| 博客班级 | 计算机与信息学院AHPU-机器学习实验-计算机18级 |
|---|---|
| 作业要求 | 实验二 K近邻算法及应用 |
| 作业目标 | (1)实现曼哈顿距离、欧氏距离、闵式距离算法,并测试算法正确性。 |
| (2) 掌握K近邻树实现算法,实现K近邻树算法; | |
| (3)针对iris数据集,应用sklearn的K近邻算法进行类别预测。 | |
| (4)针对iris数据集,编制程序使用K近邻树进行类别预测。 | |
| (5)查阅文献,讨论K近邻的优缺点及应用场景; | |
| (6)分析算法的核心复杂度; | |
| 学号 | <3180701116> |
一、实验目的
1.理解K-近邻算法原理,能实现算法K近邻算法;
2.掌握常见的距离度量方法;
3.掌握K近邻树实现算法;
4.针对特定应用场景及数据,能应用K近邻解决实际问题。
二、实验内容
1.实现曼哈顿距离、欧氏距离、闵式距离算法,并测试算法正确性。
2.实现K近邻树算法;
3.针对iris数据集,应用sklearn的K近邻算法进行类别预测。
4.针对iris数据集,编制程序使用K近邻树进行类别预测。
三、实验要求
1.对照实验内容,撰写实验过程、算法及测试结果;
2.代码规范化:命名规则、注释;
3.分析核心算法的复杂度;
4.查阅文献,讨论K近邻的优缺点;
5.举例说明K近邻的应用场景。
四、实验过程
1
Language:
import math
%#导入数学运算函数
from itertools import combinations
实验截图:

2
Language:
#计算欧式距离
def L(x, y, p=2):
# x1 = [1, 1], x2 = [5,1]
if len(x) == len(y) and len(x) > 1:
# 当两个特征的维数相等时,并且维度大于1时。
sum = 0
# 目前总的损失函数值为0
for i in range(len(x)): # 用range函数来遍历x所有的维度,x与y的维度相等。
sum += math.pow(abs(x[i] - y[i]), p)
# math.pow( x, y )函数是计算x的y次方。
return math.pow(sum, 1/p)# 距离公式。
else:
return 0
实验截图:

3
# 课本例3.1
x1 = [1, 1]
x2 = [5, 1]
x3 = [4, 4]
实验截图:

4
Language:
# 计算x1与x2和x3之间的距离
for i in range(1, 5): # i从1到4
r = { '1-{}'.format(c):L(x1, c, p=i) for c in [x2, x3]} # 创建一个字典
print(min(zip(r.values(), r.keys()))) # 当p=i时选出x2和我x3中距离x1最近的点
实验截图:

5
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from collections import Counter
实验截图:

6
# data 输入数据
iris = load_iris() # 获取python中鸢尾花Iris数据集
df = pd.DataFrame(iris.data, columns=iris.feature_names) # 将数据集使用DataFrame建表
df['label'] = iris.target # 将表的最后一列作为目标列
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label'] # 定义表中每一列
# data = np.array(df.iloc[:100, [0, 1, -1]])
实验截图:

7
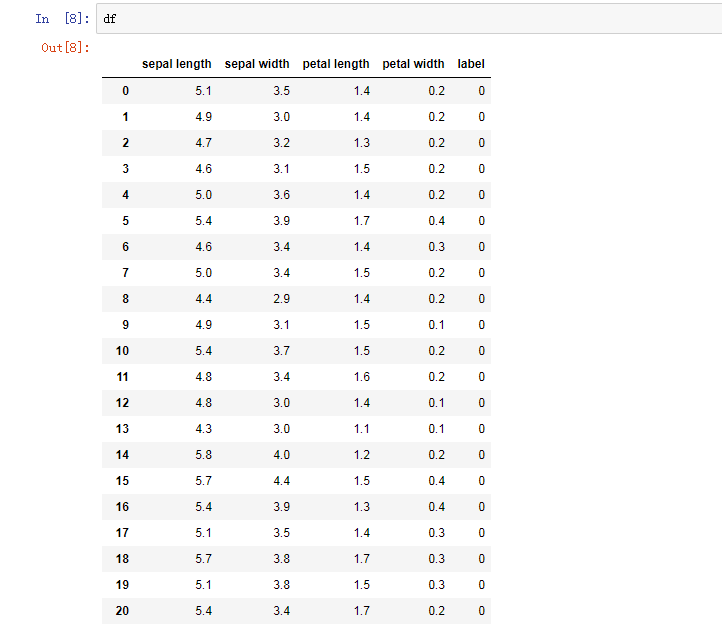
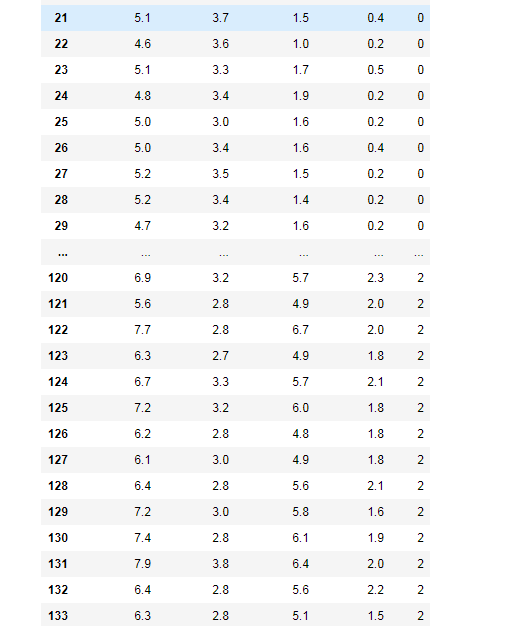
df#查看已建立的表格
实验截图:

8
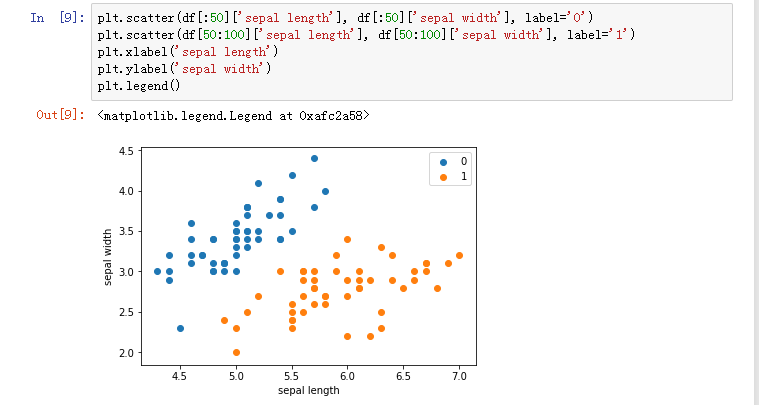
#绘制散点图
plt.scatter(df[:50]['sepal length'], df[:50]['sepal width'], label='0')
plt.scatter(df[50:100]['sepal length'], df[50:100]['sepal width'], label='1')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()
实验截图:
9
Language:
data = np.array(df.iloc[:100, [0, 1, -1]])
#按行索引,取出第0列第1列和最后一列,即取出sepal长度、宽度和标签
X, y = data[:,:-1], data[:,-1]
#X为sepal length,sepal width y为标签
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# train_test_split函数用于将矩阵随机划分为训练子集和测试子集
实验截图:

10
Language:
#定义模型
class KNN:
def __init__(self, X_train, y_train, n_neighbors=3, p=2): # 初始化数据,neighbor表示邻近点,p为欧氏距离
"""
parameter: n_neighbors 临*点个数
parameter: p 距离度量
"""
self.n = n_neighbors#临*点个数
self.p = p#距离度量
self.X_train = X_train
self.y_train = y_train
def predict(self, X):
# 取出n个点,放入空的列表,列表中存放预测点与训练集点的距离及其对应标签
# 取距离最小的k个点:先取前k个,然后遍历替换
# knn_list存“距离”和“label”
knn_list = []
for i in range(self.n):
#np.linalg.norm 求范数
dist = np.linalg.norm(X - self.X_train[i], ord=self.p)
knn_list.append((dist, self.y_train[i]))
#再取出训练集剩下的点,然后与n_neighbor个点比较大叫,将距离大的点更新
#保证knn_list列表中的点是距离最小的点
for i in range(self.n, len(self.X_train)):
max_index = knn_list.index(max(knn_list, key=lambda x: x[0]))
dist = np.linalg.norm(X - self.X_train[i], ord=self.p)
#g更新最*邻中距离比当前点远的点
if knn_list[max_index][0] > dist:
knn_list[max_index] = (dist, self.y_train[i])
# 统计
knn = [k[-1] for k in knn_list]
#counter为计数器,按照标签计数
count_pairs = Counter(knn)
#排序
max_count = sorted(count_pairs, key=lambda x:x)[-1]
return max_count
#预测的正确率
def score(self, X_test, y_test):
right_count = 0
n = 10
for X, y in zip(X_test, y_test):
label = self.predict(X)
if label == y:
right_count += 1
return right_count / len(X_test)
实验截图:

11
clf = KNN(X_train, y_train)#调用knn算法进行计算
12
clf.score(X_test, y_test)#计算正确率
13
test_point = [6.0, 3.0]#预测点
print('Test Point: {}'.format(clf.predict(test_point)))#预测结果
14
plt.scatter(df[:50]['sepal length'], df[:50]['sepal width'], label='0')
plt.scatter(df[50:100]['sepal length'], df[50:100]['sepal width'], label='1')#打印预测点
plt.plot(test_point[0], test_point[1], 'bo', label='test_point')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()
15
from sklearn.neighbors import KNeighborsClassifier
16
clf_sk = KNeighborsClassifier()
clf_sk.fit(X_train, y_train)
实验截图:

17
clf_sk.score(X_test, y_test)
18
Language:
# kd-tree每个结点中主要包含的数据结构如下
class KdNode(object):
def __init__(self, dom_elt, split, left, right):
self.dom_elt = dom_elt #结点的父结点
self.split = split #划分结点
self.left = left #左结点
self.right = right # 右结点
class KdTree(object):
def __init__(self, data):
k = len(data[0]) # 数据维度
def CreateNode(split, data_set): # 按第split维划分数据集exset创建KdNode
if not data_set: # 数据集为空
return None
# key参数的值为一个函数,此函数只有一个参数且返回一个值用来进行比较
# operator模块提供的itemgetter函数用于获取对象的哪些维的数据,参数为需要获取的数据在对象
#data_set.sort(key=itemgetter(split)) # 按要进行分割的那一维数据排序
data_set.sort(key=lambda x: x[split])
split_pos = len(data_set) // 2 # //为Python中的整数除法
median = data_set[split_pos] # 中位数分割点
split_next = (split + 1) % k # cycle coordinates
# 递归的创建kd树
return KdNode(median, split,
CreateNode(split_next, data_set[:split_pos]), # 创建左子树
CreateNode(split_next, data_set[split_pos + 1:])) # 创建右子树
self.root = CreateNode(0, data) # 从第0维分量开始构建kd树,返回根节点
# KDTree的前序遍历
def preorder(root):
print (root.dom_elt)
if root.left: # 节点不为空
preorder(root.left)
if root.right:
preorder(root.right)
实验截图:

19
# 对构建好的kd树进行搜索,寻找与目标点最近的样本点:
from math import sqrt
from collections import namedtuple
# 定义一个namedtuple,分别存放最近坐标点、最近距离和访问过的节点数
result = namedtuple("Result_tuple", "nearest_point nearest_dist nodes_visited")
def find_nearest(tree, point):
k = len(point) # 数据维度
def travel(kd_node, target, max_dist):
if kd_node is None:
return result([0] * k, float("inf"), 0) # python中用float("inf")和float("-inf")表示正负
nodes_visited = 1
s = kd_node.split # 进行分割的维度
pivot = kd_node.dom_elt # 进行分割的“轴”
if target[s] <= pivot[s]: # 如果目标点第s维小于分割轴的对应值(目标离左子树更近)
nearer_node = kd_node.left # 下一个访问节点为左子树根节点
further_node = kd_node.right # 同时记录下右子树
else: # 目标离右子树更近
nearer_node = kd_node.right # 下一个访问节点为右子树根节点
further_node = kd_node.left
temp1 = travel(nearer_node, target, max_dist) # 进行遍历找到包含目标点的区域
nearest = temp1.nearest_point # 以此叶结点作为“当前最近点”
dist = temp1.nearest_dist # 更新最近距离
nodes_visited += temp1.nodes_visited
if dist < max_dist:
max_dist = dist # 最近点将在以目标点为球心,max_dist为半径的超球体内
temp_dist = abs(pivot[s] - target[s]) # 第s维上目标点与分割超平面的距离
if max_dist < temp_dist: # 判断超球体是否与超平面相交
return result(nearest, dist, nodes_visited) # 不相交则可以直接返回,不用继续判断
#----------------------------------------------------------------------
# 计算目标点与分割点的欧氏距离
temp_dist = sqrt(sum((p1 - p2) ** 2 for p1, p2 in zip(pivot, target)))
if temp_dist < dist: # 如果“更近”
nearest = pivot # 更新最近点
dist = temp_dist # 更新最近距离
max_dist = dist # 更新超球体半径
# 检查另一个子结点对应的区域是否有更近的点
temp2 = travel(further_node, target, max_dist)
nodes_visited += temp2.nodes_visited
if temp2.nearest_dist < dist: # 如果另一个子结点内存在更近距离
nearest = temp2.nearest_point # 更新最近点
dist = temp2.nearest_dist # 更新最近距离
return result(nearest, dist, nodes_visited)
return travel(tree.root, point, float("inf")) # 从根节点开始递归
实验截图:

20
data = [[2,3],[5,4],[9,6],[4,7],[8,1],[7,2]]
kd = KdTree(data)
preorder(kd.root)
实验截图:

21
from time import clock
from random import random
# 产生一个k维随机向量,每维分量值在0~1之间
def random_point(k):
return [random() for _ in range(k)]
# 产生n个k维随机向量
def random_points(k, n):
return [random_point(k) for _ in range(n)]
实验截图:

22
ret = find_nearest(kd, [3,4.5])
print (ret)
实验截图:

23
N = 400000
t0 = clock()
kd2 = KdTree(random_points(3, N)) # 构建包含四十万个3维空间样本点的kd树
ret2 = find_nearest(kd2, [0.1,0.5,0.8]) # 四十万个样本点中寻找离目标最近的点
t1 = clock()
print ("time: ",t1-t0, "s")
print (ret2)
实验截图:

五、查阅文献
1.k近邻法是基本且简单的分类与回归方法。k近邻法的基本做法是:对给定的训练实例点和输入实例点,首先确定输入实例点的k个最近邻训练实例点,然后利用这k个训练实例点的类的多数来预测输入实例点的类。
2.k近邻模型对应于基于训练数据集对特征空间的一个划分。k近邻法中,当训练集、距离度量、k值及分类决策规则确定后,其结果唯一确定。
3.k近邻法三要素:距离度量、k值的选择和分类决策规则。常用的距离度量是欧氏距离及更一般的pL距离。k值小时,k近邻模型更复杂;k值大时,k近邻模型更简单。k值的选择反映了对近似误差与估计误差之间的权衡,通常由交叉验证选择最优的k。
常用的分类决策规则是多数表决,对应于经验风险最小化。
4.k近邻法的实现需要考虑如何快速搜索k个最近邻点。kd树是一种便于对k维空间中的数据进行快速检索的数据结构。kd树是二叉树,表示对k维空间的一个划分,其每个结点对应于k维空间划分中的一个超矩形区域。利用kd树可以省去对大部分数据点的搜索, 从而减少搜索的计算量。
K近邻算法优缺点:
算法优点:
(1)简单,易于理解,易于实现,无需估计参数。
(2)训练时间为零。它没有显示的训练,不像其它有监督的算法会用训练集train一个模型(也就是拟合一个函数),然后验证集或测试集用该模型分类。KNN只是把样本保存起来,收到测试数据时再处理,所以KNN训练时间为零。
(3)KNN可以处理分类问题,同时天然可以处理多分类问题,适合对稀有事件进行分类。
(4)特别适合于多分类问题(multi-modal,对象具有多个类别标签), KNN比SVM的表现要好。
(5)KNN还可以处理回归问题,也就是预测。
(6)和朴素贝叶斯之类的算法比,对数据没有假设,准确度高,对异常点不敏感。
算法缺点:
(1)计算量太大,尤其是特征数非常多的时候。每一个待分类文本都要计算它到全体已知样本的距离,才能得到它的第K个最近邻点。
(2)可理解性差,无法给出像决策树那样的规则。
(3)样本不平衡的时候,对稀有类别的预测准确率低。当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。
(4)对训练数据依赖度特别大,对训练数据的容错性太差。如果训练数据集中,有一两个数据是错误的,刚刚好又在需要分类的数值的旁边,这样就会直接导致预测的数据的不准确。
K近邻算法应用场景:
(1)多分类问题场景
在多分类问题中的k邻法,k邻法的输入为实例的特征向量,对应于特征空间的点,输出为实例的类别。
k邻法假设给定一个训练数据集,其中的实例类别已定,分类时,对新的实例,根据其k个最邻的训练实例的类别,通过多数表决等方式进行预测。因此,k邻法不具有显示的学过程(或者说是一种延迟学),k邻法实际上利用训练数据集对特征向量空间进行划分,并作为其分类的“模型”。
(2)回归问题的场景
KNN算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最*邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。
更有用的方法是将不同距离的邻居对该样本产生的影响给予不同的权值(weight),如权值与距离成正比。