此文旨在把trainNB0这个函数详细讲清楚。
下面所做的工作都是为了求下面这个贝叶斯概率,也叫条件概率:
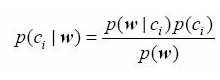
为了计算方便,书中的操作实际上是把这个式子转化为了下式:
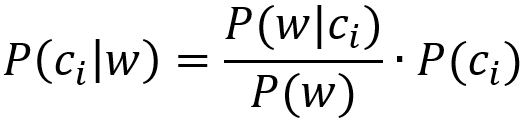
概率P(ci)就是通过类别i(侮辱性留言或非侮辱性留言)中文档数除以总的文档数来得到的,也就是最后得到的计算结果0.5。
这里有一个重要的转化,因为w是一个词条向量,它可以展开为[w0, w1, w2,.......wn]。因为我们此例用到的是朴素贝叶斯假设,所以所有词条都互相独立,
此假设也称为条件独立性假设。那么就意味着我们可以做这样的变换:
p(w|ci) == p(w0,w1,w2,......w2|ci) == p(w0|ci)p(w1|ci)p(w2|ci).......p(wn|ci)
然后![]() 这部分就可以转化为 p(w0,w1,w2,......w2|ci)p(ci) /p(w),进一步转化为:p(w0|ci)p(w1|ci)p(w2|ci).......p(wn|ci)/p(w)
这部分就可以转化为 p(w0,w1,w2,......w2|ci)p(ci) /p(w),进一步转化为:p(w0|ci)p(w1|ci)p(w2|ci).......p(wn|ci)/p(w)
这个转化,是本例能够成立的一个必要条件。
def trainNB0(trainMatrix,trainCategory): numTrainDocs = len(trainMatrix) numWords = len(trainMatrix[0]) pAbusive = sum(trainCategory)/float(numTrainDocs) #(以下两行)初始化概率 p0Num = zeros(numWords); p1Num = zeros(numWords) p0Denom = 0.0; p1Denom = 0.0 for i in range(numTrainDocs): if trainCategory[i] == 1: #(以下两行)向量相加 p1Num += trainMatrix[i] p1Denom += sum(trainMatrix[i]) else: p0Num += trainMatrix[i] p0Denom += sum(trainMatrix[i]) p1Vect = p1Num/p1Denom #change to log() # 对每个元素做除法 p0Vect = p0Num/p0Denom #change to log() return p0Vect,p1Vect,pAbusive
下面把这个函数逐步分解:
1.参数
此函数的参数有两个,一个是trainMatrix,另一个是trainCategory,这两个参数是一步一步的数据处理产生的结果,本节的目的是说明这两个参数值的产生过程。详细如下:
1.1第一步 创建实验样本
可能是为了简化操作,突出重点,作者在这里手工创建了数据集,手工设置了类别,在实际的应用场景中,应当是自动判断自动生成的。
listOPosts,listClasses = bayes.loadDataSet()
这一句产生了listOPosts和listClasses
详细内容分别是:
listOPosts:
[['my','dog','dog','has','flea','problems','help','please'],
['maybe','not','take','him','to','dog','park','stupid'],
['my','dalmation','is','so','cute','I','love','him'],
['stop','posting','stupid','worthless','garbage'],
['mr','licks','ate','my','steak','how','to','stop','him'],
['quit','buying','worthless','dog','food','stupid']
]
listClasses:
[0,1,0,1,0,1]
其中的listOPosts即list Of Posts,文档列表,就是帖子列表、邮件列表等等。你可以认为列表中的一元素就是一个帖子或者回复,
在此例中一共6个文档、帖子、回复(以后统称文档)。
分别是:
['my','dog','dog','has','flea','problems','help','please']
['maybe','not','take','him','to','dog','park','stupid']
['my','dalmation','is','so','cute','I','love','him']
['stop','posting','stupid','worthless','garbage']
['mr','licks','ate','my','steak','how','to','stop','him']
['quit','buying','worthless','dog','food','stupid']
可以看到,2、4、6句标红部分,存在侮辱性词条,第1、3、5个句子,不存在侮辱性词条,所以,对应的类别标签设置为
listClasses = [0,1,0,1,0,1]
1.2第二步 创建包含所有不重复词条的集合(词汇表)
这一步是为了产生一个大而全的集合,这个集合包括了所有文档(即第一步产生的6个文档)中的词条,但每个词条都不重复。
#创建一个所有文档中的不重复单词列表 def createVocabList(dataSet): vocabSet = set([]) #创建一个空集 n = 0 for document in dataSet: vocabSet = vocabSet | set(document) #创建两个集合的并集 n += 1 # print('vocabSet:',n,vocabSet) # print('文档集合的总长度:',len(vocabSet)) a = list(vocabSet) a.sort()
return a
Python中的集合(set)具有消除重复元素的功能。
书中代码没有排序。为了看得更清楚,我加上了排序。
上述代码中的
vocabSet = vocabSet | set(document)
并集操作,相当于 += 操作
此函数的参数dataSet,即是上一步产生的listOPosts
调用方式:
myVocablList = createVocabList(listOfPosts)
运行结果是:
['I', 'ate', 'buying', 'cute', 'dalmation', 'dog', 'flea', 'food', 'garbage', 'has', 'help', 'him', 'how', 'is', 'licks', 'love',
'maybe', 'mr', 'my', 'not', 'park', 'please', 'posting', 'problems', 'quit', 'so', 'steak', 'stop', 'stupid', 'take', 'to', 'worthless']
1.3第三步 文档向量
获得词汇表后,便可以使用函数setOfWords2Vec(),该函数的输入参数为词汇表及某个文档,输出的是文档向量,向量的每一元素为1或0,分别表示词汇表中的单词在输入文档中是否出现。
def setOfWords2Vec(vocabList, inputSet): returnVec = [0] * len(vocabList)
for word in inputSet: if word in vocabList: # print("word:",word) returnVec[vocabList.index(word)] = 1 else: print("the word:%s is not in my Vocabulary!" % word) return returnVec # 返回一个list
vocabList即上一步产生的词汇表,inputSet可以是任意一篇文档,此处为了简化操作,在6篇文档中选取。
调用方式:
listOfPosts,listClasses = loadDataSet() print(listOfPosts) myVocablList = createVocabList(listOfPosts) print(myVocablList) l = listOfPosts[0] l.append("中华人民共和国") l.append("kk") print("listOfPosts:", listOfPosts[0]) b = setOfWords2Vec(myVocablList, listOfPosts[0]) print(b)
我们的输入是:
listOfPosts[0],它的值是:
['my', 'dog', 'dog', 'has', 'flea', 'problems', 'help', 'please']
从索引为0的元素开始循环,如果这个元素存在于词汇表中,则把要返回的类别向量returnVec中对应位置的值设为1。
此处第1个值是my,它存在于词汇表中,位置是18,所以把returnVec中的对应位置的值设置为1
得到:[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| I | ate | buying | cute | dalmation | dog | flea | food | garbage | has | help | him | how | is | licks | love | maybe | mr | my | not | park | please | posting | problems | quit | so | steak | stop | stupid | take | to | worthless |
第2个值是dog,它存在于词汇表中,位置是5,把returnVec中的对应位置的值设置为1
得到:[0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| I | ate | buying | cute | dalmation | dog | flea | food | garbage | has | help | him | how | is | licks | love | maybe | mr | my | not | park | please | posting | problems | quit | so | steak | stop | stupid | take | to | worthless |
以此类推,直到最后得到:
[0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
至此,我们得到了一篇文档listOfPosts[0]的词向量
用同样的方式,我们还可以得到listOfPosts[1]、listOfPosts[2]、listOfPosts[3]、listOfPosts[4]、listOfPosts[5]文档的词向量,分别是:
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0]
[1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1]
[0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0]
[0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1]
1.4第四步
至此,我们可以说明trainNB0(trainMatrix, trainCategory)中的参数是什么了。
trainMatrix就是由各个文档转化成的词向量构成的矩阵,而trainCategory就是这几个文档的类别,也就是这几个文档是不是含有侮辱性词条。
trainMatrix的值为:
[
[0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0],
[1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1],
[0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0],
[0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1]
]
trainCategory的值为:
[0, 1, 0, 1, 0, 1]
2.过程
numTrainDocs = len(trainMatrix)
这句是取得词向量矩阵的长度,也就是说文档的数量,此例中是6个。
numWords = len(trainMatrix[0])
取得词向量矩阵中第一条记录的长度,也就是词条(即特征)的数量,此例应当是32个。
pAbusive = sum(trainCategory)/float(numTrainDocs)
p表示概率,abusive的意思是辱骂的、滥用的,pAbusive表示辱骂文档的概率。这个值即是第一节的公式中所需要的P(Ci),是通过类别i(侮辱性留言或非侮辱性留言)中文档数除以总的文档数来计算的。
sum(trainCategory) ==> sum([0, 1, 0, 1, 0, 1]) ==> 3
此处用==>符号表示“推出”、“等于”
numTrainDocs==6
所以
pAbusive = sum(trainCategory)/float(numTrainDocs)==>
pAbusive == 3/6 ==>
pAbusive == 0.5
也就是说,6篇文档,其中有3篇含有侮辱性词条,概率是0.5,即P(C1)==0.5。
需要求的3个值,已经求出了一个,还需要P(w|Ci)和P(w)两个值。
p0Num = zeros(numWords)
p1Num = zeros(numWords)
上面这两句是要初始化一个概率,是什么概率?
p0Denom = 0.0; p1Denom = 0.0
上式中的Denom是分母的意思,把分母项置为0,这是要干什么?
for i in range(numTrainDocs): if trainCategory[i] == 1: #❷(以下两行)向量相加 p1Num += trainMatrix[i] p1Denom += sum(trainMatrix[i]) else: p0Num += trainMatrix[i] p0Denom += sum(trainMatrix[i])
按照文档个数,从0到5循环。
如果文档类别是侮辱性(trainCategory[i] == 1),则把侮辱性文档的词向量相叠加,否则把非侮辱性文档的词向量相叠加。这样说有点拗口,看看下面的实际执行过程:
由前面的计算结果可知,trainCategory的值是[0, 1, 0, 1, 0, 1],放在这里看着方便。
i==0时:
trainCategory[0]是0,
所以p0Num += trainMatrix[0],
而trainMatrix[0]是[0, 0, 0, 0, 0, 1[5], 1[6], 0, 0, 1[9], 1[10], 0, 0, 0, 0, 0, 0, 0, 1[18], 0, 0, 1[21], 0, 1[22], 0, 0, 0, 0, 0, 0, 0, 0]
为了方便比较,我在列表中增加了中括号括起来的索引值
同时,p0Denom += sum(trainMatrix[0]),trainMatrix[0]中有7个1,所以此时p0Denom的值是7
i==1时:
trainCategory[1]是1,
所以p1Num += trainMatrix[1],
而trainMatrix[1]是[0, 0, 0, 0, 0, 1[5], 0, 0, 0, 0, 0, 1[11], 0, 0, 0, 0, 1[16], 0, 0, 1[19], 1[20], 0, 0, 0, 0, 0, 0, 0, 1[28], 1[29], 1[30], 0]
同时,p1Denom += sum(trainMatrix[1]),trainMatrix[1]中有8个1,所以此时p1Denom的值是8
i==2时:
trainCategory[2]是0,所以p0Num += trainMatrix[2]
而trainMatrix[2]是[1[0], 0, 0, 1[3], 1[4], 0, 0, 0, 0, 0, 0, 1[5], 0, 1[7], 0, 1[9], 0, 0, 1[12], 0, 0, 0, 0, 0, 0, 1[19], 0, 0, 0, 0, 0, 0]
叠加之后,p0Num的值为:[ 1. 0. 0. 1. 1. 1. 1. 0. 0. 1. 1. 1. 0. 1. 0. 1. 0. 0.2. 0. 0. 1. 0. 1. 0. 1. 0. 0. 0. 0. 0. 0.]
可以看到,是列表中的每个位置对应的值相加。
同时,p0Denom += sum(trainMatrix[2]),trainMatrix[2]中有8个1,所以此时p0Denom的值是7+8=15
以此类推,最后的结果是:
p0Num == [ 1. 1. 0. 1. 1. 1. 1. 0. 0. 1. 1. 2. 1. 1. 1. 1. 0. 1.3. 0. 0. 1. 0. 1. 0. 1. 1. 1. 0. 0. 1. 0.]
p1Num == [ 0. 0. 1. 0. 0. 2. 0. 1. 1. 0. 0. 1. 0. 0. 0. 0. 1. 0.0. 1. 1. 0. 1. 0. 1. 0. 0. 1. 3. 1. 1. 2.]
p0Denom==24
p1Denom==19
插播一句,发现了一个翻译错误: 英文版第70页,原文是The numerator is a NumPy array with the same number of elements as you have words in your vocabulary. 中文版第61页,译文是“上述程序中的分母变量是一个元素个数等于词汇表大小的NumPy数组。”
应改为:“上述程序中的分子变量是一个元素个数等于词汇表大小的NumPy数组。”
运行结果如下:
|
p0V: [ 0.04166667 0.04166667 0. 0.04166667 0.04166667 0.04166667 0.04166667 0. 0. 0.04166667 0.04166667 0.08333333 0.04166667 0.04166667 0.04166667 0.04166667 0. 0.04166667 0.125 0. 0. 0.04166667 0. 0.04166667 0. 0.04166667 0.04166667 0.04166667 0. 0.
|
对于这个结果,我曾经对作者的说明感到困惑不解。下面列出我经过逐步了解后的解释:
首先,我们发现文档属于侮辱类的概率pAb为0.5,该值是正确的。
接下来,看一看在给定文档类别条件下词汇表中单词的出现概率,看看是否正确。
词汇表中的第一个词是cute,其在类别0中出现1次,而在类别1中从未出现。对应的条件概率分别为0.041 666 67与0.0。该计算是正确的。
我们找找所有概率中的最大值,该值出现在P(1)数组第26个下标位置,大小为0.15789474。在myVocabList的第26个下标位置上可以查到该单词是stupid。
这意味着stupid是最能表征类别1(侮辱性文档类)的单词。
第一句说,“我们发现文档属于侮辱类的概率pAb为0.5,该值是正确的。”,0.5这个数值的来源是清楚的,但此处作者做了一个诊断,说该值是正确的,是什么意思?一直没太明白。
可能一:有3个非侮辱,3个侮辱,所以概率是0.5,正确的。
可能二:经过计算,和我们肉眼可见的3/6符合,所以结果是正确的。如果是这样,那这是一句废话,本来就是按照这个算法计算的,何必要强调一下。
还有其它可能吗?待定,也许将来更加深入以后会知道。
第二句,接下来,看一看在给定文档类别条件下词汇表中单词的出现概率,看看是否正确。这里指的是P(w|ci)
第三句,最大值是0.15789474,对应的词条是stupid,它在类别为1的类别中出现了3次,所以它是最能表往类别1的词条。此处存疑。
如果把3个stupid分别改成stupid、fuck、shit,那么它就会和其它只出现1一次的词条一样,值变为0.05263158。
这个时候,谁是更能突出表征类别1的词条?
这一节只是把词条的出现概率计算完毕,没有完成整个算式。
4.5.3 测试算法:根据现实情况修改分类器
前面所提到的概率公式转化结果p(w0|ci)p(w1|ci)p(w2|ci).......p(wn|ci)/p(w)的意义是,列表内部的概率相乘,得到的积除以p(w)。
如果有概率为0,那么乘积就是0,凭经验也可以知道这是不合理的,对于这个问题,书中给出了一个方法,将所有词的出现数初始化为1,并将分母初始化为2。
书中只给出了方法,并没有解释为什么这么做。后经查询,这种方法叫拉普拉斯平滑。来源:https://www.cnblogs.com/knownx/p/7860174.html
背景:为什么要做平滑处理?
零概率问题,就是在计算实例的概率时,如果某个量x,在观察样本库(训练集)中没有出现过,会导致整个实例的概率结果是0。在文本分类的问题中,当一个词语没有在训练样本中出现,该词语调概率为0,使用连乘计算文本出现概率时也为0。这是不合理的,不能因为一个事件没有观察到就武断的认为该事件的概率是0。
拉普拉斯的理论支撑
为了解决零概率的问题,法国数学家拉普拉斯最早提出用加1的方法估计没有出现过的现象的概率,所以加法平滑也叫做拉普拉斯平滑。
假定训练样本很大时,每个分量x的计数加1造成的估计概率变化可以忽略不计,但可以方便有效的避免零概率问题。
它的背后的原理就是当数量特别庞大时,个体就没有那么重要。99%和100%在概率上来讲也没什么区别。
p(w0|ci)p(w1|ci)p(w2|ci).......p(wn|ci)