前言:前段时间学习了各种神经网络,今天做个小总结。以便以后自己复习!
一.RNN-循环神经网络
1.原理:根据“人的认知是基于过往的经验和记忆”这一观点提出。RNN之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。如处理电影评论时,不能一次处理一条,而要将所有评论转化为一个大向量,再一次性处理。
2.结构:
每个方框可以看做是一个单元,每个单元做的事情也是一样的,用一句话解释RNN就是,一个单元结构重复使用。
3.应用:自然语言处理(NLP),文本生成(机器写小说),语言模型等。
4.简例:
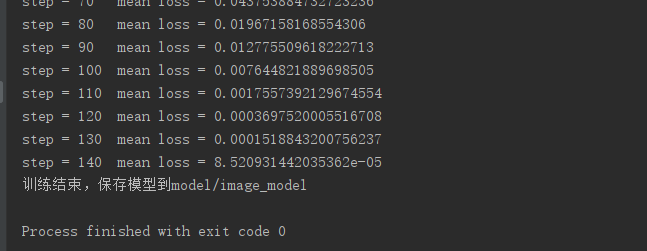
(1)生成莎士比亚文集:我们利用RNN循环神经网络,生成新的文本。
>>代码如下:<1>定义模型参数

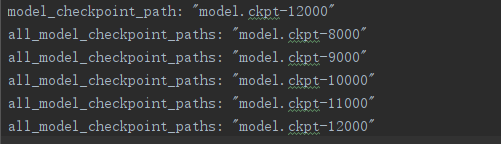
<2>恢复模型
<3>结果:
(2)识别mnist数据集:MNIST数据集是深度学习的经典入门demo,它是由6万张训练图片和1万张测试图片构成的,每张图片都是28*28大小(如下图),而且都是黑白色构成(这里的黑色是一个0-1的浮点数,黑色越深表示数值越靠近1),这些图片是采集的不同的人手写从0到9的数字。

在tensorflow中已经内嵌了mnist数据集,如下:
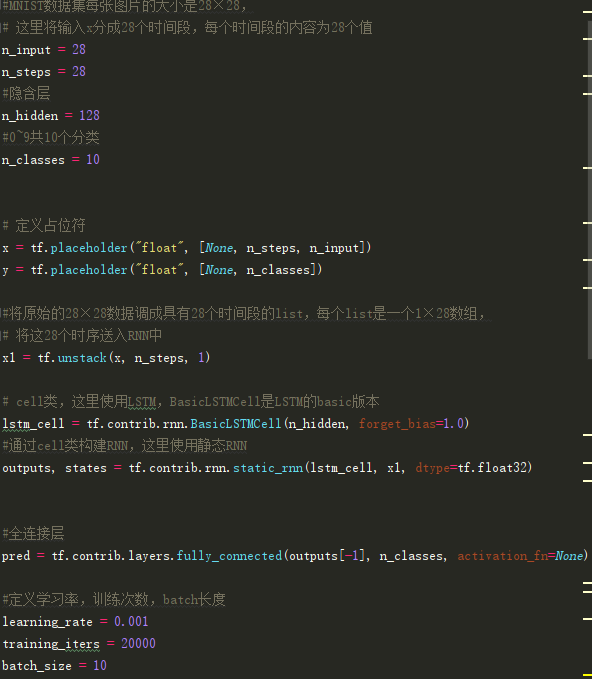
>>代码如下:
>>结果有:

二.CNN-卷积神经网络
- 原理:在神经网络中,每一层的每个神经元都与下一层的每个神经元相连,这种连接关系叫全连接(Full Connected)。如果以图像识别为例,输入就是是每个像素点,那么每一个像素点两两之间的关系(无论相隔多远),都被下一层的神经元"计算"了。这种全连接的方法用在图像识别上面就显得太"笨"了,因为图像识别首先得找到图片中各个部分的"边缘"和"轮廓",而"边缘"和"轮廓"只与相邻近的像素们有关。这个时候卷积神经网络(CNN)就派上用场了,卷积神经网络可以简单地理解为,用滤波器(Filter)将相邻像素之间的"轮廓"过滤出来。
- 结构:
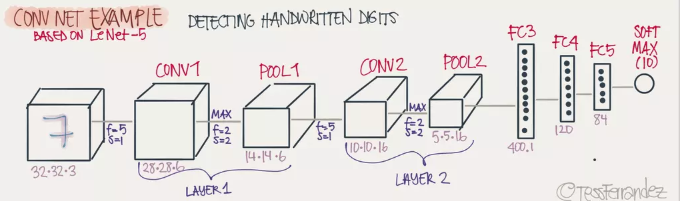
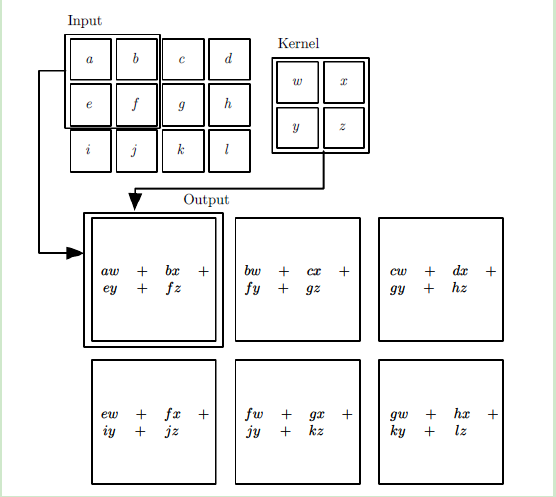
如图是一个完整的深度CNN模型,第一个方块是输入层,后边紧跟着就是卷积层和池化层,这两层是CNN所特有的。卷积层+池化层可以在隐藏层出现许多次,上图我们画出了两次。若干个卷积+池化后是全连接层。图片是卷积层工作原理:
实验一:
1.任务需求
mnist手写识别是经典的入门分类任务。给定28x28x1的输入图像,输出0-9共计十类的分类结果。本次实现分两部分:(1).用传统的全连接神经网络实现分类,(2)使用卷积神经网络(CNN)实现分类!
2.使用工具
Python,pycharm
Tensorflow 1.1.4
3.框架
(一)传统神经网络
- 输入层:拉伸的手写文字图像,维度为[-1,28x28]。
- 全连接层:500个结点,维度为[-1,500]。
- 输出层:分类输出,维度为[-1,10]。
(二)卷积神经网络
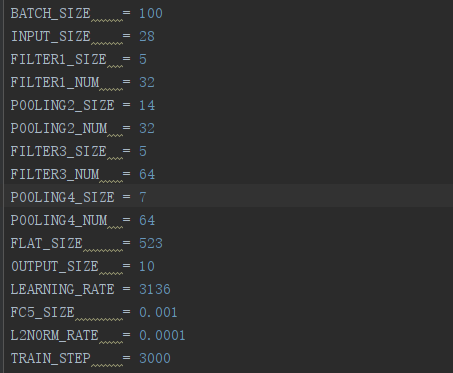
1.输入层:手写文字图像,维度为[-1,28,28,1]。
2.卷积层1:filter的shape为5x5x32,strides为1,padding为“SAME”。卷积后维度为[-1,28,28,32]。
3.池化层2:max-pooling,ksize为2x2,步长为2。池化后维度为[-1,14,14,32]。
4.卷积层3:filter的shape为5x5x64,strides为1,padding为“SAME”。卷积后维度为[-1,14,14,64]。
5.池化层4:max-pooling,ksize为2x2,步长为2。池化后维度为[-1,7,7,64]。
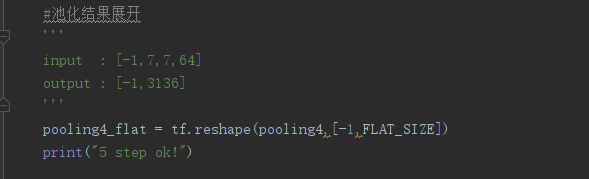
6.池化后结果展开:将池化层4 feature map展开,[-1,7,7,64] => [-1,3136]。
7.全连接层5:输入维度 [-1,3136],输出维度 [-1,512]。
8.全连接层6:输入维度 [-1,512],输出维度 [-1,10],经softmax后,得到分类结果。
4.代码:
(1)定义参数:
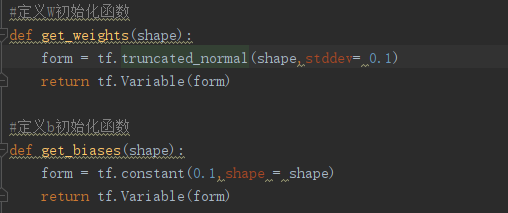
(2)定义初始化函数
(3)定义第一个卷积层+池化层:

(4)定义第二个卷积层+池化层:

池化结果展开:
(5)运行结果:
<1>传统神经网络
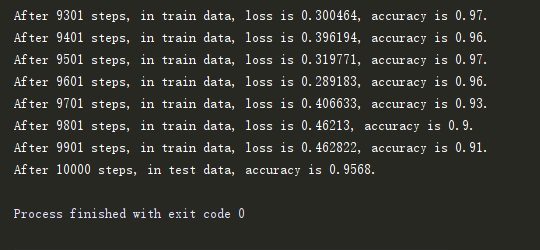
<2>卷积神经网络-CNN

可以看到CNN的训练结果,精确度更高。
实验二:
1.(1)概述:利用卷积网络完成一个图像分类的功能;
(2)训练完成后,模型保存在model中,可以进行线上分类;
(3)在cnn.py代码中包括了训练和测试两个功能,通过修改train=true或者是false来进行训练还是测试。
2.数据准备:
教程的图片从Cifar数据集中获取,download_cifar.py从Keras自带的Cifar数据集中获取了部分Cifar数据集,并将其转换为jpg图片。
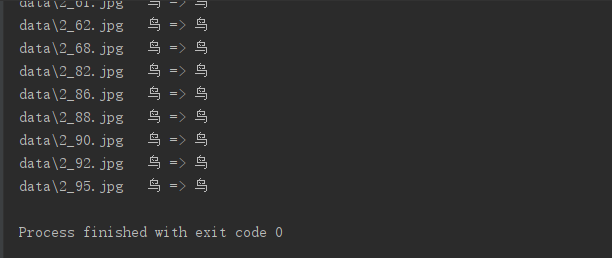
默认从Cifar数据集中选取了3类图片,每类50张图,分别是
0 => 飞机
1 => 汽车
2 => 鸟
图片都放在data文件夹中,按照label_id.jpg进行命名,例如2_111.jpg代表图片类别为2(鸟),id为111。

3.代码及其注释:
(1)导入需要的库
(2)数据读取:

(3)定义placeholder(容器)
除了图像数据和Label,Dropout率也要放在placeholder中,因为在训练阶段和测试阶段需要设置不同的Dropout率

(4)定义卷积层:

(5)定义全连接层:
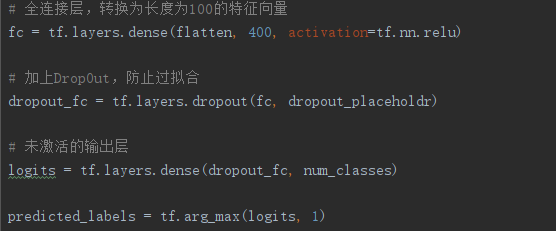
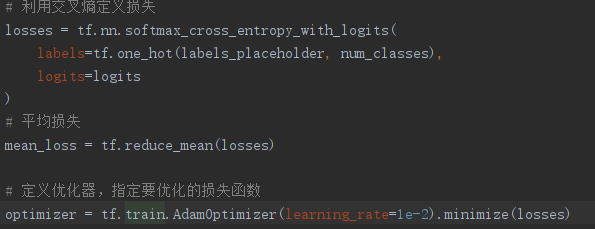
(5)定义损失函数和优化器:
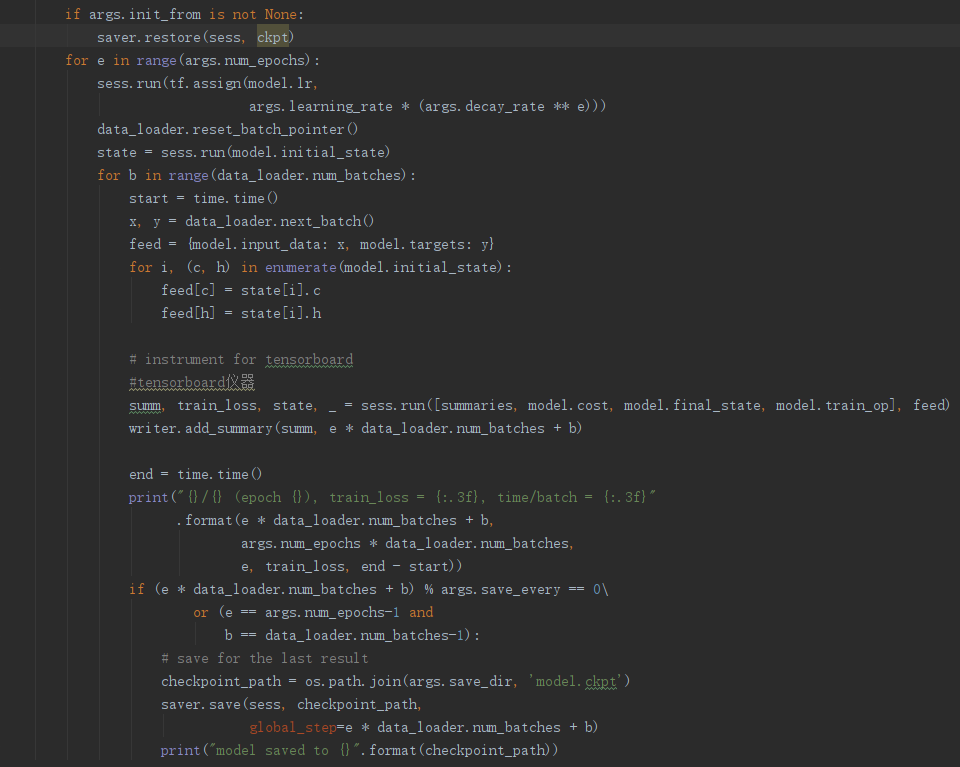
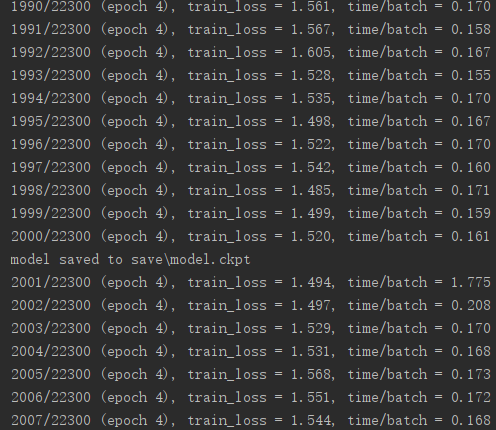
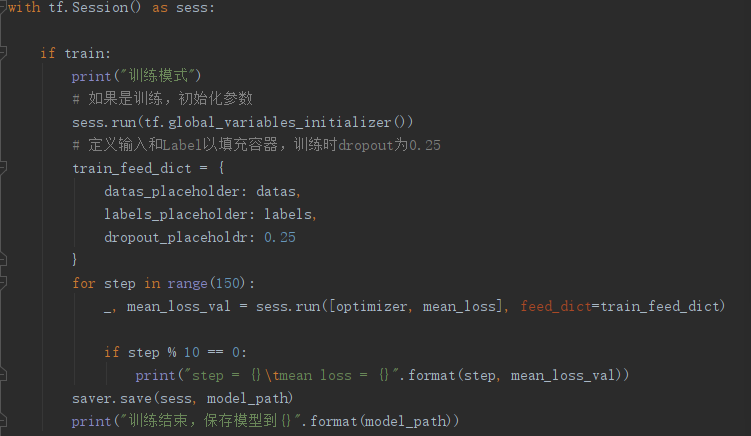
(6)训练:
(7)测试:

(8)结果: