show databases; //显示所有数据库 create database my; //创建my数据库 drop database my; //删除my数据库 create table book( id int primary key auto_increment, bookName varchar(20), bookDesc varchar(200) ); //创建book表 drop table book; //删除book表 create table t_book( id int primary key auto_increment, bookName varchar(20), author varchar(10), price decimal(6,2), bookTypeId int, constraint `fk` foreign key(`bookTypeId`) references `t_bookType`(`id`) ); //建立有外键约束的表 show tables; //显示当前数据库的所有表 desc t_bookType; //查看t_bookType表结构 desc t_bookType; //查看t_bookType表结构 alter table t_book rename book; //修改表名 alter table t_book change id book_id int; //修改t_book表的id字段名为book_id,数据类型为 int alter table t_book drop author ; //删除字段名 alter table t_book add author varchar(10); //增加字段名 insert into t_student (id,stuName,age,sex,gradeName) values (4,'zhangxiao ',12,'nan','sannianji'),(5,'zhangxia',13,'nan','sannianj'),(6,'xiaobai',9,'nan', 'sannianji'); //插入多条数据(在mysql中才试用) select * from t_student where id=3; //where过滤指定数据 delete from t_student where id=4; //删除数据 select * from t_student where id in (1,3); //in查询id为1和id为3的数据 select * from t_student where id between 1 and 3; // id范围是[1,3] select * from t_student where stuName like 'zhan'; // 相当于等于号 select * from t_student where stuName like 'zhang%'; //%为占位符,说明可以代替一切字符 select * from t_student where stuName like 'zhang___'; //下划线为一个字符的占位符 select * from t_student where age is null; //空值查询 select * from t_student where age=23 and sex='nv'; //and 多次过滤 select * from t_student where age=23 and sex='nv'; // 多种选择(都可以) select distinct age from t_student; //去重复查询 select * from t_student order by age; //结果按某一字段排序 select sex,group_concat(stuName) from t_student group by sex ; //分组查询 select sex,count(stuName) from t_student group by sex ; //分组查询 select sex,count(stuName) from t_student group by sex having count(stuN ame) >1; // 分组查询 select sex, count(sex) from t_student group by sex with rollup; //分组查询,统计总数 select sex,group_concat(stuName) from t_student group by sex with rollup; //分组查询,统计叠加 select * from t_student limit 3,2; //分页查询,想象数据放入数组中,3是数组的下标,即从第四条记录开始,2是总共需要的记录数 select count(age) from t_student; //count函数的使用 select count(*) from t_student; //count函数的使用 select * from t_book,t_bookType where bookTypeId=t_booktype.id; //内链接 select * from t_book left join t_booktype on bookTypeId=t_booktype.id; //外链接(左连接) select * from t_book right join t_booktype on bookTypeId=t_booktype.id;//外链接(右连接) select * from t_book where booktypeid in (select id from t_booktype where booktypename='文学类'); //子查询 select * from t_book where booktypeid > (select id from t_booktype where booktypename='文学类'); //子查询(这个符号对应的只能是一个数,不能是一个集合) select * from t_book where exists (select id from t_booktype where booktypename='类'); //子查询(若为真,查询到记录,就进行外层查询) select * from t_book where booktypeid >=any (select id from t_booktype); //子查询(只要存在一个就行) select * from t_book where booktypeid >all (select id from t_booktype);//子查询(所有的条件都必须满足) select id from t_book union select id from t_booktype; //合并查询(字段的数据类型需要对应,不包含重复的) select id from t_book union all select id from t_booktype; //合并查询(包括重复数据) select * from t_book t ; //给 t_book表取别名为t select bookName name from t_book; //给字段名取别名 update t_book set bookName='数学' where id=1;//更新数据 delete from t_book where id=1; //删除数据
create table t_myindex (id int, name varchar(20), password varchar(20), index (name) ); //创建普通索引 create table t_myindex1 (id int, name varchar(20), password varchar(20), unique index (name) ); //创建唯一性索引 create table t_myindex2(id int, name varchar(20), password varchar(20), unique index myindex (name) ); //给索引创建别名myindex create table t_myindex3(id int, name varchar(20), password varchar(20), unique index myindex (name,password) ); //多列索引 create index myindex2 on t_myindex1(password); //在已经创建好的表上建立索引 create unique index myindex2 on t_myindex1(password); //在已经创建好的表上创建唯一性索引 alter table t_myindex3 add index myindex4(name); // alter语句增加索引 drop index myindex4 on t_myindex3; //删除t_myindex3表上的索引myindex4
create view v1 as select * from t_book; //创建视图 desc v1; //查看视图结构 show table status like 'v1';//查看视图状态 show create view v1; //查看视图建立的语句信息 create or replace view v1 as select bookName from t_book; //修改视图 alter view v1 as select * from t_book; //修改视图 insert into v1 values (null,'java',12,'f',1); // 插入视图的数据(在权限范围内,相应数据会被真正执行) update v1 set bookName='java' where id=2;//更新视图数据 delete from v1 where id=2; //删除视图数据 drop view if exists v4; //删除视图
create trigger t1 after insert on t_book for each row update t_b00ktype set booknum=booknum+1 where new.booktypeid=t_booktype.id; //创建触发器 create trigger t1 after insert on t_book for each row begin 。。。 end;//创建多条触发语句的触发器 show triggers; //查看触发器 drop trigger t1; //删除触发器
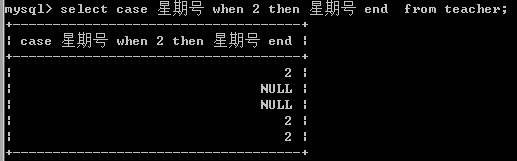
case ++when++ then++ else++ end
最初表结构
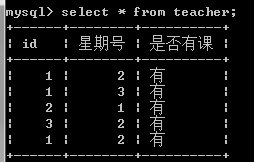
试一下用法
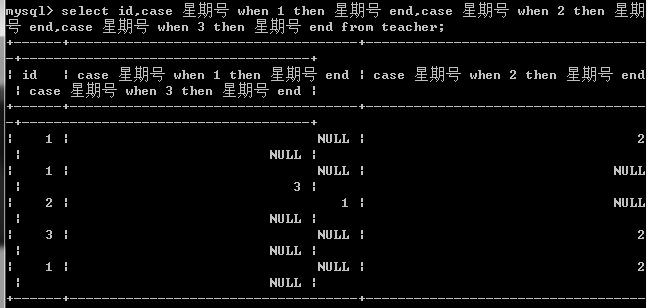
三个一起写
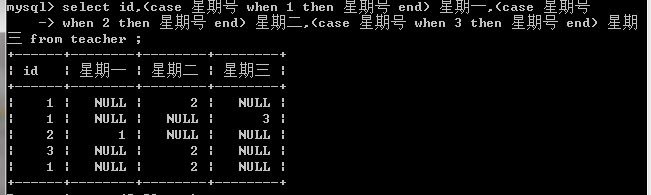
简化
分组

书表(books)
book_id,book_name,creatdate,Lastmodifydate,decription
001,三个人的世界,2005-02-02,2005-07-07,NULL
作者表(authors)
A_id,A_name
01,王纷
02,李尚
03,泰和
部门表(depts)
d_id,d_name
001,编辑一部
002,编辑二部
003,编辑三部
书和作者关联表(bookmap)
book_id,A_id
001,01
001,02
001,03
部门和作者关联表(depmap)
d_id,a_id
001,01
002,02
003,03
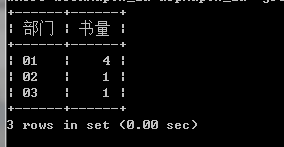
找出每个部门的所写的总书两,比如,一本书有3个人写,如果三个人在不同的部门,则每个部门的总数量就是1.最后结果如下:
部门,书量
编辑一部,1
编辑二部,1
编辑三部,1
- --书表(books)
- create table books
- (
- book_id varchar(10) primary key,
- book_name varchar(30),
- creatdate date,
- Lastmodifydate date,
- decription varchar(500)
- );
- insert into books (book_id,book_name,creatdate,Lastmodifydate) values('001','一个人的天空','1-4月-2005','29-7月-2005');
- insert into books (book_id,book_name,creatdate,Lastmodifydate) values('002','两个人的小窝','1-12月-2001','11-4月-2002');
- insert into books (book_id,book_name,creatdate,Lastmodifydate) values('003','三个人的世界','1-4月-2005','29-7月-2005');
- insert into books (book_id,book_name,creatdate,Lastmodifydate) values('004','四个人的大地','1-12月-2001','11-4月-2002');
- insert into books (book_id,book_name,creatdate,Lastmodifydate) values('005','五个人的未来','1-4月-2005','29-7月-2005');
- --作者表(authors)
- create table authors
- (
- A_id varchar(4) primary key,
- A_name varchar(20)
- );
- insert into authors values('01','张三');
- insert into authors values('02','李四');
- insert into authors values('03','王五');
- insert into authors values('04','马六');
- --部门表(depts)
- create table depts
- (
- d_id varchar(4) primary key,
- d_name varchar(20)
- );
- insert into depts values('01','编辑一部');
- insert into depts values('02','编辑二部');
- insert into depts values('03','编辑三部');
- insert into depts values('04','编辑四部');
- --书和作者关联表(bookmap)
- create table bookmap
- (
- book_id varchar(10),
- A_id varchar(4)
- );
- insert into bookmap values('001','01');
- insert into bookmap values('002','01');
- insert into bookmap values('003','01');
- insert into bookmap values('004','01');
- insert into bookmap values('004','02');
- insert into bookmap values('005','03');
- --部门和作者关联表(depmap)
- create table depmap
- (
- d_id varchar(4),
- A_id varchar(4)
- );
- insert into depmap values('01','01');
- insert into depmap values('02','02');
- insert into depmap values('02','04');
- insert into depmap values('03','03');
select d_id 部门 ,COUNT(bookmap.book_id) 书量 from bookmap , depmap where bookmap.A_id=depmap.A_id group by depmap.d_id ;
题目:
两个表情况
表名:wu_plan
ID plan model corp_code plannum prixis
1 00001 exx22 nokia 2000 0
2 00002 lc001 sony 3000 0
表名:wu_bom
ID plan pact amount
1 00001 aa1 300
2 00001 aa2 200
3 00002 bb1 500
4 00002 bb2 800
5 00002 bb3 400
查询这两个表中plan唯一,每一个plan中,amount最少的,plannum大于prixis的记录
结果是:
ID plan model corp_code plannum prixis pact amount
1 00001 exx22 nokia 2000 0 a2 200
2 00002 lc001 sony 3000 0 bb3 400
select wu_plan.ID , min(amount) from wu_plan,wu_bom where wu_plan.plan=
u_bom.plan, plannum>prixis group by wu_plan.plan;
题目:
表1结构如下:
部门 条码 品名 销售额 销售数量 销售日期
表2结构如下
课别 部门
要求:先按部门排序,再按销售额、销售数量排序检索出某个课别每个部门一个时期内的商品销售额的前三名,如查询01课别2007年4月15日到2007年4月22日每个部门一个周内的商品销售额合计的前三名
第一,如果多次排序
order by后面跟着几个就ok
第二,如果分组之后选取前三名数值最大值
用having将分组排序好的取前三个
select group_concat(biao1.销售额)from biao1,biao2 where biao1.部门=biao2.部门 and 课别=1 group by biao1.部门 order by 部门,销售额,销售数量 having count(*) <4;
大概就是这个样子,时间在where后面加上就ok