AWK
概念
- Awk是一种文本处理工具
- Awk是目前Linux与Unix强大的数据处理引擎之一
语法组成方式
任何AWK语法都是由模式与动作组成 一个AWK脚本可以有多个语句 模式决定动作语句的触发动作与时间
# 模式
正则表达式 : /root/ 匹配含有 root 的行 /*.root/
关系表达式: < > && || + *
匹配表达式: ~ ! ~
# 动作
变量 命令 内置函数 流控制语句
AWK执行步骤
- 读取:从文件 管道 标准输出读取数据存放到内存中
- 执行:将读取的内容按照Body体内的内容执行相应的动作
- 重复:重复上述动作直到数据全部读取完成

内置变量(预定义变量)
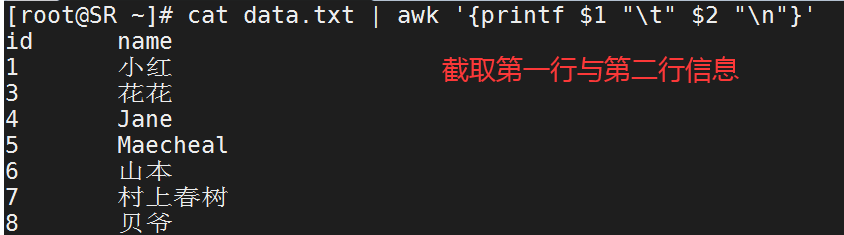
$n
当前记录的第n个字段 例如:$1记录的第一个字段 $2记录的第二个字段
[root@SR ~]# cat data.txt | awk '{printf $1 " " $2 "
"}'
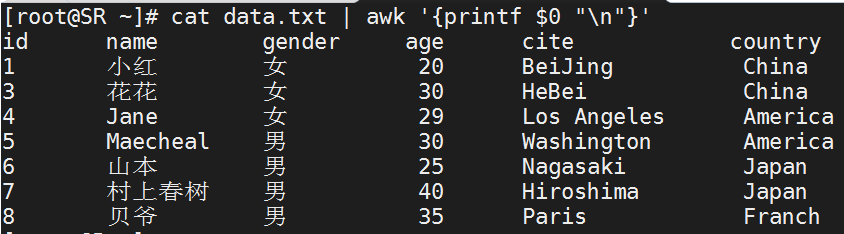
$0
包含执行过程中当前行的文本内容
[root@SR ~]# cat data.txt | awk '{printf $0 "
"}'
FS
文件的分隔符(默认是空格进行分割)
[root@SR ~]# cat passwd | awk 'BEGIN{FS=":"} {printf $1 " " $3 "
"}' | head -1

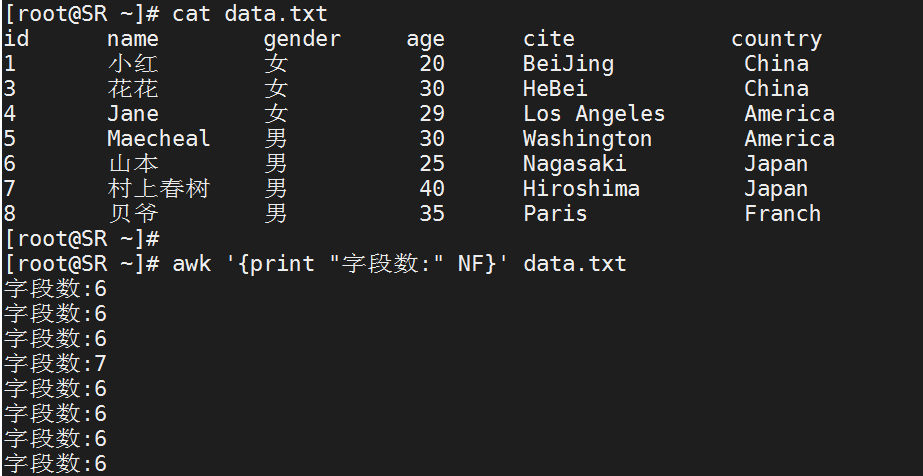
NF
代表的是一个文本文件中一行(一条记录)中的字段个数
[root@SR ~]# awk '{print "字段数:" NF}' data.txt
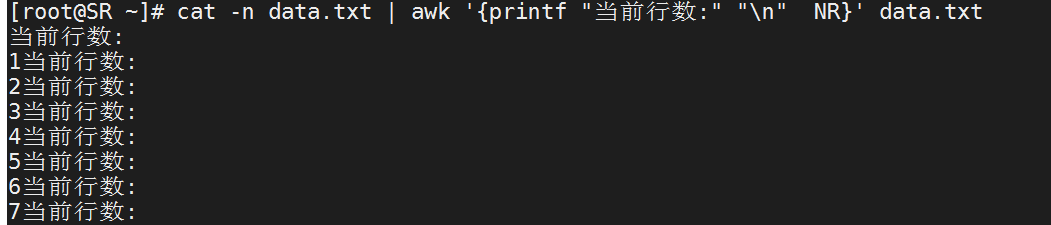
NR
代表当前文本的行数 例如:NR==2表示第二行
[root@SR ~]# cat -n data.txt | awk '{printf "当前行数:" "
" NR}' data.txt
FNR
各文件分别计数的行号
OFS
输出字段分隔符(默认是一个空格)
ORS
输出记录分隔符(默认值是一个换行符)
RS
记录分割符(默认是一个换行符)
AWK常见使用方式
分隔符使用
-F/fs 其中 fs 是指定输入分隔符, fs 可以是字符串或正则表达式;分隔符默认是空格
[root@SR ~]# echo "AA BB CC DD" | awk -F " " '{printf $2 " " "
"}'

[root@SR ~]# echo "AA|BB|CC|DD" | awk -F "|" '{print $1 }'

[root@SR ~]# echo "12AxAbADXaAD52" | awk 'BEGIN {FS="aA"} {print $2}'

# 过滤IP地址
[root@SR ~]# ifconfig ens160 | grep netmask | awk '{print $2}'

关系运算符
[root@SR ~]# echo "1 2 3 4 5" | awk '{print $1 +10}'

[root@SR ~]# echo "1 2 3 4" | awk '{print $NF}'

# 打印 uid < 10的用户名以及shell解释器
[root@SR ~]# cat passwd | awk -F ":" '$3 < 10 {printf $1 " " $NF "
"}' | head -1

# 打印UID大于等于1000的用户名以及shell解释器
[root@SR ~]# cat passwd | awk -F ":" ' $3 >= 1000 && $NF== "/bin/bash" {printf $1 " " $NF "
"}'

脚本使用
# 统计内存使用频率
[root@SR ~]# cat mem.sh
#!/bin/bash
mem_user=`free -m | grep -i mem | awk '{print $3/$2*100"%"}'`
echo -e "内存使用百分比为>>: e[31m${mem_user}e[0m"

AWK的高级应用
awk模式
empty
regular expression
仅仅处理能够被当前匹配的行数
# 匹配以root开头的
[root@SR ~]# cat passwd | awk -F ":" '/^root/{print$0}'

范围匹配
# 输出行号大于等于 3 且行号小于等于 6 的行
[root@SR ~]# cat passwd | awk -F ":" 'NR>=3&&NR<=6 {printf NR ":" $1 " " $NF "
"}'

内置变量
$0 表示整个当前行
NF 字段数量 NF(Number 数量 ; field 字段)
NR 每行的记录号,多文件记录递增 Record [?rek?:d]
制表符
换行符
~ 匹配
!~ 不匹配
-F'[:#/]+' 定义三个分隔符
NR
表示当前行号
使用NR过滤IP地址
[root@SR ~]# ifconfig ens160 | awk -F " " 'NR==2 {print $2}'

FNR
[root@SR ~]# awk '{print FNR" " $0}' /etc/hosts /etc/hostname

- 对于NR来说读取不同的文件时候 NR是一直增加的
- 对于FNR来说读取不同的文件时候 FNR值会从1开始进行计算
!~
# 匹配出不是第一行内容
[root@SR ~]# cat passwd | awk -F ":" 'NR !=1 {print "当前行数" NR ":" $0}' | head -1

条件表达式
if-true/if-false
# 类似于Python的三元表达式 ?前面为真则执行?后面的语句 否则执行:后面的语句
[root@SR ~]# cat passwd | awk -F ":" '{ $3<10?test="UID小于10":test="UID大于10";print $1":" test}' | head -5

if(条件){命令}/elif(条件){命令}/else{命令}
# 如果 UID 小于 5 ,则输出 小于5用户名,否则输出 大于5用户名
[root@SR ~]# cat passwd | awk -F ":" '{if($3 <5 ){print "UID小于5用户名称>>:" $1} else {print "UID大于5用户名称>>:" $1}}' | head -10

变量
[root@SR ~]# var="test"
[root@SR ~]# awk 'BEGIN{print "'$var'"}'

修饰符
- N:显示宽度
- -:进行左对齐
- 一个字母占一个宽度 默认是右对齐
# 显示时用 10 个字符串右对齐显示。如果要显示的字符串不够 10 个宽度,以字符串的左边自动添加。一个字母占一个宽度。 默认是右对齐
[root@SR ~]# cat passwd | awk -F ":" '{printf "%10s
" , $1}' | head -5

# 第 1 列使用 15 个字符宽度左对齐输出,最后一列使用 15 个字符宽度右对齐输出
[root@SR ~]# cat passwd | awk -F ":" '{printf "用户名:%-15s shell类型:%15s
" , $1, $NF}' | head -2
