饿了么外卖网站是一个ajax动态加载的网站
Version1:直接页面提取
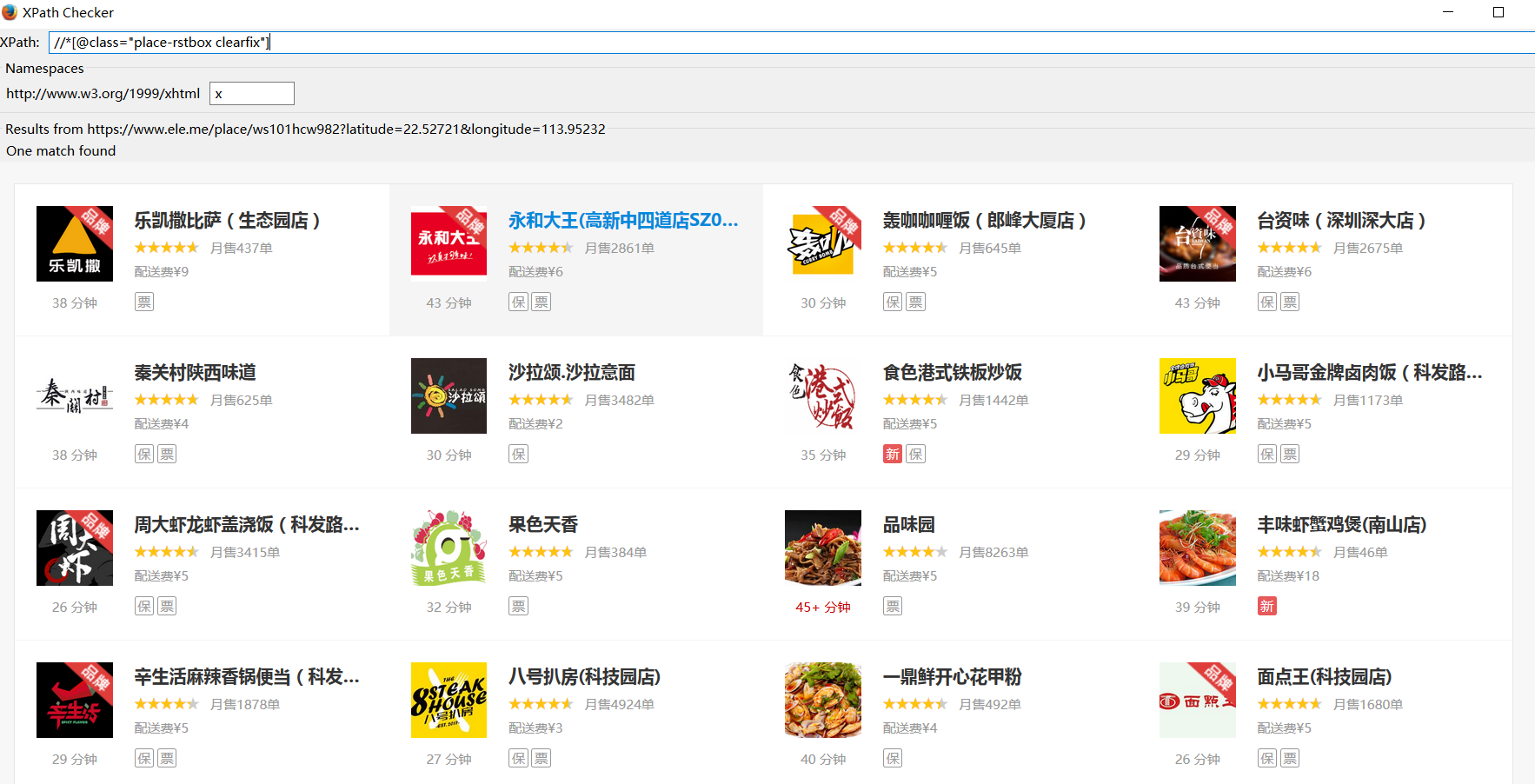
from lxml import etree import requests import sys import time reload(sys) sys.setdefaultencoding('utf-8') url = 'https://www.ele.me/place/ws101hcw982?latitude=22.52721&longitude=113.95232' response = requests.get(url) print response.status_code time.sleep(10) html = response.content selector = etree.HTML(html) rez = selector.xpath('//*[@class="place-rstbox clearfix"]') print 'haha',rez #[] for i in rez: Name = i.xpath('//*[@class="rstblock-title"]/text()') print name msales = i.xpath('//*[@class="rstblock-monthsales"]/text()') tip = i.xpath('//*[@class="rstblock-cost"]/text()') stime = i.xpath('//*[@class="rstblock-logo"]/span/text()') print u'店名' for j in Name: print j break
问题:根据//*[@class="place-rstbox clearfix"]xpath提取成功,但是rez输出为空
Version2:通过接口提取
geohash=ws101hcw982&latitude=22.52721&longitude=113.95232:位置信息参数及参数值
terminal=web:渠道信息
extras[]=activities和offset=0未知
import requests import json url = 'https://www.ele.me/restapi/shopping/restaurants?extras[]=activities&geohash=ws101hcw982&latitude=22.52721&limit=30&longitude=113.95232&offset=0&terminal=web' resp = requests.get(url) print resp.status_code Jdata = json.loads(resp.text) #print Jdata for n in Jdata: name = n['name'] msales = n['recent_order_num'] stime = n['order_lead_time'] tip = n['description'] phone = n['phone'] print name
输出:原以为通过limit=100就可以提取100条商家信息,然而最多只显示30

Version3:通过selenium提取
from selenium import webdriver import selenium.webdriver.support.ui as ui import time driver = webdriver.PhantomJS(executable_path=r"C:Python27phantomjs.exe") #driver = webdriver.Chrome() driver.get('https://www.ele.me/place/ws101hcw982?latitude=22.52721&longitude=113.95232') time.sleep(10) driver.get_screenshot_as_file("E:\Elm_ok.jpg") wait = ui.WebDriverWait(driver,10) wait.until(lambda driver: driver.find_element_by_xpath('//div[@class="place-rstbox clearfix"]')) name = driver.find_element_by_xpath('//*[@class="rstblock-title"]').text msales = driver.find_element_by_xpath('//*[@class="rstblock-monthsales"]').text tip = driver.find_element_by_xpath('//*[@class="rstblock-cost"]').text stime = driver.find_element_by_xpath('//*[@class="rstblock-logo"]/span').text print name #乐凯撒比萨(生态园店)
注:find_element只提取一个
改进版
#coding=utf-8 from selenium import webdriver import selenium.webdriver.support.ui as ui import time driver = webdriver.PhantomJS(executable_path=r"C:Python27phantomjs.exe") #driver = webdriver.Chrome() driver.get('https://www.ele.me/place/ws101hcw982?latitude=22.52721&longitude=113.95232') time.sleep(10) #driver.get_screenshot_as_file("E:\Elm_ok.jpg") wait = ui.WebDriverWait(driver,10) wait.until(lambda driver: driver.find_element_by_xpath('//div[@class="place-rstbox clearfix"]')) #driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") #滚动至底部页面 def execute_times(times): for i in range(times + 1): driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") time.sleep(5) execute_times(20) name = driver.find_elements_by_xpath('//*[@class="rstblock-title"]') msales = driver.find_elements_by_xpath('//*[@class="rstblock-monthsales"]') tip = driver.find_elements_by_xpath('//*[@class="rstblock-cost"]') stime = driver.find_elements_by_xpath('//*[@class="rstblock-logo"]/span') #print name,msales,stime,tip #[<selenium.webdriver.remote.webelement.WebElement (session="c941cfb0-a428-11e7-affa-f38716880ab3",...] print type(tip) #<type 'list'> print len(name) #120 for i in name: print i.text
说明:通过execute_times函数,滚动条每下移一次,休息5s,从而使页面加载更多的商家信息
输出:
