对于大规模部署微服务(微服务数>1000)、内部服务异构程度高(交互协议/开发语言类型>5)的场景,使用service mesh是合适的。但是,可能大部分开发者面临的微服务和内部架构异构复杂度是没有这么高的。在这种情况下,使用service mesh就是一个case by case的问题了。
理论上,service mesh 实现了业务逻辑和控制的解耦。但是这并不是免费的。由于网络中多了一跳,增加了性能和延迟的开销。另一方面,由于每个服务都需要sidecar, 这会给本来就复杂的分布式系统更加复杂,尤其是在实施初期,运维对service mesh本身把控能力不足的情况下,往往会使整个系统更加难以管理。
本质上,service mesh 就是一个成规模的sidecar proxy集群。那么如果我们想渐进的改善我们的微服务架构的话,其实有针对性的部署配置gateway就可以了。该gateway的粒度可粗可细,粗可到整个api总入口,细可到每个服务实例。并且 Gateway 只负责进入的请求,不像 Sidecar 还需要负责对外的请求。因为 Gateway 可以把一组服务给聚合起来,所以服务对外的请求可以交给对方服务的 Gateway。于是,我们只需要用一个只负责进入请求的 Gateway 来简化需要同时负责进出请求的 Sidecar 的复杂度。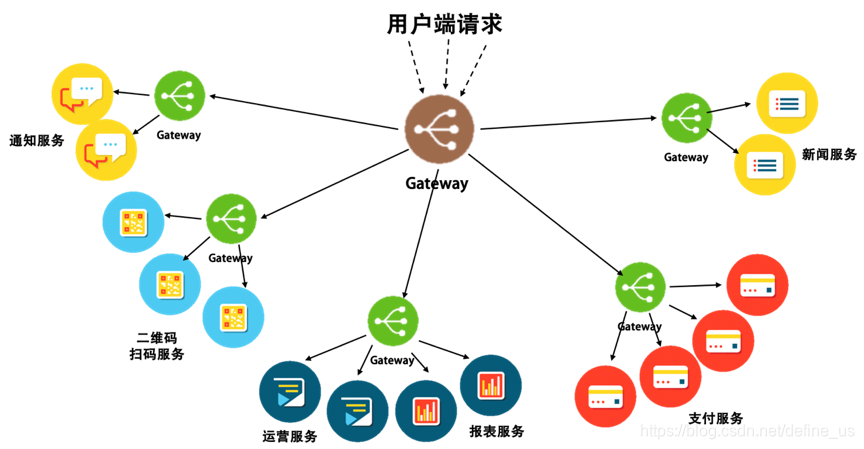
小结:service mesh不是银弹。对于大规模部署、异构复杂的微服务架构是不错的方案。对于中小规模的微服务架构,不妨尝试一下更简单可控的gateway, 在确定gateway已经无法解决当前问题后,再尝试渐进的完全service mesh化。
什么是Service Mesh?
- Service Mesh是专用的基础设施层。
- 轻量级高性能网络代理。
- 提供安全的、快速的、可靠地服务间通讯。
- 与实际应用部署一起但对应用是透明的。
Service Mesh能做什么?
- 提供熔断机制(circuit-breaking)。
- 提供感知延迟的负载均衡(latency-awareload balancing)。
- 最终一致的服务发现(service discovery)。
- 连接重试(retries)及终止(deadlines)。
- 管理微服务和云原生应用通讯的复杂性,确保可靠地交付应用请求。
Service Mesh是必要的吗?
这可能没有一个绝对的答案,但是:
- Service Mesh可使得快速转向微服务或者云原生应用。
- Service Mesh以一种自然的机制扩展应用负载,解决分布式系统不可避免的部分失败,捕捉高度动态分布式系统的变化。
- 完全解耦于应用。
业界有哪些Service Mesh产品?
- Buoyant的linkerd,基于Twitter的Fingle,长期的实际产线运行经验及验证,支持Kubernetes、DC/OS容器管理平台,也是CNCF官方支持的项目之一。
- Lyft的Envoy,7层代理及通信总线,支持7层HTTP路由、TLS、gRPC、服务发现以及健康监测等。
- IBM、Google、Lyft支持的Istio,一个开源的微服务连接、管理平台以及给微服务提供安全管理,支持Kubernetes、Mesos等容器管理工具,其底层依赖于Envoy。
什么是linkerd?
- 为云原生应用提供弹性的Service Mesh。
- 透明高性能网络代理。
- 提供服务发现机制、动态路由、错误处理机制及应用运行时可视化。
linkerd的特性:
- 快速、轻量级、高性能。
- 每秒以最小的时延及负载处理万级请求。
- 易于水平扩展。
- 支持任意开发语言及任意环境。
- 提供基于感知时延的负载均衡。
- 通过实时性能数据分发请求。
- 由于linkerd工作于RPC层,可根据实时观测到的RPC延迟、要处理请求队列大小决定如何分发请求,优于传统启发式负载均衡算法如LRU、TCP活动情况等。
- 提供多种负载均衡算法如:Power of Two Choices (P2C): Least Loaded、Power of Two Choices: Peak EWMA、Aperture: Least Loaded、Heap: Least Loaded以及Round-Robin。
- 运行时流量路由。
- 通过特定HTTP头进行Per-Request级别路由。
- 动态修改dtab规则实现流量迁移、蓝绿部署、金丝雀部署、跨数据中心failover等。
- 熔断机制。
- Fail Fast — 会话驱动的熔断器。
- Failure Accrual — 请求驱动的熔断器。
- 插入式服务发现。
- 支持各种服务发现机制如:基于文件(File-based),Zookeeper,Consul及Kubernetes。
- 支持多种协议:HTTP/1.1、HTTP/2、gRPC、Thrift、Mux。
- 经过产线测试及验证。