| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018SE2/homework/11248 |
|---|---|
| 作业目标 | <实现网页爬取数据,对数据进行进一步的处理分析> |
| 作业源代码 | <https://gitee.com/xu-qianlong/pair > |
| 队员1 | <211806417 徐千龙> |
| 队员2 | <211814113 黄朝阳> |
写在开头
可怜的国庆8天假,被砍成了4天,更惨的是4天还要敲代码。
所以我和我的搭档决定,尽量国庆之前搞完uml,放一个相对轻松点的假期。
结对感受
-
一拍即合,相处融洽。针对结对中遇到的困难,一起突破解决。双方分工明确,互通有无。在过程体会代码的快乐,共同进步,共同提高。
-
徐:因为是老搭档了,分工明确,合作很默契。
-
黄:老默契,老摸鱼了。
对方评价
-
徐:黄朝阳同学,努力又心细,不仅完成了他的那部分代码,还帮我完善了我的代码格式,针不戳(真不错)!
-
黄:千龙性格良好,且总能提出细节上的重点,补充完善了交互模型的各个方面,nice!
开局一张图,发育去全靠emmmmmmmmmmmmm

1. 需求分析
- 通过网络爬取数据,需要运用Cookies等信息
- 数据排序,经验值优先,学号次之
- IO将获取数据写入 txt 文件
- Other:这次作业和第一次个人编程作业很像,之前是用html文件抓取内容,这次则是用url和cookie信息在真正的网页上抓取内容,感觉挺有成就感的吧。
2. 时间预计
| 估计 | 实际 | |
|---|---|---|
| 代码行数 | / | 182行 |
| 思路 | 10h | 24h |
| 理出逻辑 | 2h | 5h |
| 编程 | 6h | 12h |
| 博客 | 1h | 2h |
| 总计 | / | 43h |
3. 作业思路
3.1 抓取课堂完成部分URL
每个小模块都有一个data—url,需要将它们保存到一个数组或集合里。之后访问才能访问到课堂完成部分对应的小模块链接的网址。
如图所示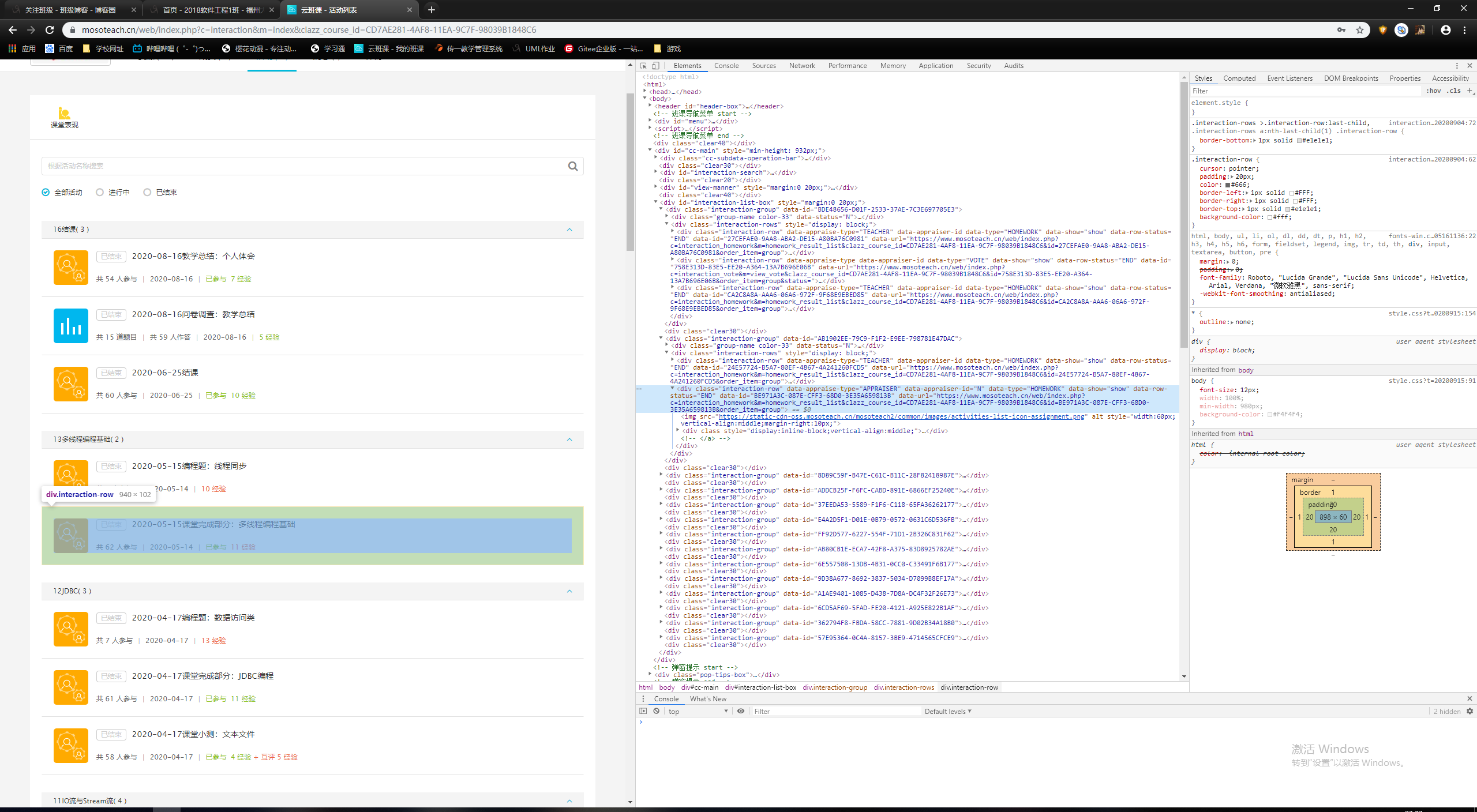

-
抓取URL,并访问模块。
-
Properties prop = new Properties(); prop.load(new FileInputStream("resources//config.properties")); Enumeration fileName = prop.propertyNames(); String url =prop.getProperty("url"); String cookie=prop.getProperty("cookie"); -
我们先将所需的URL链接,以及cookie信息,爬取,放入config.properties 的配置文件,然后通过文件的配置,完成访问。
- 优点:相比本地通过 html 文件爬取数据,更加灵活。
- 缺点:使用cookie 存在被封禁的可能性。cookie配置信息,有时候会出现意外,需要重新配置。
3.2 访问每个小模块,并抓取最终得分。将抓取的数据保存到对象集合里
抓取最终得分的分数,这里分数与经验值同步。通过 hash 存放数据,以及加强 for 取数据发生比对。

-
通过 hash 获取学生的姓名学号,以及经验值。这里我们分成了两个小模块,1. 获取学生姓名和学号:Get_Student_snameandsno 2.获取学生经验值:Get_Student_Score
-
Get_Student_snameandsno 模块。
-
for(int i=0;i<es.size();i++) { String sname = es.get(i).select("span").get(0).text(); String sno = es.get(i).getElementsByClass("member-message").get(0).child(1).text(); Student stu=new Student(sname,sno); Student_Set.add(stu); }- 优点:利用hash,更方便的添加所需的数据。
- 缺点:利用子元素查询,效率较低
-
Get_Student_Score 模块
- 利用for循环获取拘束,通过 if 判断,避免空指针问题。
3.4 排序,利用IO流将数据写入 TXT 文件
-
排序模块 Student_Sort(Set
Student_Set) 利用hash 进行排序。 - 优点:取数据方便,能够快捷高效的获取数据
- 缺点:因为 hash 是无序的,所以排序会变比较麻烦,我们通过两个 hash 来降低排序的麻烦程度。
-
IO流,写入数据
-
BufferedWriter out = new BufferedWriter(new FileWriter(writeName)); out.write("最高经验值为:" + Sort_student[0].getScore() + "," + " 最低经验值为:" + Sort_student[i - 1].getScore() + "," + " 平均经验值为:" + String.format("%.1f", (sum / i - 1))); -
BufferedWriter outStudent = new BufferedWriter(new FileWriter(writeName,true)); -
写入 统计经验和学生的经验,有一些细微的区别。
-
统计经验的写入,我们采用了直接写入,每次都是将txt文件清空,重新写入,保证统计值,是显示在第一行,并且不会发现重复
-
学生经验的写入,我们采用了续写, 在统计经验的后面继续写入。
-
TXT文件展示

-
4. 作业遇到的问题
-
有些课堂完成部分,会遇到同学未提交的情况,这样会造成数据获取时发生越界问题。

- 解决办法:新增一个判断。—— 判断是否为未提交
- 在for循环里面加一个 if (!pd) 判断该同学是否未提交,如果为未提交,则跳过后面分数计算部分,成功避免越界问题。
-
这类的是有最终得分:但是最终得分是尚无评分,截取的时候也会出现问题

- 解决办法:新增一个判断 —— 判断是否为 尚无评分,是的话,则跳过。
-
解决问题的代码如下。
boolean pd = es.get(i).getElementsByClass("homework-info").text().contains("未提交");
if(!pd) {
String sname = es.get(i).select("span").get(0).text();
String xmk = es.get(i).getElementsByClass("appraised-type").get(1).select("span").get(1).text();
if(xmk.equals("尚无评分")) {
}
else {
String score = xmk.substring(0,xmk.indexOf("分"));
float f = Float.parseFloat(score);
for(Student student:Student_Set) {
if(sname.equals(student.getName())) {
student.addScore(f);
break;
}
}
}
}
5. 小结
- 通过这次作业,加深了结对之间的默契,加强了队 json 相关的能力,以及进一步的学会网页的数据爬取,io 文件写入的熟悉。
- 学会初步的使用 hash 进行获取数据