈内存
- 手动设置每个线程的虚拟机栈的大小,一般设置成
1M - 通常情况下,正常的方法调用,1M的栈内存足够了,但是如果在一个线程内
递归调用一个方法,就可能造成栈内存溢出了
1-2-2. 代码模拟栈内存溢出
public class StackOOMTest {
public static long counter = 0;
// 运行时设置jvm参数
// -XX:ThreadStackSize=1m
public static void main(String[] args) {
run();
}
public static void run(){
System.out.println("run "+ ++counter);
run();
}
}异常信息:
可以看到:Exception in thread "main" java.lang.StackOverflowError
- 查找栈内存溢出的办法:把系统所有异常都写入日志文件,从日志文件中就能看出栈内存异常发生的地方
1-3. 堆内存溢出
实际上最容易引发内存溢出的,就是系统创建的对象太多了,最终导致系统的内存溢出
1-3-1. 什么时候会发生堆内存的溢出
高并发请求
系统承载高并发请求,因为请求量过大,导致大量对象都是存活的,导致堆空间内存不足,引发OOM系统崩溃内存泄露
系统有内存泄露的问题,创建了很多对象,没有及时取消对它们的引用,导致触发GC还是无法回收,最终堆空间内存不足,引发OOM
1-3-2. 代码模拟堆内存溢出
public class HeapOOMTest {
// 运行时设置jvm参数
// -Xms10m -Xmx10m
public static void main(String[] args) {
long counter = 0;
List<Object> list = new ArrayList<>();
while (true) {
list.add(new Object());
System.out.println("当前创建了"+ ++counter + "个对象");
}
}
}异常信息:
可以看到:Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
- 通过MAT分析dump日志:
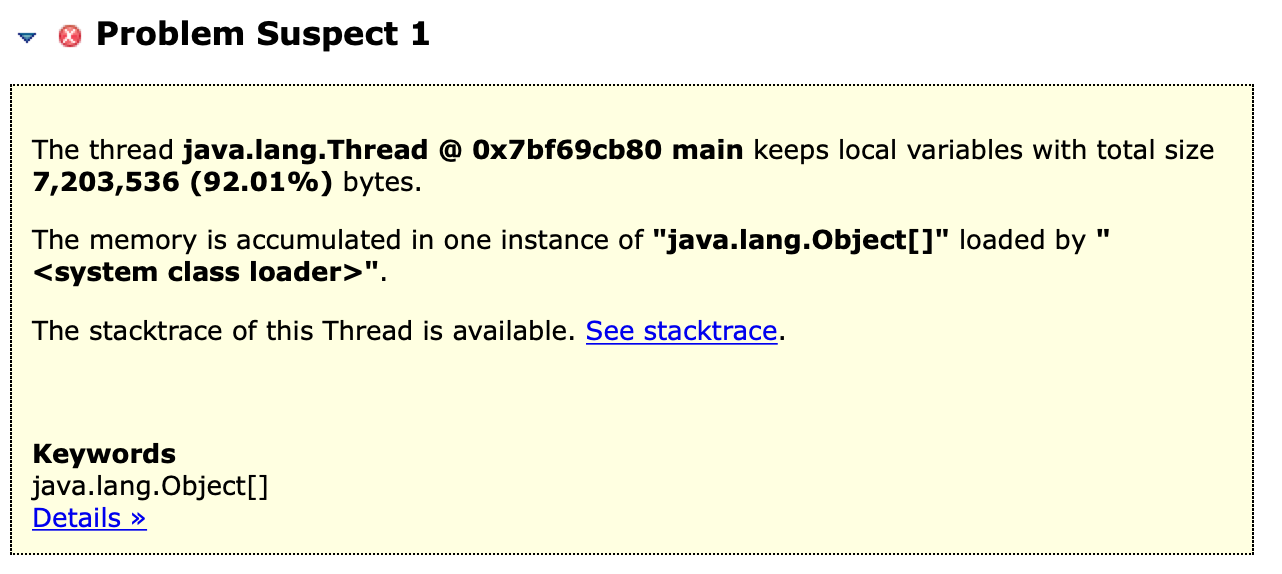

2. 生产环境真实的OOM问题
2-1. kafka宕机导致发送消息一直重试,消息数据在内存中驻留,最终导致oom
场景: 大数据量的计算系统,不停的加载数据到内存里来计算,每次少则几十万条数据,多则几百万条数据,数据计算完之后会推送到kafka,然后另一个系统从kafka里取数据.一旦kafka发生故障,系统会不断的重试,直到kafka恢复正常,数据发送成功,这样就会出现问题,重试过程中数据一直留存在内存中,无法释放,同时,系统还在不断的加载数据到内存中来处理,处理完同样也无法推送到kafka,如此往复,最终导致内存溢出,系统崩溃.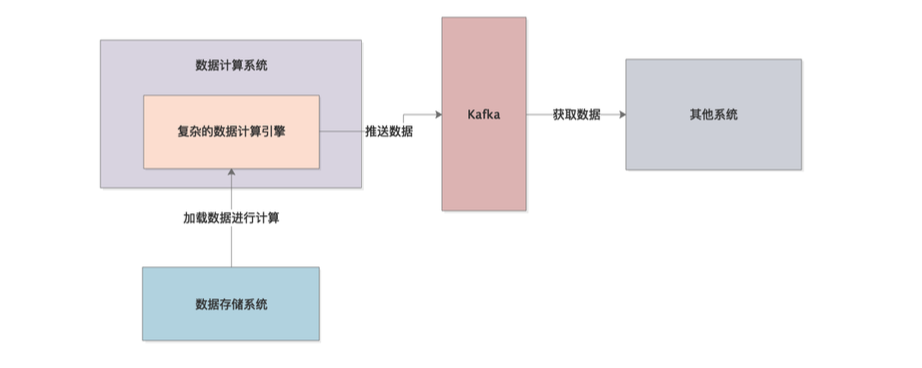
如何解决
临时取消kafka故障下的重试机制,一旦kafka故障,直接丢弃本地计算结果,允许内存中的数据被回收.
后续的话,可以继续优化,一旦kafka故障,则计算结果写本地磁盘.

2-2. 将日志写入es集群中,写日志发生异常时,也要将这个异常信息写入es集群,然后一不注意写成了递归
场景:核心系统的链路监控机制,在核心链路节点,写日志到Elasticsearch集群里去,事后基于ELK进行核心链路日志分析.同时规定如果在某个节点写日志时发生了某些异常,也需要将异常信息写入ES中,这时某位同学写出了这样的代码,在log方法中发生异常,然后捕获这个异常之后还使用log方法记录这个异常
public void log(){
try {
//将日志写入ES集群
} catch(Exception e){
log();
}
}解决办法
代码上线前要经过严格的code review+持续集成
每段代码都要经过单元测试,在单元测试+集成测试中,要求针对一些try catch中可能走到catch的分支写一些测试.
2-3. 没有缓存的动态代理
场景想要实现一个动态代理机制,在系统运行时,针对已有的某个类,生成它的动态代理类,然后对那个类的方法调用做一些额外的处理
,由于写代码的时候没有对动态生成的类做缓存,然后系统又频繁调用这个方法,导致生成了大量动态代理类,最终造成Metaspace内存溢出.
public class MetaspaceOOMTest {
public static void main(String[] args) {
MetaspaceOOMTest metaspaceOOMTest = new MetaspaceOOMTest();
for (int i = 0; i < 10000; i++) {
System.out.println(i);
metaspaceOOMTest.run();
}
}
public void run(){
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(Car.class);
//主要就是这里没有设置成使用缓存类,然后方法大量调用
enhancer.setUseCache(false);
enhancer.setCallback((MethodInterceptor) (o, method, objects, methodProxy) -> {
if (method.getName().equals("run")) {
System.out.println("before car run...");
}
return methodProxy.invokeSuper(o, objects);
});
Car car = (Car) enhancer.create();
car.run();
}
static class Car{
public void run(){
System.out.println("car run....");
}
}解决办法
针对这个方法,使用cglib生成代理对象时,尽量使用enhancer.setUseCache(true);
针对这类问题,需要代码上线之前经过压力测试,在高并发压力下系统能否正常运行支撑24小时
2-4. tomcat高并发请求导致OOM
场景
线上系统OOM,查看日志发现有Exception in thread "http-nio-8080-exec-1089" java.lang.OutOfMemoryError:Java heap space.MAT分析dump文件,发现有大量的byte数组,每个数组大约10M多点,查看这些数组被谁引用,发现是org.apache.tomcat.util.threads.TaskThread,这个类是Tomcat自己的线程类,因此可以认为是Tomcat的线程创建了大量的byte数组,占据了内存空间. 查看日志还发现系统又大量服务请求调用超时,查看发现是系统通过RPC调用其他系统的时候突然出现了请求超时,而RPC调用超时时间设置的是4秒,也就是说在一定的时间内,远程服务自己故障了,导致我们系统的RPC调用超时等待了4秒,在这4秒内,这个工作线程无法得到有效的处理,造成积压,每秒100的QPS,结果积压了4秒,就会有400个线程.
tomcat的每个线程会创建两个byte数组,用来存放request和response,这个byte数组的大小可以在tomcat配置文件中指定max-http-header-size:1000000,可见当时指定的是每个byte数组是10M,这样假设每秒100个请求,每个请求处理需要4秒,导致4秒内有400个请求同时被400个线程处理,每个线程根据配置创建2个数组,每个数组是10M,所以总共占用就是400*2*10=8000M差不多就是8G的内存解决办法- 主要原因就是RPC的超时等待时间过长,因此将
超时等待时间改为1秒,这样每秒100QPS,也就200个数组,占据2G内存,不会吧内存塞满 - tomcat的
max-http-header-size参数可以适当调小一些,这样Tomcat工作线程为请求创建的数组占用的内存空间就不会太大了
3. OOM异常监控和报警
3-1. 一个监控体系需要关注哪些东西
cpu的负载
要关注一下cpu的使用率,如果长期使用率超过90%,就需要预警了.内存的使用率
如果机器内存长期使用率超过一定阈值,比如长期使用率超过90%,那肯定有问题,随时机器内存可能就不够了.Full GC的频率
假设5分钟内发生了10次Full GC,那一定是频繁Full GC了.磁盘IO负载
要关注一下本地磁盘的使用量和剩余空间,因为假如系统因为一些bug,可能会一直往本地磁盘写东西,万一把磁盘写满了就会导致系统无法运行.网络负载
就是通过网络IO读写了多少数据,一些耗时等等.系统业务指标的监控
比如可以在系统每次创建一个订单就上报一次监控,然后监控系统会收集你1分钟内的订单数量,然后可以设定一个阈值,比如1分钟内的订单数量超过了100就报警.因为可能订单过多涉及到一些刷单之类的行为
3-2. 在JVM内存溢出时自动dump内存快照
- 配置jvm启动参数
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/usr/local/app/oom - 使用
MAT工具分析dump文件
3-3. JVM参数通用模板
-Xms4096M -Xmx4096M
-Xmn3072M -Xss1M
-XX:MetaspaceSize=256M
-XX:MaxMetaspaceSize=256M
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFaction=92
-XX:+UseCMSCompactAtFullCollection
-XX:CMSFullGCsBeforeCompaction=0
-XX:+CMSParallelInitialMarkEnabled
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/usr/local/app/oom4. 如何分析dump文件
4-1. MAT工具

4-1-1. Histogram查看内存中各对象数量
将dump文件导入MAT中,点击Histogram查看占用内存最多的对象有哪些
4-1-2. Dominator_tree查看JVM中各线程创建对象的数量
