每次经历数据库性能调优,都是对性能优化的再次认识、对自己知识不足的有力验证,只有不断总结、学习才能少走弯路。
内容摘要:
一、性能问题描述
应用端反应系统查询缓慢,长时间出不来结果。SQLServer数据库服务器吞吐量不足,CPU资源不足,经常飙到100%.......
二、监测分析
收集性能数据采用二种方式:连续一段时间收集和高峰期实时收集
连续一天收集性能指标(以下简称“连续监测”)
目的: 通过此方式得到CPU/内存/磁盘/SQLServer总体情况,宏观上分析当前服务器的主要的性能瓶颈。
工具: 性能计数器 Perfmon+PAL日志分析器(工具使用方法请参考另外一篇博文)
配置:
-
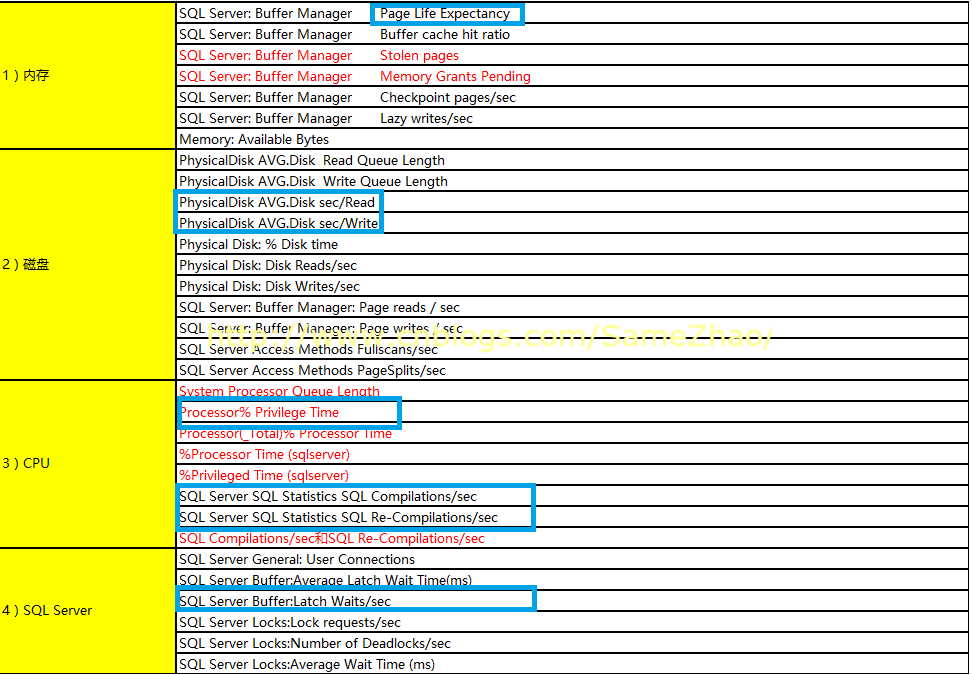
Perfmon配置主要性能计数器内容具体如下表
-
Perfmon收集的时间间隔:15秒 (不宜过短,否则会对服务器性能造成额外压力)
-
收集时间: 8:00~20:00业务时间,收集一天
分析监测结果
收集完成后,通过PAL(一款日志分析工具,可见一篇博文介绍)工具自动分析出结果,显示主要性能问题:
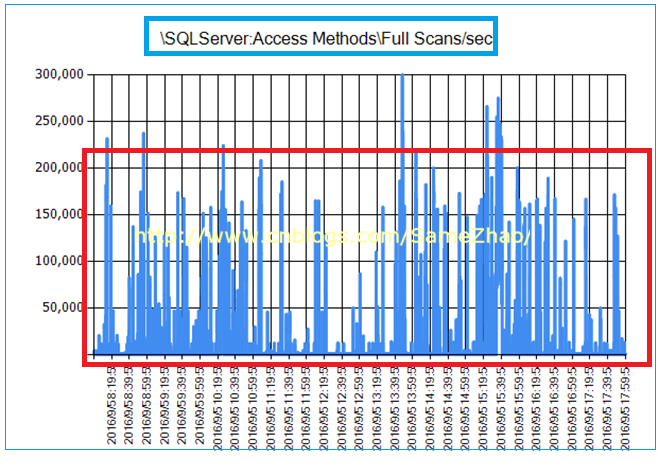
业务高峰期CPU接近100%,并伴随较多的Latch(闩锁)等待,查询时有大量的扫表操作。这些只是宏观上得到的“现象级“的性能问题表现,并不能一定说明是CPU资源不够导致的,需要进一步找证据分析。
PAL分析得出几个突出性能问题
1. 业务高峰期CPU接近瓶颈:CPU平均在60%左右,高峰在80%以上,极端达到100%

2. Latch等待一直持续存在,平均在>500。Non-Page Latch等待严重


4. SQL编译和反编译参数高于正常

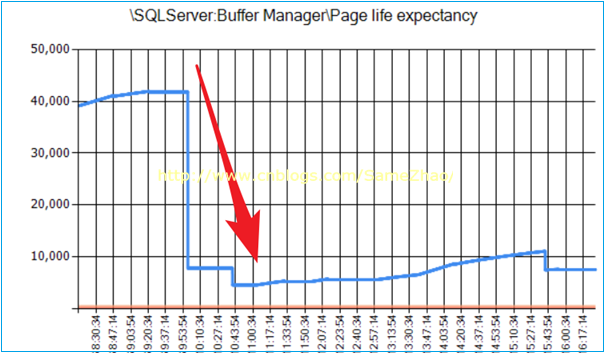
5.PLE即页在内存中的生命周期,其数量从某个时间点出现断崖式下降
其数量从早上某个时间点下降后直持续到下午4点,说明这段时间内存中页面切换比较频繁,出现从磁盘读取大量页数据到内存,很可能是大面积扫表导致。
实时监测性能指标
目的: 根据“连续监测“已知的业务高峰期PeakTime主要发生时段,接下来通过实时监测重点关注这段时间各项指标,进一步确认问题。
工具: SQLCheck(工具使用请见另外一篇 博文介绍)
配置: 客户端连接到SQLCheck配置
小贴士:建议不要在当前服务器运行,可选择另外一台机器运行SQLCheck
分析监测结果
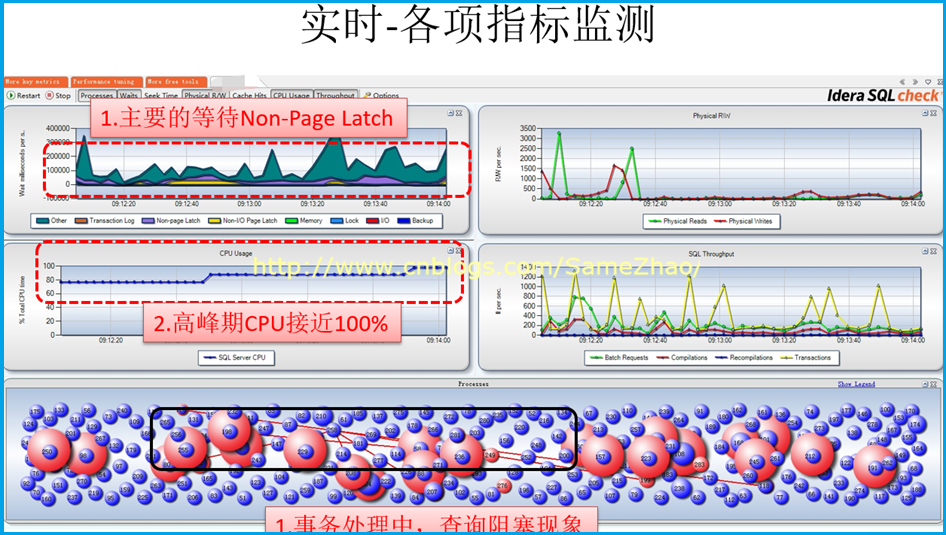
实时监测显示Non-Page Latch等待严重,这点与上面“连续监测”得到结果一直
Session之间阻塞现象时常发生,经分析是大的结果集查询阻塞了别的查询、更新、删除操作导致
详细分析
数据库存存在大量表扫描操作,导致缓存中数据不能满足查询,需要从磁盘中读取数据,产生IO等待导致阻塞。
1. Non-Page Latch等待时间长
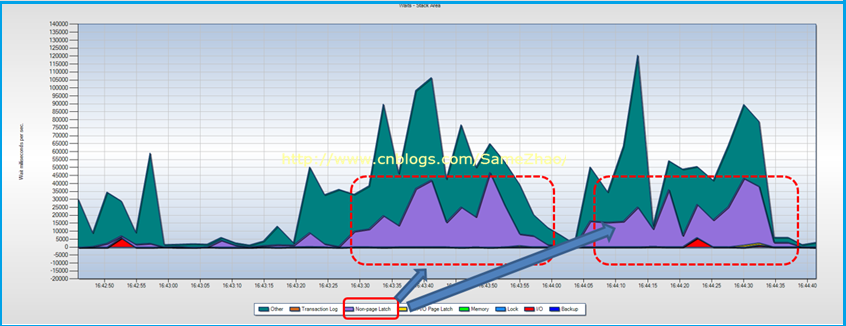
2. 当 Non-Page Latch等待发生时候,实时监测显示正在执行大的查询操作

3. 伴有session之间阻塞现象,在大的查询时发生阻塞现象,CPU也随之飙到95%以上
解决方案
找到问题语句,创建基于条件的索引来减少扫描,并更新统计信息。
上面方法还无法解决,考虑将受影响的数据转移到更快的IO子系统,考虑增加内存。
三、等待类型分析
通过等待类型,换个角度进一步分析到底时哪些资源出现瓶颈
工具: DMV/DMO
操作:
1. 先清除历史等待数据
选择早上8点左右执行下面语句
DBCC SQLPERF('sys.dm_os_wait_stats', CLEAR);
2. 晚上8点左右执行,执行下面语句收集Top 10的等待类型信息统计。


WITH [Waits] AS ( SELECT [wait_type] , [wait_time_ms] / 1000.0 AS [WaitS] , ( [wait_time_ms] - [signal_wait_time_ms] ) / 1000.0 AS [ResourceS] , [signal_wait_time_ms] / 1000.0 AS [SignalS] , [waiting_tasks_count] AS [WaitCount] , 100.0 * [wait_time_ms] / SUM([wait_time_ms]) OVER ( ) AS [Percentage] , ROW_NUMBER() OVER ( ORDER BY [wait_time_ms] DESC ) AS [RowNum] FROM sys.dm_os_wait_stats WHERE [wait_type] NOT IN ( N'CLR_SEMAPHORE', N'LAZYWRITER_SLEEP', N'RESOURCE_QUEUE', N'SQLTRACE_BUFFER_FLUSH', N'SLEEP_TASK', N'SLEEP_SYSTEMTASK', N'WAITFOR', N'HADR_FILESTREAM_IOMGR_IOCOMPLETION', N'CHECKPOINT_QUEUE', N'REQUEST_FOR_DEADLOCK_SEARCH', N'XE_TIMER_EVENT', N'XE_DISPATCHER_JOIN', N'LOGMGR_QUEUE', N'FT_IFTS_SCHEDULER_IDLE_WAIT', N'BROKER_TASK_STOP', N'CLR_MANUAL_EVENT', N'CLR_AUTO_EVENT', N'DISPATCHER_QUEUE_SEMAPHORE', N'TRACEWRITE', N'XE_DISPATCHER_WAIT', N'BROKER_TO_FLUSH', N'BROKER_EVENTHANDLER', N'FT_IFTSHC_MUTEX', N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP', N'DIRTY_PAGE_POLL', N'SP_SERVER_DIAGNOSTICS_SLEEP' ) ) SELECT [W1].[wait_type] AS [WaitType] , CAST ([W1].[WaitS] AS DECIMAL(14, 2)) AS [Wait_S] , CAST ([W1].[ResourceS] AS DECIMAL(14, 2)) AS [Resource_S] , CAST ([W1].[SignalS] AS DECIMAL(14, 2)) AS [Signal_S] , [W1].[WaitCount] AS [WaitCount] , CAST ([W1].[Percentage] AS DECIMAL(4, 2)) AS [Percentage] , CAST (( [W1].[WaitS] / [W1].[WaitCount] ) AS DECIMAL(14, 4)) AS [AvgWait_S] , CAST (( [W1].[ResourceS] / [W1].[WaitCount] ) AS DECIMAL(14, 4)) AS [AvgRes_S] , CAST (( [W1].[SignalS] / [W1].[WaitCount] ) AS DECIMAL(14, 4)) AS [AvgSig_S] FROM [Waits] AS [W1] INNER JOIN [Waits] AS [W2] ON [W2].[RowNum] <= [W1].[RowNum] GROUP BY [W1].[RowNum] , [W1].[wait_type] , [W1].[WaitS] , [W1].[ResourceS] , [W1].[SignalS] , [W1].[WaitCount] , [W1].[Percentage] HAVING SUM([W2].[Percentage]) - [W1].[Percentage] <95; -- percentage threshold GO
3.提取信息

查询结果得出排名:
1:CXPACKET
2:LATCH_X
3:IO_COMPITION
4:SOS_SCHEDULER_YIELD
5: ASYNC_NETWORK_IO
6. PAGELATCH_XX
7/8.PAGEIOLATCH_XX
跟主要资源相关的等待方阵如下:
CPU相关:CXPACKET 和SOS_SCHEDULER_YIELD
IO相关: PAGEIOLATCH_XXIO_COMPLETION
Memory相关: PAGELATCH_XX、LATCH_X
进一步分析前几名等待类型
当前排前三位:CXPACKET、LATCH_EX、IO_COMPLETION等待,开始一个个分析其产生等待背后原因
小贴士:关于等待类型的知识学习,可参考Paul Randal的系列文章。
CXPACKET等待分析
CXPACKET等待排第1位, SOS_SCHEDULER_YIELD排在4位,伴有第7、8位的PAGEIOLATCH_XX等待。发生了并行操作worker被阻塞
说明:
1. 存在大范围的表Scan
2. 某些并行线程执行时间过长,这个要将PAGEIOLATCH_XX和非页闩锁Latch_XX的ACCESS_METHODS_DATASET_PARENT Latch结合起来看,后面会给到相关信息
3. 执行计划不合理的可能
分析:
1. 首先看一下花在执行等待和资源等待的时间
2. PAGEIOLATCH_XX是否存在,PAGEIOLATCH_SH等待,这意味着大范围SCAN
3. 是否同时有ACCESS_METHODS_DATASET_PARENT Latch或ACCESS_METHODS_SCAN_RANGE_GENERATOR LATCH等待
4. 执行计划是否合理
信提取息:
获取CPU的执行等待和资源等待的时间所占比重
执行下面语句:
--CPU Wait Queue (threshold:<=6) select scheduler_id,idle_switches_count,context_switches_count,current_tasks_count, active_workers_count from sys.dm_os_schedulers where scheduler_id<255
SELECT sum(signal_wait_time_ms) as total_signal_wait_time_ms, sum(wait_time_ms-signal_wait_time_ms) as resource_wait_time_percent, sum(signal_wait_time_ms)*1.0/sum(wait_time_ms)*100 as signal_wait_percent, sum(wait_time_ms-signal_wait_time_ms)*1.0/sum(wait_time_ms)*100 as resource_wait_percent FROM SYS.dm_os_wait_stats
![]()
结论:从下表收集到信息CPU主要花在资源等待上,而执行时候等待占比率小,所以不能武断认为CPU资源不够。
造成原因:
缺少聚集索引、不准确的执行计划、并行线程执行时间过长、是否存在隐式转换、TempDB资源争用
解决方案:
主要从如何减少CPU花在资源等待的时间
1. 设置查询的MAXDOP,根据CPU核数设置合适的值(解决多CPU并行处理出现水桶短板现象)
2. 检查”cost threshold parallelism”的值,设置为更合理的值
3. 减少全表扫描:建立合适的聚集索引、非聚集索引,减少全表扫描
4. 不精确的执行计划:选用更优化执行计划
5. 统计信息:确保统计信息是最新的
6. 建议添加多个Temp DB 数据文件,减少Latch争用,最佳实践:>8核数,建议添加4个或8个等大小的数据文件
LATCH_EX等待分析
LATCH_EX等待排第2位。
说明:
有大量的非页闩锁等待,首先确认是哪一个闩锁等待时间过长,是否同时发生CXPACKET等待类型。
分析:
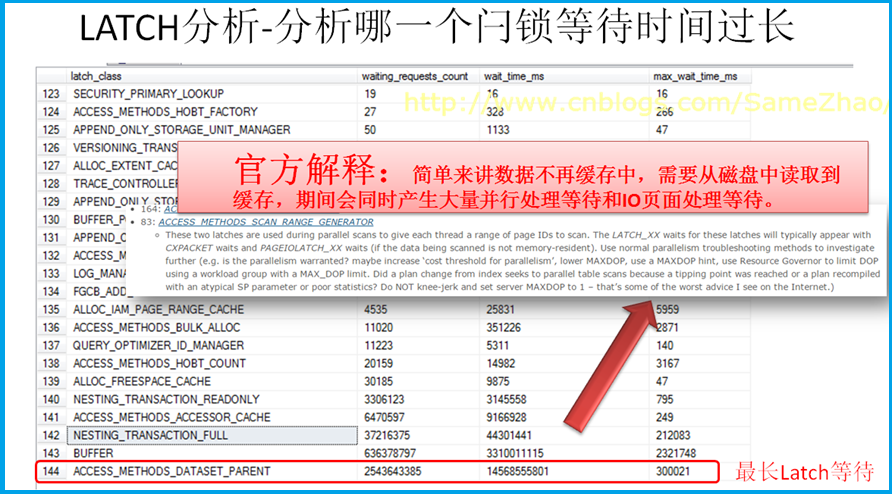
查询所有闩锁等待信息,发现ACCESS_METHODS_DATASET_PARENT等待最长,查询相关资料显示因从磁盘->IO读取大量的数据到缓存,结合与之前Perfmon结果做综合分析判断,判断存在大量扫描。
运行脚本
SELECT * FROM sys.dm_os_latch_stats
信提取息:
造成原因:
有大量的并行处理等待、IO页面处理等待,这进一步推定存在大范围的扫描表操作。
与开发人员确认存储过程中使用大量的临时表,并监测到业务中处理用频繁使用临时表、标量值函数,不断创建用户对象等,TEMPDB 处理内存相关PFSGAMSGAM时,有很多内部资源申请征用的Latch等待现象。
解决方案:
1. 优化TempDB
2. 创建非聚集索引来减少扫描
3. 更新统计信息
4. 在上面方法仍然无法解决,可将受影响的数据转移到更快的IO子系统,考虑增加内存
IO_COMPLETION等待分析
现象:
IO_COMPLETION等待排第3位
说明:
IO延迟问题,数据从磁盘到内存等待时间长
分析:
从数据库的文件读写效率分析哪个比较慢,再与“CXPACKET等待分析”的结果合起来分析。
Temp IO读/写资源效率
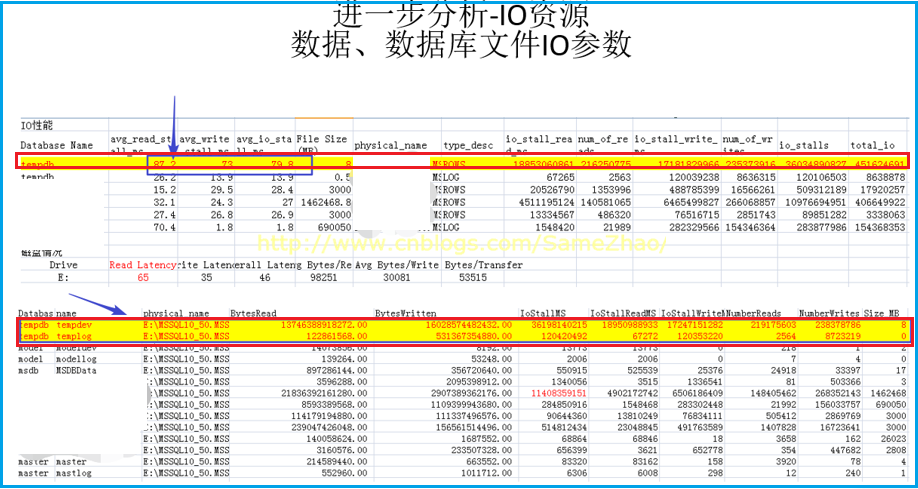
1. TempDB的数据文件的平均IO在80左右,这个超出一般值,TempDB存在严重的延迟。
2. TempDB所在磁盘的Read latency为65,也比一般值偏高。
运行脚本:
1 --数据库文件读写IO性能 2 SELECT DB_NAME(fs.database_id) AS [Database Name], CAST(fs.io_stall_read_ms/(1.0 + fs.num_of_reads) AS NUMERIC(10,1)) AS [avg_read_stall_ms], 3 CAST(fs.io_stall_write_ms/(1.0 + fs.num_of_writes) AS NUMERIC(10,1)) AS [avg_write_stall_ms], 4 CAST((fs.io_stall_read_ms + fs.io_stall_write_ms)/(1.0 + fs.num_of_reads + fs.num_of_writes) AS NUMERIC(10,1)) AS [avg_io_stall_ms], 5 CONVERT(DECIMAL(18,2), mf.size/128.0) AS [File Size (MB)], mf.physical_name, mf.type_desc, fs.io_stall_read_ms, fs.num_of_reads, 6 fs.io_stall_write_ms, fs.num_of_writes, fs.io_stall_read_ms + fs.io_stall_write_ms AS [io_stalls], fs.num_of_reads + fs.num_of_writes AS [total_io] 7 FROM sys.dm_io_virtual_file_stats(null,null) AS fs 8 INNER JOIN sys.master_files AS mf WITH (NOLOCK) 9 ON fs.database_id = mf.database_id 10 AND fs.[file_id] = mf.[file_id] 11 ORDER BY avg_io_stall_ms DESC OPTION (RECOMPILE); 12 13 --驱动磁盘-IO文件情况 14 SELECT [Drive], 15 CASE 16 WHEN num_of_reads = 0 THEN 0 17 ELSE (io_stall_read_ms/num_of_reads) 18 END AS [Read Latency], 19 CASE 20 WHEN io_stall_write_ms = 0 THEN 0 21 ELSE (io_stall_write_ms/num_of_writes) 22 END AS [Write Latency], 23 CASE 24 WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0 25 ELSE (io_stall/(num_of_reads + num_of_writes)) 26 END AS [Overall Latency], 27 CASE 28 WHEN num_of_reads = 0 THEN 0 29 ELSE (num_of_bytes_read/num_of_reads) 30 END AS [Avg Bytes/Read], 31 CASE 32 WHEN io_stall_write_ms = 0 THEN 0 33 ELSE (num_of_bytes_written/num_of_writes) 34 END AS [Avg Bytes/Write], 35 CASE 36 WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0 37 ELSE ((num_of_bytes_read + num_of_bytes_written)/(num_of_reads + num_of_writes)) 38 END AS [Avg Bytes/Transfer] 39 FROM (SELECT LEFT(mf.physical_name, 2) AS Drive, SUM(num_of_reads) AS num_of_reads, 40 SUM(io_stall_read_ms) AS io_stall_read_ms, SUM(num_of_writes) AS num_of_writes, 41 SUM(io_stall_write_ms) AS io_stall_write_ms, SUM(num_of_bytes_read) AS num_of_bytes_read, 42 SUM(num_of_bytes_written) AS num_of_bytes_written, SUM(io_stall) AS io_stall 43 FROM sys.dm_io_virtual_file_stats(NULL, NULL) AS vfs 44 INNER JOIN sys.master_files AS mf WITH (NOLOCK) 45 ON vfs.database_id = mf.database_id AND vfs.file_id = mf.file_id 46 GROUP BY LEFT(mf.physical_name, 2)) AS tab 47 ORDER BY [Overall Latency] OPTION (RECOMPILE);
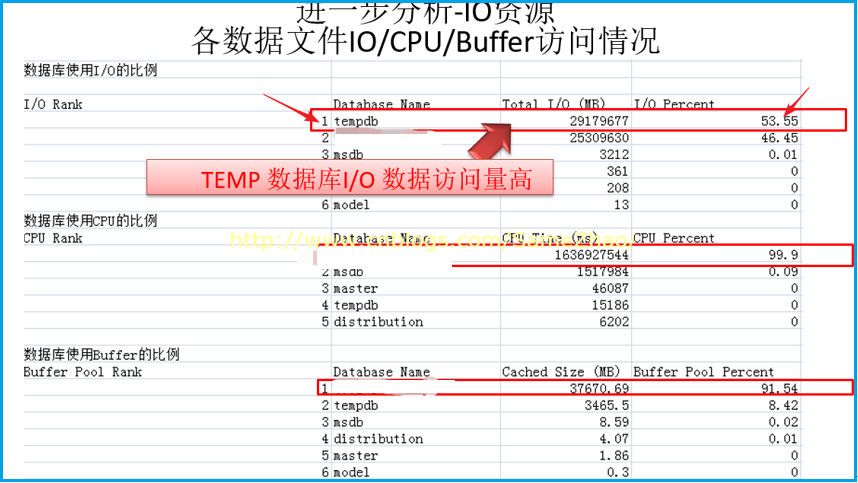
信提取息:
各数据文件IO/CPU/Buffer访问情况,Temp DB的IO Rank达到53%以上
解决方案:
添加多个Temp DB 数据文件,减少Latch争用。最佳实践:>8核数,建议添加4个或8个等大小的数据文件。
其他等待
分析:
通过等待类型发现与IO相关 的PAGEIOLATCH_XX 值非常高,数据库存存在大量表扫描操作,导致缓存中数据不能满足查询,需要从磁盘中读取数据,产生IO等待。
解决方案:
创建合理非聚集索引来减少扫描,更新统计信息
上面方法还无法解决,考虑将受影响的数据转移到更快的IO子系统,考虑增加内存。
四、优化方案
依据以上监测和分析结果,从“优化顺序”和“实施原则”开始实质性的优化。
优化顺序
1. 从数据库配置优化
理由:代价最小,根据监测分析结果,通过修改配置可提升空间不小。
2. 索引优化
理由:索引不会动数据库表等与业务紧密的结构,业务层面不会有风险。
步骤:考虑到库中打表(超过100G),在索引优化也要分步进行。 优化索引步骤:无用索引->重复索引->丢失索引添加->聚集索引->索引碎片整理。
3. 查询优化
理由:语句优化需要结合业务,需要和开发人员紧密沟通,最终选择优化语句的方案
步骤:DBA抓取执行时间、使用CPU、IO、内存最多的TOP SQL语句/存储过程,交由开发人员并协助找出可优化的方法,如加索引、语句写法等。
实施原则
整个诊断和优化方案首先在测试环境中进行测试,将在测试环境中测试通过并确认的逐步实施到正式环境。
数据库配置优化
1. 当前数据库服务器有超过24个核数, 当前MAXDOP为0,配置不合理,导致调度并发处理时出现较大并行等待现象(水桶短板原理)
优化建议:建议修改MAXDOP 值,最佳实践>8核的,先设置为4
2. 当前COST THRESHOLD FOR PARALLELISM值默认5秒
优化建议:建议修改 COST THRESHOLD FOR PARALLELISM值,超过15秒允许并行处理
3. 监测到业务中处理用频繁使用临时表、标量值函数,不断创建用户对象等,TEMPDB 处理内存相关PFSGAMSGAM时,有很多的Latch等待现象,给性能造成影响
优化建议:建议添加多个Temp DB 数据文件,减少Latch争用。最佳实践:>8核数,建议添加4个或8个等大小的数据文件。
4. 启用optimize for ad hoc workloads
5. Ad Hoc Distributed Queries开启即席查询优化
索引优化
1. 无用索引优化
目前库中存在大量无用索引,可通过脚本找出无用的索引并删除,减少系统对索引维护成本,提高更新性能。另外,根据读比率低于1%的表的索引,可结合业务最终确认是否删除索引。
详细列表请参考:性能调优数据收集_索引.xlsx-无用索引
无用索引,参考执行语句:
SELECT OBJECT_NAME(i.object_id) AS table_name , COALESCE(i.name, SPACE(0)) AS index_name , ps.partition_number , ps.row_count , CAST(( ps.reserved_page_count * 8 ) / 1024. AS DECIMAL(12, 2)) AS size_in_mb , COALESCE(ius.user_seeks, 0) AS user_seeks , COALESCE(ius.user_scans, 0) AS user_scans , COALESCE(ius.user_lookups, 0) AS user_lookups , i.type_desc FROM sys.all_objects t INNER JOIN sys.indexes i ON t.object_id = i.object_id INNER JOIN sys.dm_db_partition_stats ps ON i.object_id = ps.object_id AND i.index_id = ps.index_id LEFT OUTER JOIN sys.dm_db_index_usage_stats ius ON ius.database_id = DB_ID() AND i.object_id = ius.object_id AND i.index_id = ius.index_id WHERE i.type_desc NOT IN ( 'HEAP', 'CLUSTERED' ) AND i.is_unique = 0 AND i.is_primary_key = 0 AND i.is_unique_constraint = 0 AND COALESCE(ius.user_seeks, 0) <= 0 AND COALESCE(ius.user_scans, 0) <= 0 AND COALESCE(ius.user_lookups, 0) <= 0 ORDER BY OBJECT_NAME(i.object_id) , i.name --1. Finding unused non-clustered indexes. SELECT OBJECT_SCHEMA_NAME(i.object_id) AS SchemaName , OBJECT_NAME(i.object_id) AS TableName , i.name , ius.user_seeks , ius.user_scans , ius.user_lookups , ius.user_updates FROM sys.dm_db_index_usage_stats AS ius JOIN sys.indexes AS i ON i.index_id = ius.index_id AND i.object_id = ius.object_id WHERE ius.database_id = DB_ID() AND i.is_unique_constraint = 0 -- no unique indexes AND i.is_primary_key = 0 AND i.is_disabled = 0 AND i.type > 1 -- don't consider heaps/clustered index AND ( ( ius.user_seeks + ius.user_scans + ius.user_lookups ) < ius.user_updates OR ( ius.user_seeks = 0 AND ius.user_scans = 0 ) )
表的读写比,参考执行语句
1 DECLARE @dbid int 2 SELECT @dbid = db_id() 3 SELECT TableName = object_name(s.object_id), 4 Reads = SUM(user_seeks + user_scans + user_lookups), Writes = SUM(user_updates),CONVERT(BIGINT,SUM(user_seeks + user_scans + user_lookups))*100/( SUM(user_updates)+SUM(user_seeks + user_scans + user_lookups)) 5 FROM sys.dm_db_index_usage_stats AS s 6 INNER JOIN sys.indexes AS i 7 ON s.object_id = i.object_id 8 AND i.index_id = s.index_id 9 WHERE objectproperty(s.object_id,'IsUserTable') = 1 10 AND s.database_id = @dbid 11 GROUP BY object_name(s.object_id) 12 ORDER BY writes DESC
2. 移除、合并重复索引
目前系统中很多索引重复,对该类索引进行合并,减少索引的维护成本,从而提升更新性能。
重复索引,参考执行语句:
1 WITH MyDuplicate AS (SELECT 2 Sch.[name] AS SchemaName, 3 Obj.[name] AS TableName, 4 Idx.[name] AS IndexName, 5 INDEX_Col(Sch.[name] + '.' + Obj.[name], Idx.index_id, 1) AS Col1, 6 INDEX_Col(Sch.[name] + '.' + Obj.[name], Idx.index_id, 2) AS Col2, 7 INDEX_Col(Sch.[name] + '.' + Obj.[name], Idx.index_id, 3) AS Col3, 8 INDEX_Col(Sch.[name] + '.' + Obj.[name], Idx.index_id, 4) AS Col4, 9 INDEX_Col(Sch.[name] + '.' + Obj.[name], Idx.index_id, 5) AS Col5, 10 INDEX_Col(Sch.[name] + '.' + Obj.[name], Idx.index_id, 6) AS Col6, 11 INDEX_Col(Sch.[name] + '.' + Obj.[name], Idx.index_id, 7) AS Col7, 12 INDEX_Col(Sch.[name] + '.' + Obj.[name], Idx.index_id, 8) AS Col8, 13 INDEX_Col(Sch.[name] + '.' + Obj.[name], Idx.index_id, 9) AS Col9, 14 INDEX_Col(Sch.[name] + '.' + Obj.[name], Idx.index_id, 10) AS Col10, 15 INDEX_Col(Sch.[name] + '.' + Obj.[name], Idx.index_id, 11) AS Col11, 16 INDEX_Col(Sch.[name] + '.' + Obj.[name], Idx.index_id, 12) AS Col12, 17 INDEX_Col(Sch.[name] + '.' + Obj.[name], Idx.index_id, 13) AS Col13, 18 INDEX_Col(Sch.[name] + '.' + Obj.[name], Idx.index_id, 14) AS Col14, 19 INDEX_Col(Sch.[name] + '.' + Obj.[name], Idx.index_id, 15) AS Col15, 20 INDEX_Col(Sch.[name] + '.' + Obj.[name], Idx.index_id, 16) AS Col16 21 FROM sys.indexes Idx 22 INNER JOIN sys.objects Obj ON Idx.[object_id] = Obj.[object_id] 23 INNER JOIN sys.schemas Sch ON Sch.[schema_id] = Obj.[schema_id] 24 WHERE index_id > 0 AND Obj.[name]='DOC_INVPLU') 25 SELECT MD1.SchemaName, MD1.TableName, MD1.IndexName, 26 MD2.IndexName AS OverLappingIndex, 27 MD1.Col1, MD1.Col2, MD1.Col3, MD1.Col4, 28 MD1.Col5, MD1.Col6, MD1.Col7, MD1.Col8, 29 MD1.Col9, MD1.Col10, MD1.Col11, MD1.Col12, 30 MD1.Col13, MD1.Col14, MD1.Col15, MD1.Col16 31 FROM MyDuplicate MD1 32 INNER JOIN MyDuplicate MD2 ON MD1.tablename = MD2.tablename 33 AND MD1.indexname <> MD2.indexname 34 AND MD1.Col1 = MD2.Col1 35 AND (MD1.Col2 IS NULL OR MD2.Col2 IS NULL OR MD1.Col2 = MD2.Col2) 36 AND (MD1.Col3 IS NULL OR MD2.Col3 IS NULL OR MD1.Col3 = MD2.Col3) 37 AND (MD1.Col4 IS NULL OR MD2.Col4 IS NULL OR MD1.Col4 = MD2.Col4) 38 AND (MD1.Col5 IS NULL OR MD2.Col5 IS NULL OR MD1.Col5 = MD2.Col5) 39 AND (MD1.Col6 IS NULL OR MD2.Col6 IS NULL OR MD1.Col6 = MD2.Col6) 40 AND (MD1.Col7 IS NULL OR MD2.Col7 IS NULL OR MD1.Col7 = MD2.Col7) 41 AND (MD1.Col8 IS NULL OR MD2.Col8 IS NULL OR MD1.Col8 = MD2.Col8) 42 AND (MD1.Col9 IS NULL OR MD2.Col9 IS NULL OR MD1.Col9 = MD2.Col9) 43 AND (MD1.Col10 IS NULL OR MD2.Col10 IS NULL OR MD1.Col10 = MD2.Col10) 44 AND (MD1.Col11 IS NULL OR MD2.Col11 IS NULL OR MD1.Col11 = MD2.Col11) 45 AND (MD1.Col12 IS NULL OR MD2.Col12 IS NULL OR MD1.Col12 = MD2.Col12) 46 AND (MD1.Col13 IS NULL OR MD2.Col13 IS NULL OR MD1.Col13 = MD2.Col13) 47 AND (MD1.Col14 IS NULL OR MD2.Col14 IS NULL OR MD1.Col14 = MD2.Col14) 48 AND (MD1.Col15 IS NULL OR MD2.Col15 IS NULL OR MD1.Col15 = MD2.Col15) 49 AND (MD1.Col16 IS NULL OR MD2.Col16 IS NULL OR MD1.Col16 = MD2.Col16) 50 ORDER BY 51 MD1.SchemaName,MD1.TableName,MD1.IndexName
3. 添加丢失索引
根据对语句的频次,表中读写比,结合业务对缺失的索引进行建立。
丢失索引,参考执行语句:
1 -- Missing Indexes in current database by Index Advantage 2 SELECT user_seeks * avg_total_user_cost * ( avg_user_impact * 0.01 ) AS [index_advantage] , 3 migs.last_user_seek , 4 mid.[statement] AS [Database.Schema.Table] , 5 mid.equality_columns , 6 mid.inequality_columns , 7 mid.included_columns , 8 migs.unique_compiles , 9 migs.user_seeks , 10 migs.avg_total_user_cost , 11 migs.avg_user_impact , 12 N'CREATE NONCLUSTERED INDEX [IX_' + SUBSTRING(mid.statement, 13 CHARINDEX('.', 14 mid.statement, 15 CHARINDEX('.', 16 mid.statement) 17 + 1) + 2, 18 LEN(mid.statement) - 3 19 - CHARINDEX('.', 20 mid.statement, 21 CHARINDEX('.', 22 mid.statement) 23 + 1) + 1) + '_' 24 + REPLACE(REPLACE(REPLACE(CASE WHEN mid.equality_columns IS NOT NULL 25 AND mid.inequality_columns IS NOT NULL 26 AND mid.included_columns IS NOT NULL 27 THEN mid.equality_columns + '_' 28 + mid.inequality_columns 29 + '_Includes' 30 WHEN mid.equality_columns IS NOT NULL 31 AND mid.inequality_columns IS NOT NULL 32 AND mid.included_columns IS NULL 33 THEN mid.equality_columns + '_' 34 + mid.inequality_columns 35 WHEN mid.equality_columns IS NOT NULL 36 AND mid.inequality_columns IS NULL 37 AND mid.included_columns IS NOT NULL 38 THEN mid.equality_columns + '_Includes' 39 WHEN mid.equality_columns IS NOT NULL 40 AND mid.inequality_columns IS NULL 41 AND mid.included_columns IS NULL 42 THEN mid.equality_columns 43 WHEN mid.equality_columns IS NULL 44 AND mid.inequality_columns IS NOT NULL 45 AND mid.included_columns IS NOT NULL 46 THEN mid.inequality_columns 47 + '_Includes' 48 WHEN mid.equality_columns IS NULL 49 AND mid.inequality_columns IS NOT NULL 50 AND mid.included_columns IS NULL 51 THEN mid.inequality_columns 52 END, ', ', '_'), ']', ''), '[', '') + '] ' 53 + N'ON ' + mid.[statement] + N' (' + ISNULL(mid.equality_columns, N'') 54 + CASE WHEN mid.equality_columns IS NULL 55 THEN ISNULL(mid.inequality_columns, N'') 56 ELSE ISNULL(', ' + mid.inequality_columns, N'') 57 END + N') ' + ISNULL(N'INCLUDE (' + mid.included_columns + N');', 58 ';') AS CreateStatement 59 FROM sys.dm_db_missing_index_group_stats AS migs WITH ( NOLOCK ) 60 INNER JOIN sys.dm_db_missing_index_groups AS mig WITH ( NOLOCK ) ON migs.group_handle = mig.index_group_handle 61 INNER JOIN sys.dm_db_missing_index_details AS mid WITH ( NOLOCK ) ON mig.index_handle = mid.index_handle 62 WHERE mid.database_id = DB_ID() 63 ORDER BY index_advantage DESC;
4. 索引碎片整理
需要通过DBCC check完成索引碎片清理,提高查询时效率。
备注:当前据库很多表比较大(>50G),做表上索引可能花费很长时间,一般1个T的库要8小时以上,建议制定一个详细计划,以表为单位逐步碎片清理。
索引碎片参考执行语句:
1 SELECT '[' + DB_NAME() + '].[' + OBJECT_SCHEMA_NAME(ddips.[object_id], 2 DB_ID()) + '].[' 3 + OBJECT_NAME(ddips.[object_id], DB_ID()) + ']' AS [statement] , 4 i.[name] AS [index_name] , 5 ddips.[index_type_desc] , 6 ddips.[partition_number] , 7 ddips.[alloc_unit_type_desc] , 8 ddips.[index_depth] , 9 ddips.[index_level] , 10 CAST(ddips.[avg_fragmentation_in_percent] AS SMALLINT) 11 AS [avg_frag_%] , 12 CAST(ddips.[avg_fragment_size_in_pages] AS SMALLINT) 13 AS [avg_frag_size_in_pages] , 14 ddips.[fragment_count] , 15 ddips.[page_count] 16 FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, 17 NULL, NULL, 'limited') ddips 18 INNER JOIN sys.[indexes] i ON ddips.[object_id] = i.[object_id] 19 AND ddips.[index_id] = i.[index_id] 20 WHERE ddips.[avg_fragmentation_in_percent] > 15 21 AND ddips.[page_count] > 500 22 ORDER BY ddips.[avg_fragmentation_in_percent] , 23 OBJECT_NAME(ddips.[object_id], DB_ID()) , 24 i.[name]
5. 审查没有聚集、主键索引的表
当前库很多表没有聚集索引,需要细查原因是不是业务要求,如果没有特殊原因可以加上。
查询语句优化
1. 从数据库历史保存信息中,通过DMV获取
- 获取Top100花费时间最多查询SQL
- 获取Top100花费时间最多存储过程
- 获取Top100花费I/O时间最多
参考获取Top100执行语句
1 --执行时间最长的语句 2 SELECT TOP 100 3 execution_count, 4 total_worker_time / 1000 AS total_worker_time, 5 total_logical_reads, 6 total_logical_writes,max_elapsed_time, 7 [text] 8 FROM 9 sys.dm_exec_query_stats qs 10 CROSS APPLY 11 sys.dm_exec_sql_text(qs.sql_handle) AS st 12 ORDER BY 13 max_elapsed_time DESC 14 15 16 --消耗CPU最多的语句 17 SELECT TOP 100 18 execution_count, 19 total_worker_time / 1000 AS total_worker_time, 20 total_logical_reads, 21 total_logical_writes, 22 [text] 23 FROM 24 sys.dm_exec_query_stats qs 25 CROSS APPLY 26 sys.dm_exec_sql_text(qs.sql_handle) AS st 27 ORDER BY 28 total_worker_time DESC 29 30 --消耗IO读最多的语句 31 SELECT TOP 100 32 execution_count, 33 total_worker_time / 1000 AS total_worker_time, 34 total_logical_reads, 35 total_logical_writes, 36 [text] 37 FROM 38 sys.dm_exec_query_stats qs 39 CROSS APPLY 40 sys.dm_exec_sql_text(qs.sql_handle) AS st 41 ORDER BY 42 total_logical_reads DESC 43 44 --消耗IO写最多的语句 45 SELECT TOP 100 46 execution_count, 47 total_worker_time / 1000 AS total_worker_time, 48 total_logical_reads, 49 total_logical_writes, 50 [text] 51 FROM 52 sys.dm_exec_query_stats qs 53 CROSS APPLY 54 sys.dm_exec_sql_text(qs.sql_handle) AS st 55 ORDER BY 56 total_logical_writes DESC 57 58 59 --单个语句查询平均IO时间 60 SELECT TOP 100 61 [Total IO] = (qs.total_logical_writes+qs.total_logical_reads) 62 , [Average IO] = (qs.total_logical_writes+qs.total_logical_reads) / 63 qs.execution_count 64 , qs.execution_count 65 , SUBSTRING (qt.text,(qs.statement_start_offset/2) + 1, 66 ((CASE WHEN qs.statement_end_offset = -1 67 THEN LEN(CONVERT(NVARCHAR(MAX), qt.text)) * 2 68 ELSE qs.statement_end_offset 69 END - qs.statement_start_offset)/2) + 1) AS [Individual Query] 70 , qt.text AS [Parent Query] 71 , DB_NAME(qt.dbid) AS DatabaseName 72 , qp.query_plan 73 FROM sys.dm_exec_query_stats qs 74 CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) as qt 75 CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) qp 76 WHERE DB_NAME(qt.dbid)='tyyl_sqlserver' and execution_count>3 AND qs.total_logical_writes+qs.total_logical_reads>10000 77 --and qt.text like '%POSCREDIT%' 78 ORDER BY [Average IO] DESC 79 80 --单个语句查询平均‘逻辑读’时间 81 SELECT TOP 100 82 deqs.execution_count, 83 deqs.total_logical_reads/deqs.execution_count as "Avg Logical Reads", 84 deqs.total_elapsed_time/deqs.execution_count as "Avg Elapsed Time", 85 deqs.total_worker_time/deqs.execution_count as "Avg Worker Time",SUBSTRING(dest.text, (deqs.statement_start_offset/2)+1, 86 ((CASE deqs.statement_end_offset 87 WHEN -1 THEN DATALENGTH(dest.text) 88 ELSE deqs.statement_end_offset 89 END - deqs.statement_start_offset)/2)+1) as query,dest.text AS [Parent Query], 90 , qp.query_plan 91 FROM sys.dm_exec_query_stats deqs 92 CROSS APPLY sys.dm_exec_sql_text(deqs.sql_handle) dest 93 CROSS APPLY sys.dm_exec_query_plan(deqs.sql_handle) qp 94 WHERE dest.encrypted=0 95 --AND dest.text LIKE'%INCOMINGTRANS%' 96 order by "Avg Logical Reads" DESC 97 98 --单个语句查询平均‘逻辑写’时间 99 SELECT TOP 100 100 [Total WRITES] = (qs.total_logical_writes) 101 , [Average WRITES] = (qs.total_logical_writes) / 102 qs.execution_count 103 , qs.execution_count 104 , SUBSTRING (qt.text,(qs.statement_start_offset/2) + 1, 105 ((CASE WHEN qs.statement_end_offset = -1 106 THEN LEN(CONVERT(NVARCHAR(MAX), qt.text)) * 2 107 ELSE qs.statement_end_offset 108 END - qs.statement_start_offset)/2) + 1) AS [Individual Query] 109 , qt.text AS [Parent Query] 110 , DB_NAME(qt.dbid) AS DatabaseName 111 , qp.query_plan 112 FROM sys.dm_exec_query_stats qs 113 CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) as qt 114 CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) qp 115 WHERE DB_NAME(qt.dbid)='DRSDataCN' 116 and qt.text like '%POSCREDIT%' 117 ORDER BY [Average WRITES] DESC 118 119 120 121 --单个语句查询平均CPU执行时间 122 SELECT SUBSTRING(dest.text, (deqs.statement_start_offset/2)+1, 123 ((CASE deqs.statement_end_offset 124 WHEN -1 THEN DATALENGTH(dest.text) 125 ELSE deqs.statement_end_offset 126 END - deqs.statement_start_offset)/2)+1) as query, 127 deqs.execution_count, 128 deqs.total_logical_reads/deqs.execution_count as "Avg Logical Reads", 129 deqs.total_elapsed_time/deqs.execution_count as "Avg Elapsed Time", 130 deqs.total_worker_time/deqs.execution_count as "Avg Worker Time" 131 ,deqs.last_execution_time,deqs.creation_time 132 FROM sys.dm_exec_query_stats deqs 133 CROSS APPLY sys.dm_exec_sql_text(deqs.sql_handle) dest 134 WHERE dest.encrypted=0 135 AND deqs.total_logical_reads/deqs.execution_count>50 136 ORDER BY QUERY,[Avg Worker Time] DESC
2. 通过工具实时抓取业务高峰期这段时间执行语句
收集工具:
推荐使用SQLTrace或Extend Event,不推荐使用Profiler
收集内容:
- SQL语句
- 存储过程
- Statment语句
分析工具:
推荐ClearTrace,免费。具体使用方法请见我的另外一篇博文介绍。
3. 需要逐条分析以上二点收集到语句,通过类似执行计划分析找出更优化的方案语句
单条语句的执行计划分析工具Plan Explorer,请见我的另外一篇博文介绍
4. 此次优化针对当前库,特别关注下面几个性能杀手问题
- 隐式转化(请参考宋大侠的博文SQL Server中提前找到隐式转换提升性能的办法)
- 参数嗅探(参考桦仔博文何谓SQLSERVER参数嗅探)
- 连接方式
- 缺失聚集索引
五、优化效果
1. 平均CPU使用时间在30000毫秒以上语句由20个减少到3个
2. 执行语句在CPU使用超过10000毫秒的,从1500减少到500个
3. CPU保持在 20%左右,高峰期在40%~60%,极端超过60%以上,极少80%
4. Batch Request从原来的1500提高到4000
最后方一张优化前后的效果对比,有较明显的性能提升,只是解决眼前的瓶颈问题。

小结
数据库的优化只是一个层面,或许解决眼前的资源瓶颈问题,很多发现数据库架构设计问题,受业务的限制,无法动手去做任何优化,只能到此文为止,这好像也是一种常态。从本次经历中,到想到另外一个问题,当只有发生性能瓶颈时候,企业的做法是赶快找人来救火,救完火后,然后就....好像就没有然后...结束。换一种思维,如果能从日常维护中做好监控、提前预警,做好规范,或许这种救火的行为会少些。
感谢2016!
如要转载,请加本文链接并注明出处http://www.cnblogs.com/SameZhao/p/6238997.html,谢谢。