本文进行了以下工作:
- OS中建立了两个文件,文件中保存了几组单词。
- 把这两个文件导入了hadoop自己的文件系统。
- 介绍删除已导入hadoop的文件和目录的方法,以便万一发生错误时使用。
- 使用列表命令查看导入的文件和新建的目录。
- 调用hadoop自带的示例jar包hadoop-0.20.2-example.jar中的程序wordcount,输出结果,以测试本hadoop系统是否可以正常工作。
- 在OS中查看hadoop所产生的文件。
- 在web页面中查看系统各状态。
预备知识
和各种大型关系型数据库(如sql server和oracle等)一样,Hadoop有自己的文件系统,在操作系统中只能看到文件,用文件工具强制打开以后是无法理解的乱码,只能通过Hadoop系统去管理和读取。
所以OS的文件系统和hadoop的文件系统是相互独立的,要用hadoop,需要从OS中把文件导入hadoop系统。
准备测试文件
OS中hadoop目录下新建input目录,之所以叫input,是因为相对hadoop系统来讲,这个目录是输入目录。
用echo “hello world” >test1.txt的方式,创建两个文件,当然可以用其它任何方式创建文件。结果如图所示:
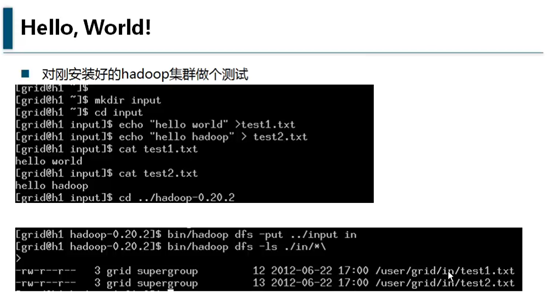
bin/hadoo dfs -put ../input in
-put的意思是把本地的input目录下的文件放到hadoop系统的in目录下。
完成以后可用以下命令查看:
bin/hadoop dfs -ls in/*
效果如上图。意思是:列出in目录下的所有目录及文件
如果要从hadoop中删除一个目录,则使用以下命令
bin/hadoop dfs -rmr 目录名
参数dfs表示对分布式文件系统进行操作,相应的还有jar,表示调用jar包中的程序。
运行java程序,对已配置完成的hadoop系统进行测试

运行bin/hadoop jar hadoop-0.20.2-examples.jar wordcount in out
jar表示运行java程序,一般是一个mapreduce的作业,即提交mapreduce作业。图中的hadoop-0.20.2是hadoop提供的示例jar包,wordcount程序在其中,in指出hadoop系统中的原始数据目录,out是hadoop系统中的输出数据目录,如果不存在,则自动创建。顾名可思义,wordcount是用来统计单词出现次数的程序。
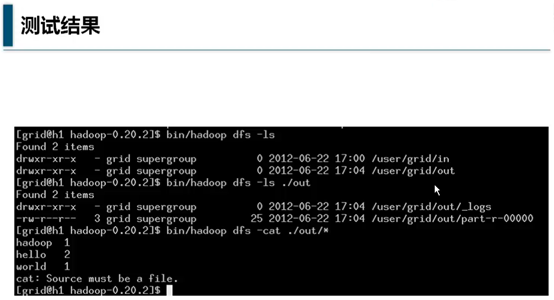
bin/hadooop dfs -ls,表示列出根目录的目录列表
bin/hadooop dfs -ls out,表示列出out目录的目录列表
输出后,执行结果放在了part-r-00000文件中,日志放在了_logs目录
hadoop dfs -cat out/part-r-00000
是显示part-r-00000的结果,可以看到
hadood 出现了1次,hello出现了2次,world出现了1次

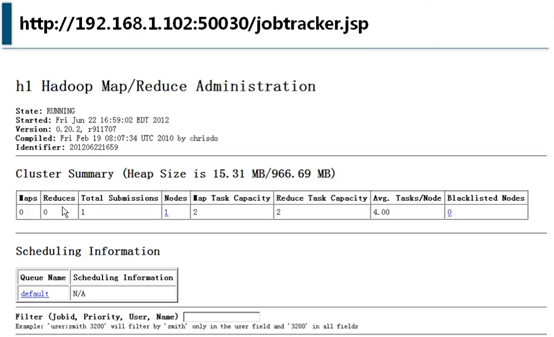
在namenode上可以用localhost:50030,远程可以用IP:50030,如http://192.168.1.8:50030
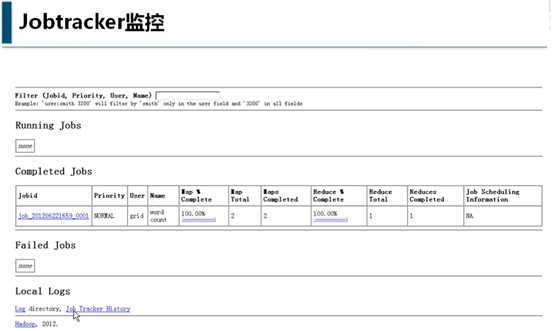
最后,再把前面提到的关于hadoop是一个独立的文件系统用实际数据展示一下:
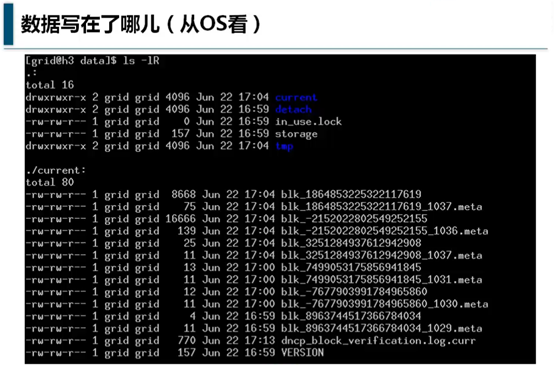
可以看到meta是原始数据,不带meta的是数据文件。
这些文件会保存在数据节点(小弟机、slaves)的hdfs-site.xml文件中的fs.data.dir所指向的目录,如/opt/hadoop/data。修改后此值后,master调用bin/stop-all.sh,再调用bin/start-all.sh后完成重新启动后,就能看到新的数据目录。