【性能相关及深度优先与广度优先】
性能相关
在编写爬虫时,性能的消耗主要在IO请求中,当单进程单线程模式下请求URL时必然会引起等待,从而使得请求整体变慢。


import requests def fetch_async(url): response = requests.get(url) return response url_list = ['http://www.github.com', 'http://www.bing.com'] for url in url_list: fetch_async(url)
from concurrent.futures import ThreadPoolExecutor import requests def fetch_async(url): response = requests.get(url) return response url_list = ['http://www.github.com', 'http://www.bing.com'] pool = ThreadPoolExecutor(5) for url in url_list: pool.submit(fetch_async, url) pool.shutdown(wait=True)
from concurrent.futures import ThreadPoolExecutor import requests def fetch_async(url): response = requests.get(url) return response def callback(future): print(future.result()) url_list = ['http://www.github.com', 'http://www.bing.com'] pool = ThreadPoolExecutor(5) for url in url_list: v = pool.submit(fetch_async, url) v.add_done_callback(callback) pool.shutdown(wait=True)
from concurrent.futures import ProcessPoolExecutor import requests def fetch_async(url): response = requests.get(url) return response url_list = ['http://www.github.com', 'http://www.bing.com'] pool = ProcessPoolExecutor(5) for url in url_list: pool.submit(fetch_async, url) pool.shutdown(wait=True)
from concurrent.futures import ProcessPoolExecutor import requests def fetch_async(url): response = requests.get(url) return response def callback(future): print(future.result()) url_list = ['http://www.github.com', 'http://www.bing.com'] pool = ProcessPoolExecutor(5) for url in url_list: v = pool.submit(fetch_async, url) v.add_done_callback(callback) pool.shutdown(wait=True)
通过上述代码均可以完成对请求性能的提高,对于多线程和多进行的缺点是在IO阻塞时会造成了线程和进程的浪费,所以异步IO回事首选:
import asyncio @asyncio.coroutine def func1(): print('before...func1......') yield from asyncio.sleep(5) print('end...func1......') tasks = [func1(), func1()] loop = asyncio.get_event_loop() loop.run_until_complete(asyncio.gather(*tasks)) loop.close()
import asyncio @asyncio.coroutine def fetch_async(host, url='/'): print(host, url) reader, writer = yield from asyncio.open_connection(host, 80) request_header_content = """GET %s HTTP/1.0 Host: %s """ % (url, host,) request_header_content = bytes(request_header_content, encoding='utf-8') writer.write(request_header_content) yield from writer.drain() text = yield from reader.read() print(host, url, text) writer.close() tasks = [ fetch_async('www.cnblogs.com', '/wupeiqi/'), fetch_async('dig.chouti.com', '/pic/show?nid=4073644713430508&lid=10273091') ] loop = asyncio.get_event_loop() results = loop.run_until_complete(asyncio.gather(*tasks)) loop.close()
import aiohttp import asyncio @asyncio.coroutine def fetch_async(url): print(url) response = yield from aiohttp.request('GET', url) # data = yield from response.read() # print(url, data) print(url, response) response.close() tasks = [fetch_async('http://www.google.com/'), fetch_async('http://www.chouti.com/')] event_loop = asyncio.get_event_loop() results = event_loop.run_until_complete(asyncio.gather(*tasks)) event_loop.close()
import asyncio import requests @asyncio.coroutine def fetch_async(func, *args): loop = asyncio.get_event_loop() future = loop.run_in_executor(None, func, *args) response = yield from future print(response.url, response.content) tasks = [ fetch_async(requests.get, 'http://www.cnblogs.com/wupeiqi/'), fetch_async(requests.get, 'http://dig.chouti.com/pic/show?nid=4073644713430508&lid=10273091') ] loop = asyncio.get_event_loop() results = loop.run_until_complete(asyncio.gather(*tasks)) loop.close()
import gevent import requests from gevent import monkey monkey.patch_all() def fetch_async(method, url, req_kwargs): print(method, url, req_kwargs) response = requests.request(method=method, url=url, **req_kwargs) print(response.url, response.content) # ##### 发送请求 ##### gevent.joinall([ gevent.spawn(fetch_async, method='get', url='https://www.python.org/', req_kwargs={}), gevent.spawn(fetch_async, method='get', url='https://www.yahoo.com/', req_kwargs={}), gevent.spawn(fetch_async, method='get', url='https://github.com/', req_kwargs={}), ]) # ##### 发送请求(协程池控制最大协程数量) ##### # from gevent.pool import Pool # pool = Pool(None) # gevent.joinall([ # pool.spawn(fetch_async, method='get', url='https://www.python.org/', req_kwargs={}), # pool.spawn(fetch_async, method='get', url='https://www.yahoo.com/', req_kwargs={}), # pool.spawn(fetch_async, method='get', url='https://www.github.com/', req_kwargs={}), # ])
import grequests request_list = [ grequests.get('http://httpbin.org/delay/1', timeout=0.001), grequests.get('http://fakedomain/'), grequests.get('http://httpbin.org/status/500') ] # ##### 执行并获取响应列表 ##### # response_list = grequests.map(request_list) # print(response_list) # ##### 执行并获取响应列表(处理异常) ##### # def exception_handler(request, exception): # print(request,exception) # print("Request failed") # response_list = grequests.map(request_list, exception_handler=exception_handler) # print(response_list)
from twisted.web.client import getPage, defer from twisted.internet import reactor def all_done(arg): reactor.stop() def callback(contents): print(contents) deferred_list = [] url_list = ['http://www.bing.com', 'http://www.baidu.com', ] for url in url_list: deferred = getPage(bytes(url, encoding='utf8')) deferred.addCallback(callback) deferred_list.append(deferred) dlist = defer.DeferredList(deferred_list) dlist.addBoth(all_done) reactor.run()
from tornado.httpclient import AsyncHTTPClient from tornado.httpclient import HTTPRequest from tornado import ioloop def handle_response(response): """ 处理返回值内容(需要维护计数器,来停止IO循环),调用 ioloop.IOLoop.current().stop() :param response: :return: """ if response.error: print("Error:", response.error) else: print(response.body) def func(): url_list = [ 'http://www.baidu.com', 'http://www.bing.com', ] for url in url_list: print(url) http_client = AsyncHTTPClient() http_client.fetch(HTTPRequest(url), handle_response) ioloop.IOLoop.current().add_callback(func) ioloop.IOLoop.current().start()
from twisted.internet import reactor from twisted.web.client import getPage import urllib.parse def one_done(arg): print(arg) reactor.stop() post_data = urllib.parse.urlencode({'check_data': 'adf'}) post_data = bytes(post_data, encoding='utf8') headers = {b'Content-Type': b'application/x-www-form-urlencoded'} response = getPage(bytes('http://dig.chouti.com/login', encoding='utf8'), method=bytes('POST', encoding='utf8'), postdata=post_data, cookies={}, headers=headers) response.addBoth(one_done) reactor.run()
深度优先与广度优先
在爬虫系统中,待抓取URL队列是很重要的一部分,待抓取URL队列中的URL以什么样的顺序排队列也是一个很重要的问题,因为这涉及到先抓取哪个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。下面是常用的两种策略:深度优先、广度优先。
深度优先
深度优先 顾名思义就是 让 网络蜘蛛 尽量的在抓取网页时 往网页更深层次的挖掘进去 讲究的是深度!也泛指: 网络蜘蛛将会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接!
深度优先搜索是一种在开发爬虫早期使用较多的方法。它的目的是要达到被搜索结构的叶结点(即那些不包含任何超链的HTML文件) 。在一个HTML文件中,当一个超链被选择后,被链接的HTML文件将执行深度优先搜索,即在搜索其余的超链结果之前必须先完整地搜索单独的一条链。深度优先搜索沿着HTML文件上的超链走到不能再深入为止,然后返回到某一个HTML文件,再继续选择该HTML文件中的其他超链。当不再有其他超链可选择时,说明搜索已经结束。优点是能遍历一个Web 站点或深层嵌套的文档集合;缺点是因为Web结构相当深,,有可能造成一旦进去,再也出不来的情况发生。
如图所示:下面这张是 简单化的网页连接模型图 其中A为起点 也就是蜘蛛索引的起点!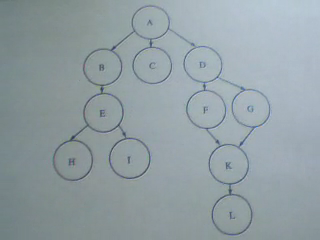
总共分了5条路径 供蜘蛛爬行! 讲究的是深度!
(下面这张是 经过优化的网页连接模型图! 也就是改进过的蜘蛛深度爬行策略图!)
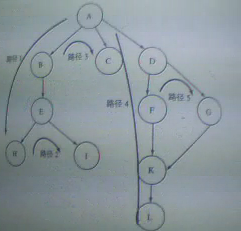
根据以上2个表格 我们可以得出以下结论:
图1:
路径1 ==> A --> B --> E --> H
路径2 ==> A --> B --> E --> i
路径3 ==> A --> C
路径4 ==> A --> D --> F --> K --> L
路径5 ==> A --> D --> G --> K --> L
经过优化后
图2: (图片已经帮大家标上方向了!)
路径1 ==> A --> B --> E --> H
路径2 ==> i
路径3 ==> C
路径4 ==> D --> F --> K --> L
路径5 ==> G
广度优先
整个的广度优先爬虫过程就是从一系列的种子节点开始,把这些网页中的"子节点"(也就是超链接)提取出来,放入队列中依次进行抓取。被处理过的链接需要放 入一张表(通常称为Visited表)中。每次新处理一个链接之前,需要查看这个链接是否已经存在于Visited表中。如果存在,证明链接已经处理过, 跳过,不做处理,否则进行下一步处理。
初始的URL地址是爬虫系统中提供的种子URL(一般在系统的配置文件中指定)。当解析这些种子URL所表示的网页时,会产生新的URL(比如从页面中的<a href= "http://www.cnblogs.com "中提取出http://www.cnblogs.com 这个链接)。然后,进行以下工作:
把解析出的链接和Visited表中的链接进行比较,若Visited表中不存在此链接,表示其未被访问过。
把链接放入TODO表中。
处理完毕后,再次从TODO表中取得一条链接,直接放入Visited表中。
针对这个链接所表示的网页,继续上述过程。如此循环往复。
广度优先遍历是爬虫中使用最广泛的一种爬虫策略,之所以使用广度优先搜索策略,主要原因有三点:
重要的网页往往离种子比较近,例如我们打开新闻网站的时候往往是最热门的新闻,随着不断的深入冲浪,所看到的网页的重要性越来越低。
万维网的实际深度最多能达到17层,但到达某个网页总存在一条很短的路径。而广度优先遍历会以最快的速度到达这个网页。
广度优先有利于多爬虫的合作抓取,多爬虫合作通常先抓取站内链接,抓取的封闭性很强。
广度相对深度对数据抓取更容易控制些! 对服务器的负栽相应也明显减轻了许多! 爬虫的分布式处理使速度明显提高!
广度优先策略图(层爬行图)
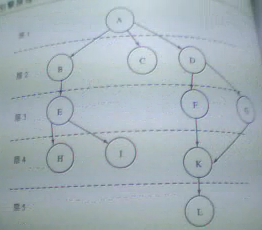
根据以上表格 我们可以得出以下结论路径图:
路径1 ==> A
路径2 ==> B --> C --> D
路径3 ==> E --> F --> G
路径4 ==> H --> i --> K
路径5 ==> L
总结如下:
深度优先搜索策略
容易一根筋走到底,最后出不来。
广度优先搜索策略
广度优先搜索策略是指在抓取过程中,在完成当前层次的搜索后,才进行下一层次的搜索。该算法的设计和实现相对简单。在目前为覆盖尽可能多的网页,一般使用广度优先搜索方法。也有很多研究将广度优先搜索策略应用于聚焦爬虫中。其基本思想是认为与初始URL在一定链接距离内的网页具有主题相关性的概率很大。另外一种方法是将广度优先搜索与网页过滤技术结合使用,先用广度优先策略抓取网页,再将其中无关的网页过滤掉。这些方法的缺点在于,随着抓取网页的增多,大量的无关网页将被下载并过滤,算法的效率将变低。
最佳优先搜索策略
最佳优先搜索策略按照一定的网页分析算法,预测候选URL与目标网页的相似度,或与主题的相关性,并选取评价最好的一个或几个URL进行抓取。它只访问经过网页分析算法预测为“有用”的网页。存在的一个问题是,在爬虫抓取路径上的很多相关网页可能被忽略,因为最佳优先策略是一种局部最优搜索算法。 因此需要将最佳优先结合具体的应用进行改进,以跳出局部最优点。将在第4节中结合网页分析算法作具体的讨论。研究表明,这样的闭环调整可以将无关网页数量降低30%~90%。