Set 集合
set集合,是一个无序而且不重复的元素集合
list ==> 允许重复的集合,可修改
tuple ==>允许重复的集合,不可修改
dict ==> 允许重复的集合,可修改
set ==> 不允许重复的集合(不允许重复的列表)
创建集合
s = set()
s = set() s.add(11) s.add(11) s.add(11) print(s) >>>{11} s.add(22) print(s) >>> {11, 22}
s = { }
>>> s = {11, 22, 33, 11}
>>> print(s)
{33, 11, 22}
>>> type(s)
<class 'set'>
转换集合
s = set([ ])
s = set(( ))
s = set({ })
l = [11,22,11,33]#列表转换成集合 s1 = set() s2 = set(l) print(s2) >>>{33, 11, 22}
set的基本功能
set.add()
se = set() print(se) >>> set() se.add(44)#增加一个元素 print(se) >>> {44}
set.clear()
se = {11,22,33}
type(se)
>>> <class 'set'>
se.clear()#清空集合内容
print(se)
>>> set()
set.difference()
>>> se = {11,22,33}
>>> be = {22,55}
>>> se.difference(be)#查找se中存在的, 但be不存在的集合, 并赋值给新的变量
{33, 11} #删除共有的元素,并把删除的元素赋值给变量
>>> be.difference(se)
>>> {55}
>>> ret = be.difference(se)
>>> print(ret)
{55}
set.difference_update()
>>> se = {11,22,33}
>>> be = {33,55,66}
>>> se.difference_update(be) #查找se中存在, 但be不存在的元素,并更新集合
>>> print(se)
{11, 22} #删除共有的元素,并更新集合
difference A中存在,B不存在(除去交集),返回一个新的值,由变量接收
difference_update A中存在,B不存在(除去交集),跟新A
set.discard()
set.remove()
set.pop()
>>>se = {11,22,33}
>>>se.discard(11)
>>>print(se)
{33, 22}
>>>se = {11,22,33}
>>>se.remove(11)
>>>print(se)
{33, 22}
>>> se = {11,22,33,44}
>>> ret = se.pop() #由于set是无序的集合,可视为随机删除元素
>>> print(ret)
33
>>> print(se)
{11, 44, 22}
set.intersection()
se = {11,22,33}
be = {22,95, "随便"}
ret = se.intersection(be)
print(ret)
>>>{22}
set.intersection_update()
se = {11,22,33}
be = {22,95, "随便"}
se.intersection_update(be)
print(se)
>>>{22}
set.isdisjoint()
se = {11,22,33}
be = {33,44,55,66,77}
ret = se.isdisjoint(be) #是否有非交集
print(ret)
>>> False #有交集为False, 没交集为True
set.issubset()
se = {22,33,}
be = {11,22,33}
ret = se.issubset(be)#是否子集
print(ret)
>>>True
set.issuperset()
se = {11,22,33,44}
be = {11,22}
ret = se.issuperset(be)#是否父集
print(ret)
>>>Ture
set.symmetric_difference()
se = {11,22,33,44}
be = {11,22,77,55}
ret = se.symmetric_difference(be) #两集合的差集
print(ret)
>>>{33,44,77,55}
set.symmetric_difference_update()
se = {11,22,33,44}
be = {11,22,77,55}
se.symmetric_difference_update(be) #更新se为两集合的差集
print(se)
>>>{33,44,77,55}
set.union()
se = {11,22,33,44}
be = {11,22,77,55}
ret = se.union(be) #并集
print(ret)
>>>{11,22,33,44,55,77}
set.update()
se = {11,22,33,44,55}
be = {11,22,66,77}
se.update(be)
print(se)
>>> {33, 66, 11, 44, 77, 22, 55}
se.update([111,222,333])
print(se)
>>>{33, 66, 11, 44, 77, 333, 111, 22, 55, 222}
集合的源码


1 class set(object): 2 3 """ 4 5 set() -> new empty set object 6 7 set(iterable) -> new set object 8 9 10 11 Build an unordered collection of unique elements. 12 13 """ 14 15 def add(self, *args, **kwargs): # real signature unknown 16 17 """ 18 19 Add an element to a set,添加元素 20 21 22 23 This has no effect if the element is already present. 24 25 """ 26 27 pass 28 29 30 31 def clear(self, *args, **kwargs): # real signature unknown 32 33 """ Remove all elements from this set. 清楚内容""" 34 35 pass 36 37 38 39 def copy(self, *args, **kwargs): # real signature unknown 40 41 """ Return a shallow copy of a set. 浅拷贝 """ 42 43 pass 44 45 46 47 def difference(self, *args, **kwargs): # real signature unknown 48 49 """ 50 51 Return the difference of two or more sets as a new set. A中存在,B中不存在 52 53 54 55 (i.e. all elements that are in this set but not the others.) 56 57 """ 58 59 pass 60 61 62 63 def difference_update(self, *args, **kwargs): # real signature unknown 64 65 """ Remove all elements of another set from this set. 从当前集合中删除和B中相同的元素""" 66 67 pass 68 69 70 71 def discard(self, *args, **kwargs): # real signature unknown 72 73 """ 74 75 Remove an element from a set if it is a member. 76 77 78 79 If the element is not a member, do nothing. 移除指定元素,不存在不保错 80 81 """ 82 83 pass 84 85 86 87 def intersection(self, *args, **kwargs): # real signature unknown 88 89 """ 90 91 Return the intersection of two sets as a new set. 交集 92 93 94 95 (i.e. all elements that are in both sets.) 96 97 """ 98 99 pass 100 101 102 103 def intersection_update(self, *args, **kwargs): # real signature unknown 104 105 """ Update a set with the intersection of itself and another. 取交集并更更新到A中 """ 106 107 pass 108 109 110 111 def isdisjoint(self, *args, **kwargs): # real signature unknown 112 113 """ Return True if two sets have a null intersection. 如果没有交集,返回True,否则返回False""" 114 115 pass 116 117 118 119 def issubset(self, *args, **kwargs): # real signature unknown 120 121 """ Report whether another set contains this set. 是否是子序列""" 122 123 pass 124 125 126 127 def issuperset(self, *args, **kwargs): # real signature unknown 128 129 """ Report whether this set contains another set. 是否是父序列""" 130 131 pass 132 133 134 135 def pop(self, *args, **kwargs): # real signature unknown 136 137 """ 138 139 Remove and return an arbitrary set element. 140 141 Raises KeyError if the set is empty. 移除元素 142 143 """ 144 145 pass 146 147 148 149 def remove(self, *args, **kwargs): # real signature unknown 150 151 """ 152 153 Remove an element from a set; it must be a member. 154 155 156 157 If the element is not a member, raise a KeyError. 移除指定元素,不存在保错 158 159 """ 160 161 pass 162 163 164 165 def symmetric_difference(self, *args, **kwargs): # real signature unknown 166 167 """ 168 169 Return the symmetric difference of two sets as a new set. 对称交集 170 171 172 173 (i.e. all elements that are in exactly one of the sets.) 174 175 """ 176 177 pass 178 179 180 181 def symmetric_difference_update(self, *args, **kwargs): # real signature unknown 182 183 """ Update a set with the symmetric difference of itself and another. 对称交集,并更新到a中 """ 184 185 pass 186 187 188 189 def union(self, *args, **kwargs): # real signature unknown 190 191 """ 192 193 Return the union of sets as a new set. 并集 194 195 196 197 (i.e. all elements that are in either set.) 198 199 """ 200 201 pass 202 203 204 205 def update(self, *args, **kwargs): # real signature unknown 206 207 """ Update a set with the union of itself and others. 更新 """ 208 209 pass
练习
# 数据库中原有 old_dict = { "#1": {'hostname': "c1", 'cpu_count': 2, 'mem_capicity': 80}, "#2": {'hostname': "c1", 'cpu_count': 2, 'mem_capicity': 80}, "#3": {'hostname': "c1", 'cpu_count': 2, 'mem_capicity': 80} } # cmdb 新汇报的数据 new_dict = { "#1": {'hostname': "c1", 'cpu_count': 2, 'mem_capicity': 800}, "#3": {'hostname': "c1", 'cpu_count': 2, 'mem_capicity': 80}, "#4": {'hostname': "c2", 'cpu_count': 2, 'mem_capicity': 80}
找出需要删除:找出需要新建:找出需要更新:注意:无需考虑内部元素是否改变,只要原来存在,新汇报也存在,就是需要更新方法一:
old_key = old_dict.keys() #['#3', '#2', '#1'] new_key = new_dict.keys() #['#3', '#1', '#4'] old_set = set(old_key) new_set = set(new_key) inter_set = old_set.intersection(new_set)#查找两个集合的交集,即需要新建的集合 print(inter_set) >>>set(['#3', '#1']) del_set = old_set.difference(inter_set)#比较old_set和inter_set,找到需删除的元素 print(del_set)
>>>set(['#2']) add_set = new_set.difference(inter_set)#比较new_set和inter_set,找到需要更新的元素 print(add_set)
>>>set(['#4'])
方法二:
old_key = old_dict.keys() #['#3', '#2', '#1'] new_key = new_dict.keys() #['#3', '#1', '#4'] old_set = set(old_key) new_set = set(new_key) del_set = old_set.difference(new_dict) print(del_set) #[2] add_set = new_set.difference(old_set) print(add_set) #[4] update_set = old_set.intersection(new_set) print(update_set) #['#3', '#1']
三元运算
三元运算(三目运算),是对简单的条件语句if,else的缩写。
if 1 == 1: name = 'alex' else: name = 'eric' print(name) >>>alex result = 值1 if 条件 else 值2 # 如果条件成立,那么将 “值1” 赋值给result变量,否则,将“值2”赋值给result变量 name = 'alex' if 1 == 1 else 'eric' print(name) >>>alex
深浅拷贝
字符串,链表数据的存储和修改
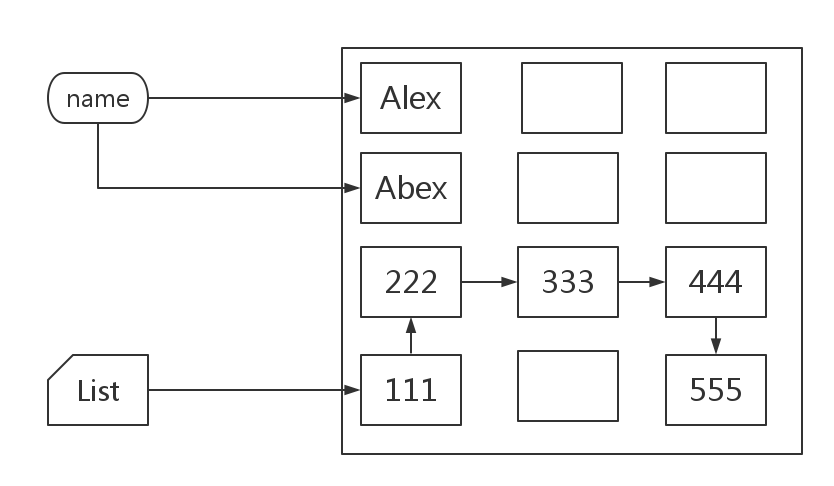
字符串 一次性被创建,不能被修改,只要修改字符串,内存将重新创建新新字符串,并把原来的指针指向新的字符串。
链表 自动记录上下原始的位子,若在列表增加元素append(444,555),元素在内存中被创建,链表的上一个元素的指针自动指向下一个元素的位置。
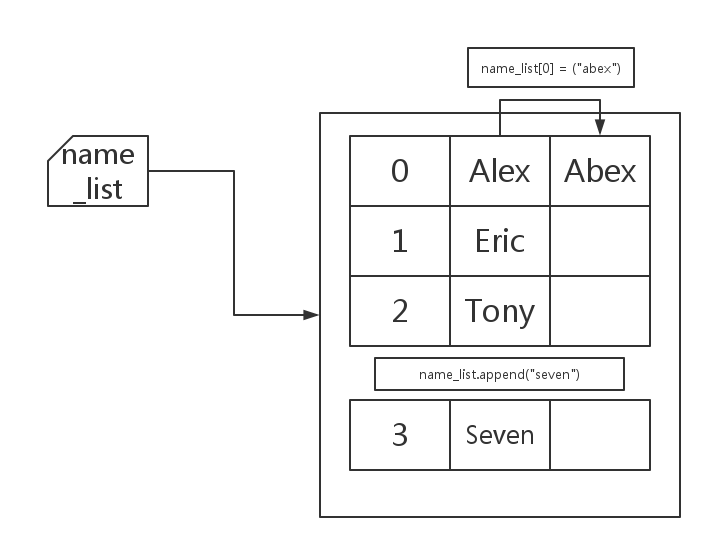
name_list = ['alex', 'eric', 'tony'] name_list[0] = ("abex") print(name_list) >>> ['abex', 'eric', 'tony'] name_list.append("seven") print(name_list) >>>['abex', 'eric', 'tony', 'seven']
数字和字符串
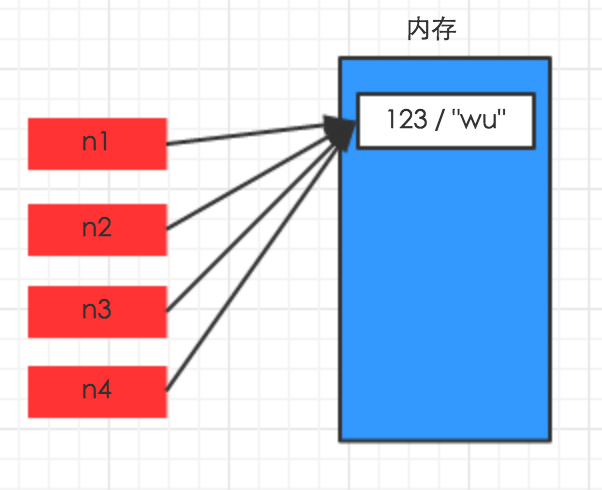
对于 数字 和 字符串 而言,赋值、浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址。
由于字符串和数值都在数据的底层,对他们进行拷贝,赋值,他们的指向地址都相同的。
>>> import copy >>> n1 = 123 >>> n2 = n1 >>> print(id(n1)) 494886544 >>> print(id(n2)) 494886544 >>>
>>> import copy >>> n1 = 123 >>> n2 = copy.copy(n1) >>> n3 = copy.deepcopy(n1) >>> print(id(n1)) 494886544 >>> print(id(n2)) 494886544 >>> print(id(n3)) 494886544 >>>
其他基本数据类型
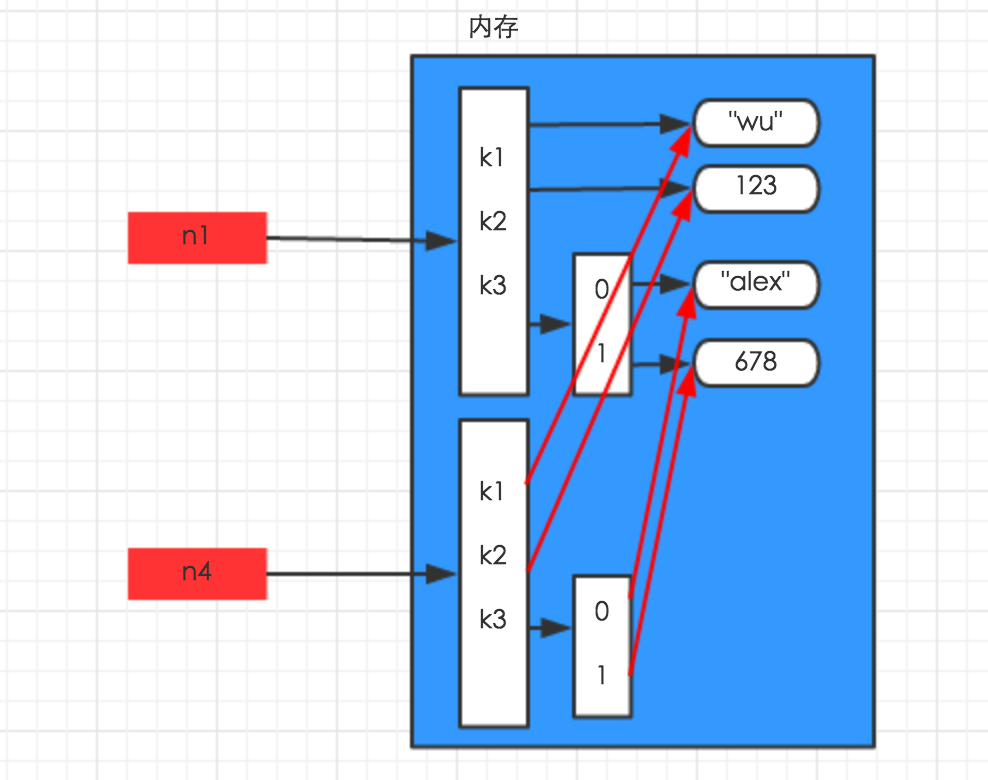
对于字典、元祖、列表 而言,进行赋值、浅拷贝和深拷贝时,变量的索引部分将重新建立在内存中,索引指向的底层数字和字符串与原来的内存地址相同。
1、赋值
赋值,只是创建一个变量,该变量指向原来内存地址,如:
n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}
n2 = n1

2、浅拷贝
浅拷贝,在内存中只额外创建第一层数据
import copy n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]} n3 = copy.copy(n1)

3、深拷贝
深拷贝,在内存中将所有的数据重新创建一份(排除最后一层,即:python内部对字符串和数字的优化)
import copy n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]} n4 = copy.deepcopy(n1)
函数
- 函数式:将某功能代码封装到函数中,日后便无需重复编写,仅调用函数即可
- 面向对象:对函数进行分类和封装,让开发“更快更好更强...”
函数定义和使用
def 函数名(参数):
... 函数体
... 返回值
函数名()#调用函数
ret =函数名()#输出返回值
print('ret')
def foo(): #definition/declaration print('bar') foo #function object/reference foo() #function call/invocation
返回值
由于实际的函数更接近过程,执行过程中不显示返回任何东西,对“什么都不返回的函数”python设定了特殊的名字“None”
“return”可以设定返回str,int,list,tuple,dict,set......
#执行过程没有返回值,如果用“res”保存返回值,该值为“None”
def email(): print("send mail") ret = email() #执行函数 print(ret) #输出函数返回值 >>> send mail None
#设定返回函数“return”
def email(): print("send mail") return 'Ok'#设定返回函数的返回值 ret = email() print(ret) >>> send mail Ok
def email(): if True: return True else: return False ret = email() if ret:#函数return返回什么值,ret返回什么值 print("Ok") else: print("No") >>> Ok
函数的普通参数
形式参数:形式参数是函数定义中的,系统没有为其分配内存空间,但是在定义里面可以使用的参数。
实际参数:实际参数是函数调用的时候传给函数的变量
形式参数,实际参数(按照形式参数默认顺序传递)
def func1(x,y):#(x, y)形式参数 print(x,y) def func2(x,y):#(x, y)形式参数 print(x+y) func1(10, 20)#(10,20)实际参数 func2(10, 100)#(10,100)实际参数 >>> (10, 20) 110
def func(arg):#形式参数 if arg.isdigit(): #判断条件 return True #返回值 else: return False #返回值 k1 = func('123')#实际参数 if k1: #根据返回值判断 print('Ok') else: print('No') >>> Ok
def func(args): #函数的传值, arg引用li的列表,不会重新创建新的[11,22] args.append(123) li = [11,22,] func(li) print(li)
def f1(args): #fi(li)把列表 li 传到args中,args指向 li列表 的数值 args = 123 # args = 123,args的指向改为 ‘123’,不在指向 li 列表 li = [11, 22, 33] f1(li) print(li) >>> [11, 22, 33]
形式参数和实际参数练习
1 def email(email_address, content, subject): 2 3 import smtplib 4 from email.mime.text import MIMEText 5 from email.utils import formataddr 6 7 ret= True 8 9 Try: 10 11 msg = MIMEText(content, 'plain', 'utf-8') 12 msg['From'] = formataddr(["银角大王",'wptawy@126.com']) 13 msg['To'] = formataddr(["蚁民",address]) 14 msg['Subject'] = subject 15 16 server = smtplib.SMTP("smtp.126.com", 25) 17 server.login("wptawy@126.com", "邮箱密码") 18 server.sendmail('wptawy@126.com', [address,], msg.as_string()) 19 server.quit() 20 21 except: 22 23 ret = False 24 25 return ret 26 27 res = email('123456@qq.com', 'No Content', 'No Subject') 28 29 if res: 30 print('发送成功') 31 else: 32 print('发送失败')
指定参数(可以不按照默认形参和实参的顺序,指定参数)
def func(arg1, arg2): if arg1.isdigit() and arg2.isspace(): return True else: return False k1 = func(arg2=' ', arg1='123')#指定参数 # k1 = func('abc') if k1: print('Ok') else: print('No') >>> Ok
函数的默认值
下形式参数中,指定参数的值。
形式参数的默认值应放在形参的最后。
def func(arg1, arg2='100'):#arg2的默认值为100 print(arg1+arg2) func(arg1='alex')#只传arg1的实参值 >>> alex100 def func(arg1, arg2='100'): print(arg1+arg2) func(arg1='alex', arg2='seven')#arg2的实参为‘seven’ >>> alexseven
动态参数
(1) 形式参数前加上'*'(*arg),将会把每个实参作为 元组 的元素传到函数中
def func(*a): #动态参数 print(type(a)) func(123) >>> <type 'tuple'>#生成元组
def func(*a):#动态参数 print(a,(type(a))) func(123, 456, 789)#加入多个实参 >>> ((123, 456, 789), <type 'tuple'>)
(2) 形式参数前加上'**'(*kwarg),需将实参以key, value的形式传到函数中,拼接成 字典。
def func(**a): print(a,(type(a))) func(k1 = 123, k2 = 456) >>> ({'k2': 456, 'k1': 123}, <type 'dict'>)
(3) 两种动态参数结合,
形参的顺序:arg > *arg>**kwarg
def func(p,*a,**aa): print(a,(type(a))) print(aa, (type(aa))) func(11,22,33, k1 = 123, k2 = 456) >>> (11, <type 'int'>) ((22, 33), <type 'tuple'>) ({'k2': 456, 'k1': 123}, <type 'dict'>)
(4) 实际参数加'*',传入的参数将作为元组的唯一元素
*args ---> *list
def func(*args): print(args, (type(args))) li = [11,22,33] func(li) func(*li)#实参加'*'作为元组唯一元素 >>> (([11, 22, 33],), <type 'tuple'>) ((11, 22, 33), <type 'tuple'>)
(5) 实际参数加“**”,传入的参数将作为字典的键值对
**kwargs ---> **dict
def func(**kwargs): print(kwargs, (type(kwargs))) dic = {"k1":123, "k2":456} func(k1=dic) func(**dic) >>> ({'k1': {'k2': 456, 'k1': 123}}, <type 'dict'>) ({'k2': 456, 'k1': 123}, <type 'dict'>)
(6) 以函数作为参数代入另外一个函数中
def f1():#f1 = 函数 print("F1") #f1代指函数 #f1()执行函数 def f2(arg): arg() #执行arg函数,相当于执行F1() return "F2" #执行f2函数,把f1函数当做参数 ret = f2(f1) print(ret)
>>>
F1
F2
函数内部操作流程

全局变量和局部变量
在函数外部设定全局变量,函数内部的局部变量不影响全局变量的赋值
p = 'alex'#全局变量 def func1():#局部变量 a = 123 p = 'eric'#没有改变全局变量 print(a) def func2(): a = 456# 局部变量 print(p) print(a) func1() func2() >>> 123 alex 456
假如需要在函数改变全局变量,需要声明“global 变量名”
p = 'alex'#全局变量 def func1():#局部变量 a = 123 global p #global声明全局变量 p = 'eric' #全局变量的重新赋值 print(a) def func2(): a = 456# 局部变量 print(p) print(a) func1() func2() >>> 123 eric 456
匿名函数lambda表达式
lambda [arg1[, arg2, ... argN]] : expression
对于简单的函数,也存在一种简便的表示方式,即:lambda表达式
def add(x, y): return x + y <===> lambda x, y: x+y
def add(x, y): return x + y ret = add(10, 20) print(ret) >>> 30 func = lambda x, y: x+y res = func(x=10, y=20) print(res) >>> 30
内置函数

abs()
返回输入数字的绝对值。Return the absolute value of a number.
f1 = abs(-123) print(f1) >>> 123
all()
循环参数,若每个元素都为真,返回True,否则返回False。Return True if all elements of the iterable are true (or if the iterable is empty).
r = all([True, True, False]) print(r) >>> False
any()
循环参数,若每个元素都为假,返回True,其中有一个元素为真返回False。Return True if any element of the iterable is true. If the iterable is empty, return False.
r = any([0, None, False, " ", [ ], ( ), { }]) print(r) >>> True
ascii()
在ascii()对象的类中找到__repr__,获得其返回值。As repr(), return a string containing a printable representation of an object, but escape the non-ASCII characters in the string returned by repr() usingx, u or U escapes.
class Foo(): def __repr__(self): return("Hello") obj = Foo() r = ascii(obj) #ascii在obj对应的类中,找出__repr__的返回值 print(r) >>> Hello
bin() 二进制
r = bin(11) #转换为二进制0,1 print(r) >>> 0b1011
oct() 八进制
s = oct(7) #转换为八进制 print(s) >>> 0o7 t = oct(8) print(8) >>> 0o10
int() 十进制
r = int(0xf) print(r) >>> 15
i = int('ob11', base= 2) print(i) >>> 3 j = int('11', base=8) print(j) >>> 9 k = int('0xe', base=16) print(k) >>> 14
hex() 十六进制
分别用数字1-9,字母a-g代表数字
s = hex(9) print(s) >>> 0x9 t = hex(10) print(t) >>> 0xa r = hex(15) print(r) >>> 0xf
ord()
输入一个字符,返回该字符的万国码号。Given a string representing one Unicode character, return an integer representing the Unicode code point of that character.
a = ord("t") print(a) >>> 116
chr()
输入一个万国码,返回万国码相对的字符。Return a Unicode string of one character with ordinal i; 0 <= i <= 0x10ffff.
a = chr(65) print(a) >>> A
#chr()的函数应用 import random temp = '' for i in range(6): num = random.randrange(0, 4)#生成0-4的随机数 if num == 2 or num ==4: #随机数等于2或4时候 rad2 = random.randrange(0, 10)#生成0-10的随机数字 temp = temp + str(rad2)#生成的随机数字转为字符串 else: rad1 = random.randrange(65,91)#生成65-91的随机数 c1 = chr(rad1)#chr()函数返回字母 temp = temp +c1 print(temp)
callable()
判断输入的对象是否为函数,函数返回True,非函数返回False。Return True if the object argument appears callable, False if not.
def f1(): return "123" r = callable(f1) print(r) >>> True
complex()
返回复数形式的数字
r = complex(123+2j) print(r) >>> (123+2j)
dir()
查看类中可执行的函数
a = tuple() print(dir(a)) >>> ['__add__', '__class__',...]
divmod()
输出除法计算的结果,商和余数。Take two (non complex) numbers as arguments and return a pair of numbers consisting of their quotient and remainder when using integer division.
a = 10/3 print(a) >>> 3.3333333333333335 r = divmod(10, 3) print(r) >>> (3, 1)
eval()
执行一个字符串形式的表达式,返回表达式的结果。This function supports dynamic execution of Python code. object must be either a string or a code object. If it is a string, the string is parsed as a suite of Python statements which is then executed (unless a syntax error occurs).
ret = eval('a + 100', {'a': 99}) print(ret) >>> 199
exec()
执行字符串的中python代码,直接返回结果。This function supports dynamic execution of Python code. object must be either a string or a code object. If it is a string, the string is parsed as a suite of Python statements which is then executed (unless a syntax error occurs).
exec("for i in range(3):print(i)") >>> 0 1 2
complie()编译代码
eval() 执行表达式,生成返回值
exec() 执行python代码,返回结果
filter()
按照过滤条件函数,过滤一组可迭代的数组。Construct an iterator from those elements of iterable for which function returns true. iterable may be either a sequence, a container which supports iteration, or an iterator
def func(a): if a > 22: return True else: return False ret = filter(func, [11, 22, 33, 44, ]) for i in ret: print(i) >>> 33 44
ret = filter(lambda a: a > 22, [11, 22, 33, 44, ]) for i in ret: print(i) >>> 33 44
def MyFilter(func, seq): result = [] for i in seq: #func = f1 #func(x)执行f1的函数,并获得返回值,将其赋值给ret ret = func(i) if ret: result.append(i) return result def f1(x): if x > 22: return True else: return False r = MyFilter(f1, [11, 22, 33, 44, 55, 66]) print(r)
map()
将函数作用在序列的每个元素上,然后创建有每次函数函数应用的主城的返回值列表。Return an iterator that applies function to every item of iterable, yielding the results.
def f1(x): return x + 100 ret = map(f1, [1, 2, 3, 4, 5]) for i in ret: print(i) >>> 101 102 103 104 105
li = [1, 2, 3, 4, 5] ret = map(lambda x: x+100 if x % 2 == 1 else x, li) for i in ret: print(i) >>> 101 2 103 4 105
li = [11, 22, 33, 44, 55, 66] def x(arg): return arg+100 def MyMap(func, arg): result = [] for i in arg: ret = func(i) #fun(11) x(11) result.append(ret) return result r = MyMap(x, li)
globals()
获取全局变量。Return a dictionary representing the current global symbol table.
local()
获取局部变量。Update and return a dictionary representing the current local symbol table.
first_name = 'samsam' def func(): last_name = 'broadview' print(locals()) func() print(globals()) >>> {'last_name': 'broadview'} {'__name__': '__main__', '__file__': , 'first_name': 'samsam', ...}
hash()
将函数的字符串或数字转换为哈希值。Return the hash value of the object (if it has one). Hash values are integers. They are used to quickly compare dictionary keys during a dictionary lookup.
dic = { "qwertyuiop123456789:123" } i = hash("qwertyuiop123456789:123") print(i) >>> 831660209
isinstance()
检验输入的对象和类是相同的类属性。Return true if the object argument is an instance of the classinfo argument, or of a (direct, indirect or virtual) subclass thereof.
dic = {"k1":"v1"}
i = isinstance(dic, dict)
print(i)
>>>
True
iter()
创建一个可以被迭代的对象。Return an iterator object.
next()
在可以被迭代的对象按顺序取一个值。Retrieve the next item from the iterator by calling its __next__() method.
obj = iter([11,22,33,44]) print(obj) r1 = next(obj) print(r1) r1 = next(obj) print(r1) r1 = next(obj) print(r1) r1 = next(obj) print(r1) >>> 11 22 33 44
pow()
幂运算。Return x to the power y.
i = pow(2, 10) print(i) >>> 1024
round()
四舍五入。Return the floating point value number rounded to ndigits digits after the decimal point.
i = round(3.6) print(i) >>> 4
zip()
将多个可迭代的对象按照想用的序号合并,生成新的迭代对象。Make an iterator that aggregates elements from each of the iterables.
li1 = [11,22,33,44] li2 = ["a","b","c","d"] r = zip(li1, li2) for i in r: print(i) >>> (11, 'a') (22, 'b') (33, 'c') (44, 'd')
排序
sort() 按照从小到大的顺序排列,返回原来的对象
sorted() 按照从小到大的顺序排列,返回生成新的对象
li = [1,211,22,3,4] li.sort() print(li) >>> [1, 3, 4, 22, 211] li = [1,211,22,3,4] new_li = sorted(li) print(new_li) >>> [1, 3, 4, 22, 211]
char = ["1", "2", "3", "4", "5", "a", "AB", "bc", "_","def延", "惕", "曳", "藻", "谷", "朋", "落", "胚", "萍", "澄", "坷", "羚", "刁"] new_char = sorted(char) print(new_char) for i in new_char: print(bytes(i, encoding="utf-8")) >>> ['1', '2', '3', '4', '5', 'AB', '_', 'a', 'bc', 'def延', '刁', '坷', '惕', '曳', '朋', '澄', '羚', '胚', '萍', '落', '藻', '谷'] b'1' b'2' b'3' b'4' b'5' b'AB' b'_' b'a' b'bc' b'defxe5xbbxb6' b'xe5x88x81' b'xe5x9dxb7' b'xe6x83x95' b'xe6x9bxb3' b'xe6x9cx8b' b'xe6xbex84' b'xe7xbex9a' b'xe8x83x9a' b'xe8x90x8d' b'xe8x90xbd' b'xe8x97xbb' b'xe8xb0xb7'
open()
用于文件处理
操作文件时,一般需要经历如下步骤:
- 打开文件
- 操作文件
- 关闭文件
基本操作文件方式
open(文件名/路径,模式,编码),默认模式为“只读”
f = open('test.log', "r") data = f.read() f.close() print(data) >>> testlog
打开文件时,需要指定文件路径和以何等方式打开文件,打开后,即可获取该文件句柄,日后通过此文件句柄对该文件操作。
打开文件的模式:
- r ,只读模式【默认】
-
f = open('test.log') data = f.read() f.close() print(data) >>> abc123
- w,只写模式【不可读;文件不存在则创建;文件存在则清空内容;】
-
f = open('test.log', 'w') data = f.write('defg123456') #以写方式覆盖文件 f.close() print(data) >>> 10 #写入10个字符
f = open('test.log', 'w') data = f.read() f.close() print(data) >>> data = f.read() io.UnsupportedOperation: not readable#只写方式不能读取文件内同
- x, 只写模式【不可读;文件不存在则创建;文件存在则报错】
-
f = open('test2.log', 'x')#文件不存在,创建一个新的文件 f.write("qwe456") f.close() f = open('test2.log', 'x') f.write("zxcv123456") f.close() >>> f = open('test2.log', 'x') FileExistsError: [Errno 17] File exists: 'test2.log'#文件已经存在,不能创建同名文件
- a, 追加模式【不可读;文件不存在则创建;文件存在则只追加内容;】
-
f = open('test2.log', 'a') data = f.write("9876543210") f.close() print(data) >>> 10 #写入10个字符
"+" 表示可以同时读写某个文件
- r+, 读写【可读,可写】
先读取文档,在文档末尾追加写入,指针移到最后
f = open("test.log", 'r+', encoding = "utf-8") print(f.tell()) #显示指针位置,指针从开始向后读取 f.write("123456") data = f.read() print(data) print(f.tell()) #读取文件后指针位置 f.close() >>> 0 123456 6
- w+,写读【可读,可写】
先把文件内容清空,从开始向后读取文件;重新写入内容后,指针移到最后,读取文件。
f = open("test.log", 'w+', encoding = "utf-8") f.write("123456")#写入完成后,文档指针位置在文件末尾 f.seek(0)#设定指针在文档开始 data = f.read() print(data)
- x+ ,写读【可读,可写】
若文件存在,系统报错,建新文件,再写入内容后,指针移到最后,读取文件。
- a+, 写读【可读,可写】
文件打开同时,文档指针已经设定在最后, 写入文件后,指针留在文件的最后。
f = open("test.log", 'a+', encodig"utf-8") f.write("987654")
print(f.tell()) #显示指针位置 f.seek(0) #设定指针为文档最开始 data = f.read() print(data)
>>>
6
987654
r+ w+ x+ a+都以指针位置读取或写入数据。
"b"表示以字节(bytes)的方式操作
- rb 或 r+b
-
f = open('test2.log', 'wb') f.write(bytes("中国", encoding='utf-8')) f.close() f = open('test2.log', "rb") data = f.read() f.close() print(data) str_data = str(data, encoding='utf - 8') print(str_data) >>> b'xe4xb8xadxe5x9bxbd' 中国
- wb 或 w+b
-
f = open('test2.log', 'wb')
str_data = "中国" bytes_data = bytes(str_data, encoding = 'utf-8')#指定写如的编码
f.write(bytes_data) f.close()f = open('test2.log', 'wb') f.write("中国") f.close() >>> f.write("中国") TypeError: a bytes-like object is required, not 'str'
- xb 或 x+b
- ab 或 a+b
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型
普通打开方式
python内部将底层010101010的字节 转换成 字符串
二进制打开方式
python将读取将底层010101010的字节 再按照程序员设定的编码,转换成字符串。
f = open('test2.log', 'wb') f.write(bytes("中国", encoding='utf-8')) f.close() f = open('test2.log', "rb") data = f.read() f.close() print(data) str_data = str(data, encoding='utf - 8') print(str_data) >>> b'xe4xb8xadxe5x9bxbd' 中国